【得物技术部】商品中心:流量之战—性能优化三十六计
- 引言

每年的双十一、618这些购物狂欢节,对于消费者来说是购物的黄金日,是解放双手买买买的疯狂节奏。但是对于程序员(媛)们来说,这确是一个心惊胆战、养蓄已久的秀发又开始日渐凋零的备考日,其中辛酸不言而喻。试想一下,你如果面临着这样一个现状:你的服务作为交易流量的一级入口、你的核心接口需要对接依赖着十几个下游的服务错综复杂、你需要给客户端返回丰富多样的渲染数据、而此时你的核心接口单机压测的结果确远远不达标。默数着心中618的倒计时,承载着即将到来的几亿用户的热情,你如何在决战来临之前顺利的优化你的服务性能呢?那么,下面就来看看商品在这场流量对抗之战中的性能优化三十六计。
2.优化策略
2.1 八仙过海, 并驾齐驱

从商品的业务角度来说,我们总是希望尽可能的展示给用户更丰富的、更精准的商品数据。让用户可以全面的了解商品的信息,增加用户的决策度。尤其是这些数据需要不同的业务域来支撑的时候,一个商品页面的展示就往往包含多个业务域接口的请求,根据业务逻辑的不同,这些接口的响应时间也各不相同。在过去,我们使用串行的方式来调用这些接口,如下图所示。
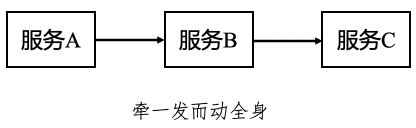
这就会发生一个问题,一旦某个下游依赖接口响应时间过长或者发生异常,就会导致整体耗时大幅增加,可谓“城门失火,殃及池鱼”。那么该如何进行优化?事实上,多线程异步的处理思想早就给我们提供了方法。
考虑到JDK1.8中引入的强大的异步编程ApiCompletableFuture,我们将这种多个服务的调用从同步变更为异步,变更后示意图如下:
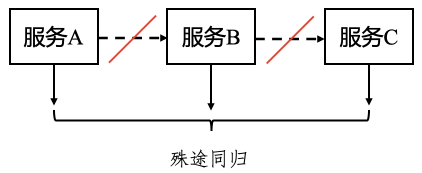
可以看到,变更后不同服务之间没有了直接的上下依赖,而是等待各自完成对应的响应后,再进行整体的业务聚合,这使得整体调用耗时得到了优化,由Time.add(a, b, c)变为Time.max(a, b, c)。这里举一个具体的例子:比如我们获取用户信息及登陆态校验的地方均通过注解的方式实现,本质基于Spring AOP。这就导致接口调用必须等待信息验证完毕,才会走到下游的业务逻辑处理中,增加了整体的响应时间。可是对于有些业务场景来说,用户校验可能并不需要强依赖,因此我们对这部分进行了优化,如下图:分离出需要用户登录的强依赖代码、和不需要用户登录的弱依赖代码,将注解的方式AOP调用放入到强依赖的业务代码中并和一部分不需要登录的弱依赖业务代码并行执行,异步完成登陆校验和用户信息获取,从而达到降低接口耗时的目的。
Before:
@LoginAop(); //这里由于注解的存在,首先会AOP调用登陆校验的方法
public void dosomething(){
doA(); // 业务逻辑A,需要登陆检查
doB(); // 业务逻辑B,不需要登陆检查
doC(); // 业务逻辑C,不需要登陆检查
after();// 全部均为串行操作,后一个操作需等待前一个任务结束才能开始执行
}
After:
//将这里的LoginCheck注解AOP校验登录的方式去除
public void dosomething(){
async.doAsync(loginCheck()); // 异步调用登录校验
async.doAsync(doB()); // 异步业务逻辑B,不需要登陆检查
async.doAsync(doC()); // 异步业务逻辑C,不需要登陆检查
timeWait(loginCheck); // 等待登录校验完成
async.doAsync(doA()); // 异步业务逻辑A,需要登陆检查(这里已经在上面校验登录完成)
timeWait(A,B,C); // 等待A,B,C全部执行完毕
aggregateResponse(A,B,C) // 聚合结果返回
}
2.2 动静分离,齐心协力

在一定的业务场景下,我们的接口返回给前端的数据可以划分为静态数据和动态数据两种类型。
静态数据:这部分数据具有在一定时间内不容易发生变更的特性,或者说发生的变更在业务的容忍度接受以内。这部分数据不用每次都需要进行逻辑计算或者实时获取,我们可以放在缓存中,提高获取效率。
