AB实验简介
什么是AB实验
将测试对象随机分成A,B两组,然后比较两组之间的差异
AB测试是为Web或App界面或流程制作两个(A/B)版本,在同一时间维度,分别让组成成分相同(相似)的访客群组(目标人群)随机的访问这些版本,收集各群组的用户体验数据和业务数据,最后分析、评估出最好版本,正式采用。
需要满足的条件:
对照组:有其他对照组作为对比,就能真正看出来效果。而且不同组间的效果差异要足够明显,才能验证我们的判断
随机性:为了排除实验条件以外的干扰因素,我们需要确保两个组的用户是随机选取,这是为了排除用户差异对实验结果的影响
大样本:这里的样本量是指数据量,包括用户、行为和时间跨度,样本量越大,越容易排除个体差异的影响,也更容易验证统计上的显著性
AB实验的原则
唯一变量:
AB实验时需要保证除了要实验的变量之外,实验组和对照组其他的“变量”都是均匀的,包含但不限于:
时间、环境、样本属性等
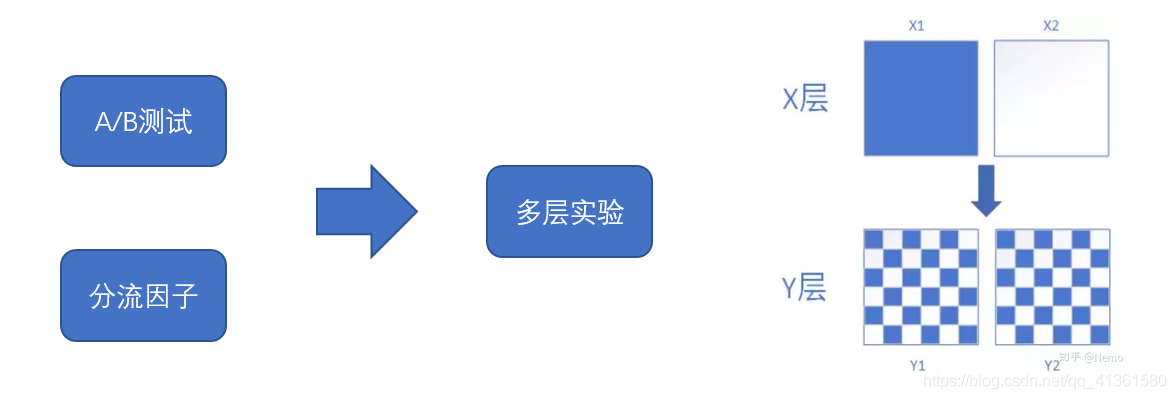
多层实验如何保证唯一变量:
分流因子通过加入不同的字符串(实验名)作为离散因子,保证每层都是正交分布,防止层与层之间有交集。
AB实验涉及的统计学基础
抽样
实验的思想:
用能近似代表总体的样本推断总体的分布(假设检验),利用样本指标近似代替总体指标,继而进行决策;
如何保证:
近似代表总体的样本需满足以下2项条件:
1、随机抽样:实验中的样本是随机抽取的。而且抽取的算法能够充分保证了抽样的随机性。
2、样本能近似代表总体:
样本量越大,通过样本去评估总体的误差就越小。当误差小于我们需要的精度时样本量就足够了。
E
(
X
ˉ
)
=
E
(
1
/
n
∑
i
=
1
n
X
i
)
=
1
n
∑
i
=
1
n
E
(
X
i
)
=
μ
D
(
X
ˉ
)
=
D
(
1
/
n
∑
i
=
1
n
X
i
)
=
1
n
2
∑
i
=
1
n
D
(
X
i
)
=
1
n
σ
2
E(\bar{X})=E(1/n\sum_{i=1}^{n}X_i)=\frac1n\sum_{i=1}^nE(X_i)=\mu\\ D(\bar{X})=D(1/n\sum_{i=1}^{n}X_i)=\frac1{n^2}\sum_{i=1}^nD(X_i)=\frac1n\sigma^2
E(Xˉ)=E(1/ni=1∑nXi)=n1i=1∑nE(Xi)=μD(Xˉ)=D(1/ni=1∑nXi)=n21i=1∑nD(Xi)=n1σ2
所以当n较大时,
X
ˉ
\bar{X}
Xˉ近似服从
N
(
μ
,
σ
2
n
)
N(\mu,\frac{\sigma^2}{n})
N(μ,nσ2),等价地有
X
ˉ
−
μ
σ
/
n
∼
N
(
0
,
1
)
\frac{\bar{X}−\mu}{\sigma/\sqrt{n}}\sim N(0,1)
σ/nXˉ−μ∼N(0,1)。
