ooenvino的安装可参考openvino2022版安装配置与C++SDK开发详解
1.什么是openvino?
概念:
OpenVINO是英特尔基于自身现有的硬件平台开发的一种可以加快高性能计算机视觉和深度学习视觉应用开发速度工具套件,支持各种英特尔平台的硬件加速器上进行深度学习,并且允许直接异构执行。 支持在Windows与Linux系统,Python/C++语言。
特点:
- 在Intel平台上提升计算机视觉相关深度学习性能达19倍以上
- 主要是为了提高模型在CPU、GPU的运行速度
- 解除CNN-based的网络在边缘设备的性能瓶颈
支持的平台:
支持的操作系统:windows、linux、mac os
支持的硬件:凌动、酷睿、至强、FPGA等
2.openvino的组件
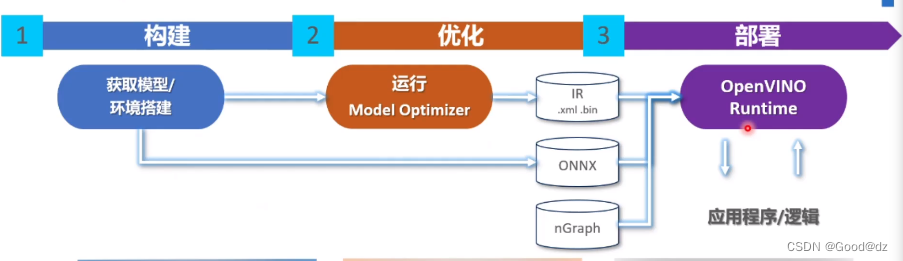
openvino有三条路可以走,例如tensorflow的就要走第一条路(经过Model Optimizer);pytorch可以走第二条路,直接转换成onnx;第三条路,可以是paddle。
OpenVINO工具包(ToolKit)主要包括两个核心组件,模型优化器(Model Optimizer)和推断引擎(Inference Engine)。
模型优化器(Model Optimizer)
模型优化器(Model Optimizer)将给定的模型转化为标准的 Intermediate Representation (IR) ,并对模型优化。
模型优化器支持的深度学习框架:ONNX、TensorFlow、pytorch等
推理引擎(Inference Engine)
推理引擎(Inference Engine)支持硬件指令集层面的深度学习模型加速运行,同时对传统的OpenCV图像处理库也进行了指令集优化,有显著的性能与速度提升。
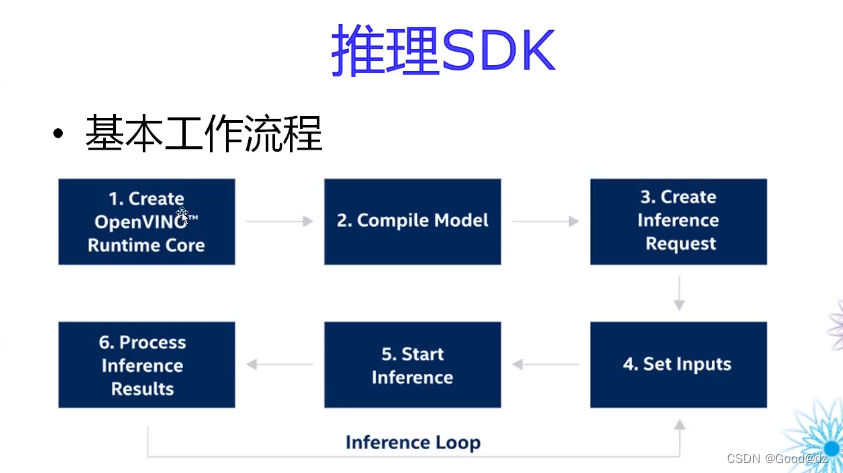
3.推理流程
4.代码实现
4.1生成图像分类的onnx
import torch
import torchvision
import cv2
import numpy as np
class Classifier(torch.nn.Module):
def __init__(self):
super().__init__()
#使用torchvision自带的与训练模型, 更多模型请参考:https://tensorvision.readthedocs.io/en/master/
self.backbone = torchvision.models.resnet18(pretrained=True)
def forward(self, x):
feature = self.backbone(x)
probability = torch.softmax(feature, dim=1)
return probability
# 对每个通道进行归一化有助于模型的训练
imagenet_mean = [0.485, 0.456, 0.406]
imagenet_std = [0.229, 0.224, 0.225]
image = cv2.imread("workspace/dog.jpg")
image = cv2.resize(image, (224, 224)) # resize
image = image[..., ::-1] # BGR -> RGB
image = image / 255.0
image = (image - imagenet_mean) / imagenet_std # normalize
image = image.astype(np.float32) # float64 -> float32
image = image.transpose(2, 0, 1) # HWC -> CHW
image = np.ascontiguousarray(image) # contiguous array memory
image = image[None, ...] # CHW -> 1CHW
image = torch.from_numpy(image) # numpy -> torch
model = Classifier().eval()
with torch.no_grad():
probability = model(image)
predict_class = probability.argmax(dim=1).item()
confidence = probability[0, predict_class]
labels = open("workspace/labels.imagenet.txt").readlines()
labels = [item.strip() for item in labels]
print(f"Predict: {predict_class}, {confidence}, {labels[predict_class]}")
dummy = torch.zeros(1, 3, 224, 224)
torch.onnx.export(
model, (dummy,), "workspace/classifier.onnx",
input_names=["image"],
output_names=["prob"],
dynamic_axes={"image": {0: "batch"}, "prob": {0: "batch"}},
opset_version=11
)
4.2 模型优化器
安装python的openvino
pip install openvino-dev[onnx]==2022.1.0
执行模型优化器
mo --input_model classifier.onnx --data_type FP16
会生成多个文件,在推理时用的是后缀为.xml的文件
4.3 c++推理代码实现
在makefile中添加如下
# 只需要写路径,不需要写-I
include_paths := src \
$(cpp_pkg)/opencv4.2/include \
$(openvino_root)/runtime/include \ # 添加openvino的头文件地址1
$(openvino_root)/runtime/include/ie # 添加openvino的头文件地址2