动态数据:这部分数据具有易变性,每次调用获取的都不同,或者根据不同的纬度具有不同的表现,这部分数据需要实时性。因此,这部分数据我们需要实时查询获取,或者动态计算。
基于静态数据和动态数据的特点,我们进行了业务分割:对静态数据添加多级缓存来进行存储,提高读取性能和缓存命中率,动态数据则每次实时查询获取,保证数据的实时性和准确性。改变前后对比如下图所示:
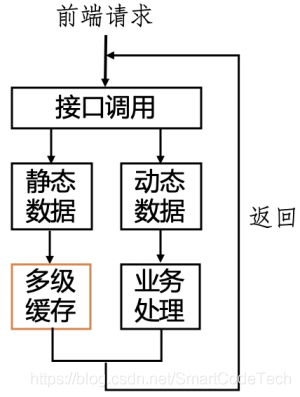
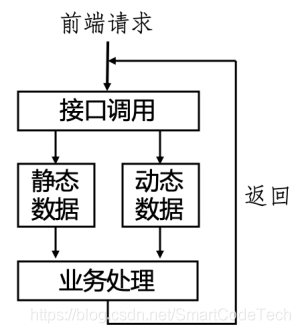
动静分离的策略是一个好的方法,但是绝不要认为是万能的方法。它的适用性在于合适的业务场景,对于业务数据可以进行合理的分离。以商品详情业务场景为例:业务数据主要分为两部分:
(1)对外展示的商品信息数据,比如商品名称、图片等等。这部分数据很明显符合一定时间内不会变更的特点,因此这部分数据可以当做静态数据,并将其放入缓存中提高查询效率。
(2)第二部分数据是和商品有关的活动或者营销类的数据,这部分数据是需要很高的业务实时性的。比如一个活动上一秒还可以参加,下一秒就无法参加了。因此这部分数据我们划分为动态数据,这部分数据每次都需要实时的获取和计算。
根据上面的划分,我们针对静态数据采用多级缓存来存储,以此提高查询效率,并采用异步刷新机制保证数据可以在规定时间内进行更新。动态数据,我们则每次实时获取和计算,保证数据的准确性。如下面所示:
before:
public void getProductInfo(){
dynmaicGetProduct() // 动态获取商品信息
dynmaicGetProductPromotion() // 动态获取商品活动信息
aggreateResponse() // 聚合数据返回
}
after:
public void getProductInfo(){
staticGetProduct() // 获取商品信息静态数据
dynmaicGetProductPromotion() // 动态获取商品活动信息
aggreateResponse() // 聚合数据返回
}
private void staticGetProduct(){
Product product = null;
// 判断是否是特殊商品,比如大促商品走特殊缓存
if(isSpecialProduct()) {
//从本地缓存获取数据
product = getSpecialProductFromLocalCache();
}
//是否开启本地缓存开关
if(localCacheSwitch()) {
//从本地缓存获取数据
product = getProductFromLocalCache();
}
//是否开启Redis开关
if(redisSwitch()) {
//从Redis获取数据
product = getProductFromRedis();
}
if(product == null) {
product = dynmaicGetProduct() // 动态获取商品信息
if(redisSwitch()) {
setRedis(product) //设置Redis
}
}
}
Tips: 对于本地缓存,我们提供了开关控制,除了可以比较不同实现的相应时间以外,也算是提供了兜底策略,当本地缓存出现问题时,可以快速切换为原有的动态调用获取业务数据的方式。并且配置热点数据,基于热点数据,提供更长时间的静态缓存,保证秒杀、新品发售等场景下热点缓存的更高命中率。
2.3 强弱有别,按需分配

从第一个方法中我们可以看到并发编程的引入能很好的提高代码执行效率,但同时也会引入一个问题:如何做好线程池资源划分?之前我们均统一去请求线程池分配,即不区分优先级,而是“一视同仁”,每个任务都是公平的获取线程资源,这样做虽然能简化业务逻辑,但为了更好的进行优化,我们决定进一步去细分对线程池对请求:即按照重要程度对其作区分,对重要任务给予更多的线程资源,做到“强弱有别,按需分配”,从而提升整体的接口稳定性。改变前后如下图所示。
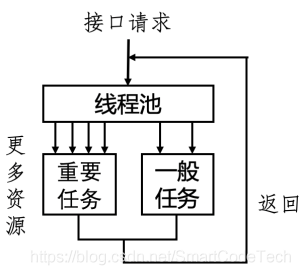
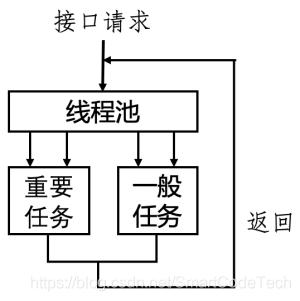