中心极限定理(central limit theorem):设均值为
μ
\mu
μ、方差为
σ
2
\sigma^2
σ2(有限)的任意一个总体中抽取样本量为n的样本,当n充分大时,样本均值
μ
\mu
μ的抽样分布近似服从均值为
μ
\mu
μ、方差为
1
n
σ
2
\frac1n\sigma^2
n1σ2的正态分布。
样本量计算
样本量计算公式:
均值检验样本量预估:
n
=
(
Z
1
−
α
/
2
+
Z
1
−
β
)
σ
2
E
2
n=\frac{(Z_{1-\alpha/2}+Z_{1-\beta})\sigma^2}{E^2}
n=E2(Z1−α/2+Z1−β)σ2
率值检验样本量预估:
n
=
(
Z
1
−
α
/
2
+
Z
1
−
β
)
π
(
1
−
π
)
E
2
n=\frac{(Z_{1-\alpha/2}+Z_{1-\beta})\pi(1-\pi)}{E^2}
n=E2(Z1−α/2+Z1−β)π(1−π)
公式中的E代表假设实验能够带来的指标变化值。
要想知道样本量计算公式具体是怎么来的,首先要了解假设检验中的两类错误:
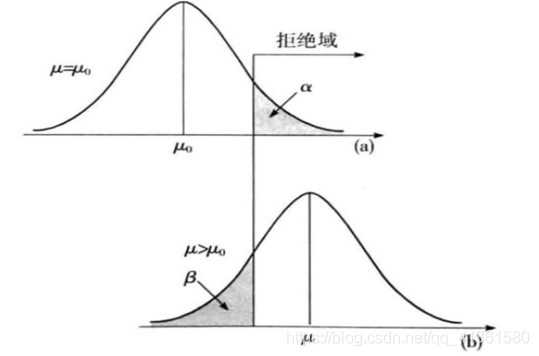

第一类错误代表的是原假设成立,但是却拒绝了原假设的概率,也即上图中阴影面积
α
\alpha
α;
第二类错误代表的是备择假设成立,当检验指标落在原假设的接受域时,在备择假设下的概率,也即上图中阴影面积
β
\beta
β,通俗点说就是,给定第一类错误
α
\alpha
α下,备择假设中的样本,在原假设下检验时接受原假设的可能性。
检验功效是指正确拒绝原假设的概率,也即备择假设成立时,检验拒绝原假设的概率,在数值上和第二类错误有以下数量关系:
P
o
w
e
r
=
1
−
β
Power=1-\beta
Power=1−β
下面我们来推导样本量的计算公式:
首先从单变量假设开始推导
原假设:
H
0
:
μ
=
0
H_0:\mu=0
H0:μ=0
备择假设:
H
1
:
μ
<
>
0
(
μ
=
μ
1
)
H_1:\mu<>0(\mu=\mu_1)
H1:μ<>0(μ=μ1)
给定样本均值
X
ˉ
\bar{X}
Xˉ,一类错误
α
\alpha
α,二类错误
β
\beta
β,令
Z
=
X
ˉ
−
μ
σ
/
n
Z=\frac{\bar{X}−\mu}{\sigma/\sqrt{n}}
Z=σ/nXˉ−μ
则:
P
(
∣
Z
∣
≥
Z
1
−
α
/
2
)
=
α
⇒
∣
Z
∣
=
∣
X
ˉ
−
μ
σ
/
n
∣
≥
Z
1
−
α
/
2
⇒
∣
X
ˉ
∣
≥
Z
1
−
α
/
2
σ
n
P(|Z|\geq Z_{1-\alpha/2})=\alpha \Rightarrow |Z|=|\frac{\bar{X}−\mu}{\sigma/\sqrt{n}}|\geq Z_{1-\alpha/2}\Rightarrow |\bar{X}|\geq Z_{1-\alpha/2}\frac{\sigma}{\sqrt{n}}