# 定义库文件路径,只需要写路径,不需要写-L
library_paths := $(syslib) $(cpp_pkg)/opencv4.2/lib \
$(openvino_root)/runtime/lib/intel64 \ # 添加openvino的库文件地址1
$(openvino_root)/runtime/3rdparty/tbb/lib # 添加openvino的库文件地址2
link_openvino := openvino tbb # tbb:英特尔提供的cpu推理加速库
link_librarys := $(link_cuda) $(link_tensorRT) $(link_sys) $(link_opencv) $(link_openvino) # 添加$(link_openvino)
配置完成后,即可使用openvino
编写如下代码
#include <stdio.h>
#include <math.h>
#include <iostream>
#include <fstream>
#include <vector>
#include <memory>
#include <functional>
#include <unistd.h>
#include "openvino/openvino.hpp"
#include <opencv2/opencv.hpp>
void openvino_classifer()
{
size_t input_batch_size = 1; // size_t是c和c++标准在stddef.h中定义的,这个类型用于表示对象的大小,其真实类型与操作系统有关
// 在32位架构中被普遍定义为:typedef unsigned int size_t;
size_t input_channel_size = 3; // 而在64位架构中被定义为: typedef unsigned long size_t;
size_t input_height_size = 224;
size_t input_width_size = 224;
ov::Core core; // core是interference Engine的管理核心,一般使用openvino之前都需要先创建一个core,负责其中的设备管理
auto model = core.compile_model("classifier.onnx"); // 模型加载并编译
auto iq = model.create_infer_request(); // 创建用于推断已编译模型的推理请求对象 创建的请求分配了输入和输出张量
auto input = iq.get_input_tensor(0);
auto output = iq.get_output_tensor(0);
input.set_shape({input_batch_size, input_channel_size, input_height_size, input_height_size}); // 指定shape的大小
float* input_data_host = input.data<float>(); // 获取输入的地址,并传递给指针input_data_host
clock_t startTime,endTime;
startTime = clock();
auto image = cv::imread("dog.jpg");
float mean[] = {0.406, 0.456, 0.485};
float std[] = {0.225, 0.224, 0.229};
// 对应于pytorch的代码部分
cv::resize(image, image, cv::Size(input_width_size, input_height_size));
int image_area = image.cols * image.rows;
unsigned char* pimage = image.data;
float* phost_b = input_data_host + image_area * 0; // input_data_host和phost_*进行地址关联
float* phost_g = input_data_host + image_area * 1;
float* phost_r = input_data_host + image_area * 2;
for(int i = 0; i < image_area; ++i, pimage += 3){
// 注意这里的顺序rgb调换了
*phost_r++ = (pimage[0] / 255.0f - mean[0]) / std[0]; // 将图片中的像素点进行减去均值除方差,并赋值给input
*phost_g++ = (pimage[1] / 255.0f - mean[1]) / std[1];
*phost_b++ = (pimage[2] / 255.0f - mean[2]) / std[2];
}
iq.infer(); // 模型推理
const int num_classes = 1000;
float* prob = output.data<float>();
int predict_label = std::max_element(prob, prob + num_classes) - prob; // 确定预测类别的下标
float confidence = prob[predict_label]; // 获得预测值的置信度
printf("confidence = %f, label = %d\n", confidence, predict_label);
endTime = clock();//计时结束
std::cout << "total推理时间: " <<(double)(endTime - startTime) / CLOCKS_PER_SEC << "s" << std::endl;
}
int main(){
openvino_classifer();
return 0;
}
版权声明:本文为qq_42178122原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。