比如商品详情这种依赖很多下游服务,需要通过下游服务获取信息后聚合返回客户端,接口稳定性和性能都非常依赖下游接口性能。但是这些依赖其实也有强弱之分,对于影响了用户体验和核心链路流程的功能的依赖称之为强依赖。对于那些加上也是锦上添花,去除也无伤大雅的功能依赖称之为弱依赖。我们针对不同的强弱依赖,提供不同的并发量控制。
实现的方式有很多,比如自己实现一个简单的信号数量控制就可以达到这种效果。对于强依赖的接口我们设定的信号数量会大一些,尽可能的让这些重要的依赖可以获取更多的线程资源。对于那些去除也无伤大雅的弱依赖,我们给定的信号数量会少一点,将获取资源的限制控制在一个阈值内。如果是大促时间,为了提高性能,甚至可以直接将弱依赖的信号数量降低至0直接降级掉。这些都是做到动态可以配置的。
public void doVIP(){
if(thread.currentNums < thread.vipNums) //重要任务设置高并发量
doVIP();
else
//进行处理
}
public void doNormal(){
if(thread.currentNums < thread.normalNums) //一般任务设置低并发量
doNormal();
else
//进行处理
}
/**
* 自带限流控制线程池
* @param semaphore
* @param concurrency
* @param runnable
* @param pool
* @return
*/
public static CompletableFuture<Void> flowControlFuture(TryableSemaphore semaphore, Integer concurrency, Runnable runnable, ExecutorService pool) {
if (semaphore == null || INDEX_FLOW_CONTROL_SWITCH == null || !INDEX_FLOW_CONTROL_SWITCH.booleanValue()) {
return CompletableFuture.runAsync(runnable, pool);
}
Runnable run = semaphore.tryAcquire(concurrency,runnable);
if (run != null) {
try {
return CompletableFuture.runAsync(run, pool);
} catch (Throwable e) {
semaphore.release();
}
}
return null;
}
public static CompletableFuture<Void> future(Runnable runnable, ExecutorService pool) {
try {
return CompletableFuture.runAsync(runnable, pool);
} catch (Throwable e) {
log.error("任务加入线程池失败!", e);
return null;
}
}
2.4 未雨绸缪,默认兜底

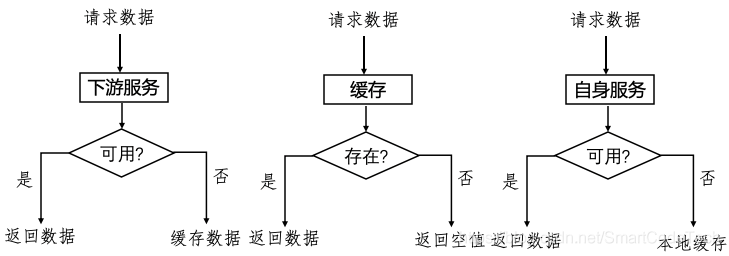
对于核心的流量入口,影响到下单流程的业务场景,比如商品详情。商品详情一旦不可用,就会影响下单,造成巨大损失,因此我们需要考虑到各种极端情况。对于各种出现的极端场景,我们也要做到当问题发生时,同样也能保证业务功能的健全性,不影响用户的体验。故我们采取“未雨绸缪、严格兜底”。兜底的方案各式各样,也根据不同的业务场景拥有不同的处理方式,这里就举例从三个场景来说明:下游服务不可用时、缓存出现问题时、自身服务不可用时。
下游服务不可用
比如首页这种业务场景,作为一级的流量入口必须保证其高可用。但是首页又会依赖多个下游服务,当下游服务不可用时,我们该如何处理?这种就需要严格的兜底方案和优化。这里我们分两个优化
(1)首屏和非首屏数据展示区分化。首屏的数据大多数是包含了活动类的数据,这部分数据其实只有首屏才会有,其余的翻页是不需要渲染的。因此我们判断是否不是首屏,则不会请求这部分的数据,提高接口性能。