P(∣Z∣≥Z1−α/2)=α⇒∣Z∣=∣σ/nXˉ−μ∣≥Z1−α/2⇒∣Xˉ∣≥Z1−α/2nσ
意味着
∣
X
ˉ
∣
≥
Z
1
−
α
/
2
σ
n
|\bar{X}|\geq Z_{1-\alpha/2}\frac{\sigma}{\sqrt{n}}
∣Xˉ∣≥Z1−α/2nσ时,可以拒绝原假设。
但同时需要保证第二类错误,则当
X
ˉ
∼
N
(
μ
1
,
σ
2
n
)
\bar{X}\sim N(\mu_1,\frac{\sigma^2}{n})
Xˉ∼N(μ1,nσ2)时,假设
μ
1
>
0
\mu_1>0
μ1>0,则要求单边检验
P
(
X
ˉ
≥
Z
1
−
α
/
2
σ
n
)
X
ˉ
∼
N
(
μ
1
,
σ
2
n
)
≥
1
−
β
P(\bar{X}\geq Z_{1-\alpha/2}\frac{\sigma}{\sqrt{n}})_{\bar{X}\sim N(\mu_1,\frac{\sigma^2}{n})}\geq 1-\beta
P(Xˉ≥Z1−α/2nσ)Xˉ∼N(μ1,nσ2)≥1−β
同时对
X
ˉ
\bar{X}
Xˉ进行标准化,可以得到
P
(
X
ˉ
−
μ
1
σ
/
n
≥
Z
1
−
α
/
2
σ
n
−
μ
1
σ
/
n
)
≥
1
−
β
P( \frac{\bar{X}-\mu_1}{\sigma/\sqrt{n}}\geq \frac{Z_{1-\alpha/2}\frac{\sigma}{\sqrt{n}}-\mu_1}{\sigma/\sqrt{n}})\geq 1-\beta
P(σ/nXˉ−μ1≥σ/nZ1−α/2nσ−μ1)≥1−β
其中
X
ˉ
−
μ
1
σ
/
n
∼
N
(
0
,
1
)
\frac{\bar{X}-\mu_1}{\sigma/\sqrt{n}}\sim N(0,1)
σ/nXˉ−μ1∼N(0,1),则只需要
Z
1
−
α
/
2
σ
n
−
μ
1
σ
/
n
≤
−
Z
1
−
β
\frac{Z_{1-\alpha/2}\frac{\sigma}{\sqrt{n}}-\mu_1}{\sigma/\sqrt{n}}\leq -Z_{1-\beta}
σ/nZ1−α/2nσ−μ1≤−Z1−β(各位自行画出正态图像判断),求解方程可以得到:
n
≥
σ
2
μ
1
2
(
Z
1
−
α
/
2
+
Z
1
−
β
)
2
n\geq \frac{\sigma^2}{\mu_1^2}(Z_{1-\alpha/2}+Z_{1-\beta})^2
n≥μ12σ2(Z1−α/2+Z1−β)2
这里的
μ
1
\mu_1
μ1的含义就是预计实验带来的指标变化大小,也即E的值;