(2)对于首页的强依赖下游,我们做好了严格的兜底。比如将兜底数据放进缓存,当下游服务不可用时,我们会从缓存中获取兜底数据保证用户的可用性。
public void dosomething(){
try{
data = callA();
return data; //下游可用时直接获取
}
catch(Exception e){
data = cache.getData(); //下游不可用时从缓存取兜底数据
return data;
}
}
public void dosomething(){
//判断是否首屏
if(firstScreen()) {
//获取活动数据
getPromotion();
}
doA();
}
缓存问题
对于缓存,我们主要关心两个:缓存的命中率,数据的一致性。由此又会有一些缓存引起的问题,缓存击穿、穿透、雪崩。对于这些问题也是我们在使用缓存时不得不考虑的 。这些问题的解决方案也有很多。这里简单列举几个:
(1)针对无效数据穿透,多级拦截:
无效数据,空数据,进行多种手段拦截,如布隆过滤器、业务参数有效性判断、缓存空值等等。多种手段拦截就是让流量最后无法穿透到最薄弱的底层服务。
(2)针对高并发热点key击穿,两阶段失效:
对于高并发的热点key,做逻辑和物理两阶段失效策略,逻辑失效前端响应仍然立即返回,仅异步排队去底层服务或DB获取数据并刷新缓存。
(3)缓存降级,限流排队,多级缓存:
缓存由于各种原因不可用,如果无任何措施,势必会出现雪崩的现象,为了尽可能保证业务服务可用或者部分可用,则必须对缓存允许降级,即便缓存中间件连接异常,宕机等,仍然可以去底层的服务和DB获取数据,常用手段一般是二级、甚至三级缓存,最后就是加锁排队访问底层服务。
(4)失效时间随机
往往热key都是在同一个时间点(短暂的时间段)创建的,如果固定有效时长,则失效将在同一个时间点,当失效发生时,雪崩的可能性很大。在业务要求的失效时间点上,加上随机时长(范围),可以分散热key失效时间点。
自身不可用
在某些极端情况下商品服务本身也可能会不可用,对于这种情况,可以采用了客户端本地缓存的方法:当服务端发生异常导致没有返回数据时,客户端使用缓存数据渲染;同时考虑到商品数量较多,全部缓存不现实,因此我们定期将每个商品静态数据以json格式存入oss中,当接口没有返回数据时,客户端根据特定商品规则,直接从oss中获取静态数据进行渲染,同时增加开关控制防止存入敏感数据,从而保证页面不会因为服务异常而展示空白,提高使用体验。
2.5 限流熔断,管控有制
对于可能存在的大规模流量,我们也需要采取一些措施来进行流量控制,必要时对下游依赖进行熔断。此类的开源框架比较多,比如Hystrix,阿里的Sentinel等。使用的策略也有很多,比如根据接口的RT和熔断阈值两个维度来进行控制。
以Sentinel举个例子:设置RT50ms,熔断阈值5s,那么当一分钟内该接口平均RT大于设置的50ms,就会触发熔断,熔断时间为5秒钟。5秒钟后,在放开熔断正常请求下游服务。
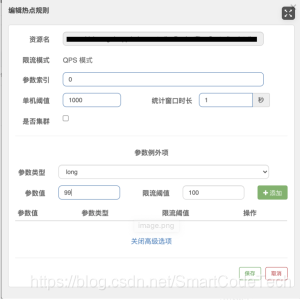
同时相比于普通流控和熔断,我们还可以配置一些热点参数限流,这种情况主要可以针对首发、限定发售、秒杀等高并发场景。针对热点参数进行限流,从而保证大部分商品都能正常完成交易流程。举个示例配置:
上图配置的含义为,针对该接口,第0个参数值=99的入参,在1秒内单机限流阈值为100,其他限流1000。
3. 总结
经过了一系列的优化,在采取了如上的优化策略后,我们进行了一次压力测试,并和之前的测试结果进行对比,如下图所示。
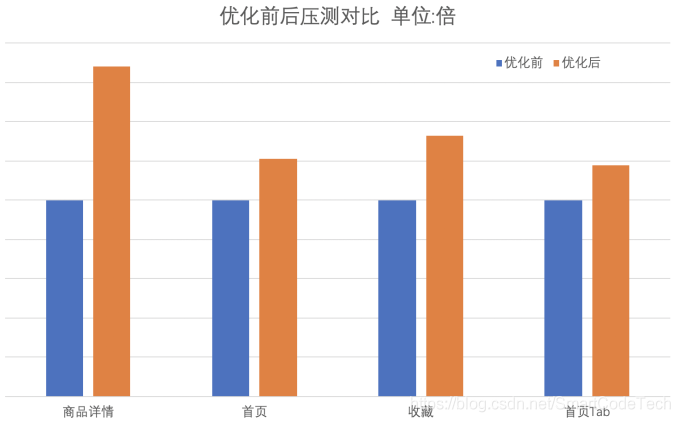
可以看到,优化后每个接口QPS均有提升。前后对比效果都十分的明显,达到了我们预期希望的结果,这也为我们的618活动提供了强有力的保障。
4. 后言
写在最后,在得物,商品中心的改造历程团队中的每个人成员一起一步一个脚印的走到了现在。从五彩石的整体大改造,到稳定性的巨大优化,我们团队不忘初心,承载了五彩石的精神延续,整个团队也从五彩石开始历经了蜕变,洗尽铅华而来。后面我们依然会发扬这份精神,不忘初心、方得始终。