在实际应用中可以利用样本方差
S
n
2
S_n^2
Sn2代替
σ
2
\sigma^2
σ2来计算所需样本量,率值的
σ
2
=
π
(
1
−
π
)
\sigma^2=\pi(1-\pi)
σ2=π(1−π),可以得到
n
≥
π
(
1
−
π
)
μ
1
2
(
Z
1
−
α
/
2
+
Z
1
−
β
)
2
n\geq \frac{\pi(1-\pi)}{\mu_1^2}(Z_{1-\alpha/2}+Z_{1-\beta})^2
n≥μ12π(1−π)(Z1−α/2+Z1−β)2
接下来重新回归AB实验问题,即两样本均值或率值检验时
假设A组服从分布
N
(
μ
A
,
σ
2
)
N(\mu_A,\sigma^2)
N(μA,σ2),B组服从分布
N
(
μ
B
,
σ
2
)
N(\mu_B,\sigma^2)
N(μB,σ2),这两样本均值差
X
A
ˉ
−
X
B
ˉ
\bar{X_A}-\bar{X_B}
XAˉ−XBˉ服从
N
(
μ
A
−
μ
B
,
σ
2
/
(
1
1
n
A
+
1
n
B
)
)
N(\mu_A-\mu_B,\sigma^2/(\frac{1}{\frac{1}{n_A}+\frac{1}{n_B}}))
N(μA−μB,σ2/(nA1+nB11))
同时,假设两组的样本量
n
A
=
k
n
B
n_A=kn_B
nA=knB,则可以计算得到
两样本均值检验,最小样本量为
n
B
≥
(
1
+
1
k
)
σ
2
(
μ
A
−
μ
B
)
2
(
Z
1
−
α
/
2
+
Z
1
−
β
)
2
n_B\geq (1+\frac1k) \frac{\sigma^2}{(\mu_A-\mu_B)^2}(Z_{1-\alpha/2}+Z_{1-\beta})^2
nB≥(1+k1)(μA−μB)2σ2(Z1−α/2+Z1−β)2
两样本率值检验,最小样本量位
n
B
≥
(
1
+
1
k
)
π
(
1
−
π
)
(
μ
A
−
μ
B
)
2
(
Z
1
−
α
/
2
+
Z
1
−
β
)
2
n_B\geq (1+\frac1k) \frac{\pi(1-\pi)}{(\mu_A-\mu_B)^2}(Z_{1-\alpha/2}+Z_{1-\beta})^2
nB≥(1+k1)(μA−μB)2π(1−π)(Z1−α/2+Z1−β)2
效果评估(最小重要变化-目标提升值)
在工业运用中,只有当试验版本的结果兼备统计显著和效果显著两个特征时,才说明这个试验的结束时机已经成熟,该版本是真正值得发布的,因此,我们需要引入一个“最小重要变化”的概念来辅助我们判断和决策。
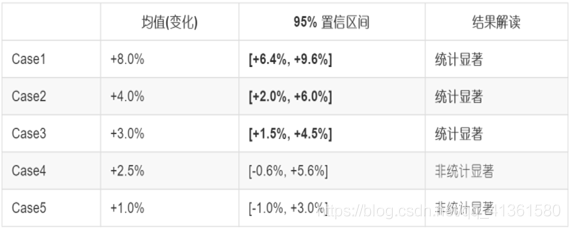
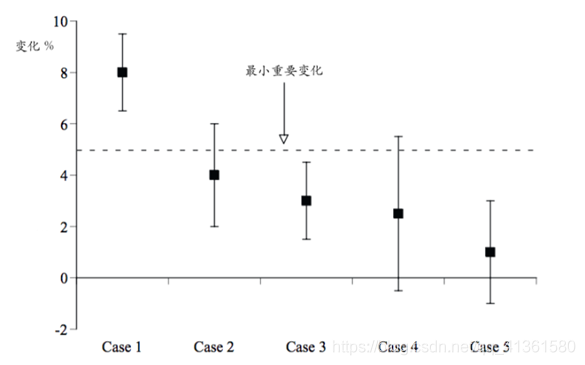
当置信区间的上下上下界都超过或低于最小重要变化时才说他是效果显著的。