在寒假的几次嵌入式工程师的面试中,经常被面试官问到关于c语言中字节对齐的问题,在一般的书上也并不会谈及关于字节对齐的内容,因此想以此篇文章记录一下我对字节对齐的一些想法。
在结构体中,包含着不同类型的数据,他们类型不同,所占的字节数也各不相同,因此,这就涉及到了关于字节对齐的知识,在32位机中,常常按照4字节对齐,也就是int所占字节数,那么为什么字节对齐呢?
翻看微机的书,再结合网上大佬们的解答,我表达一下我自己的一些理解,在8086中,1MB的地址空间被分为了奇偶两个存储体,奇存储体里均为奇数地址,而偶存储体里均为偶数地址,以奇数地址为起始的字成为非规则字,CPU需要花费两个总线周期来读数据,而对于偶数地址为起始地址的规则字,CPU只需要花费一个时钟周期,这无疑不提高了CPU的工作效率。因此,就有了字节对齐一说,目的之一是为了提高CPU的工作效率。同时,C语言中还可以通过#pragam pack(n)用来调整对齐的字节数。
下面我们来通过一个例子来加深理解:
struct wzw
{
char c;
int i;
short s;
};struct wzw1
{
char c;
short s;
int i;
}sizeof(wzw)和sizeof(wzw1)分别占了几个字节呢?我画了一张图,相信大家可以很直观地理解。
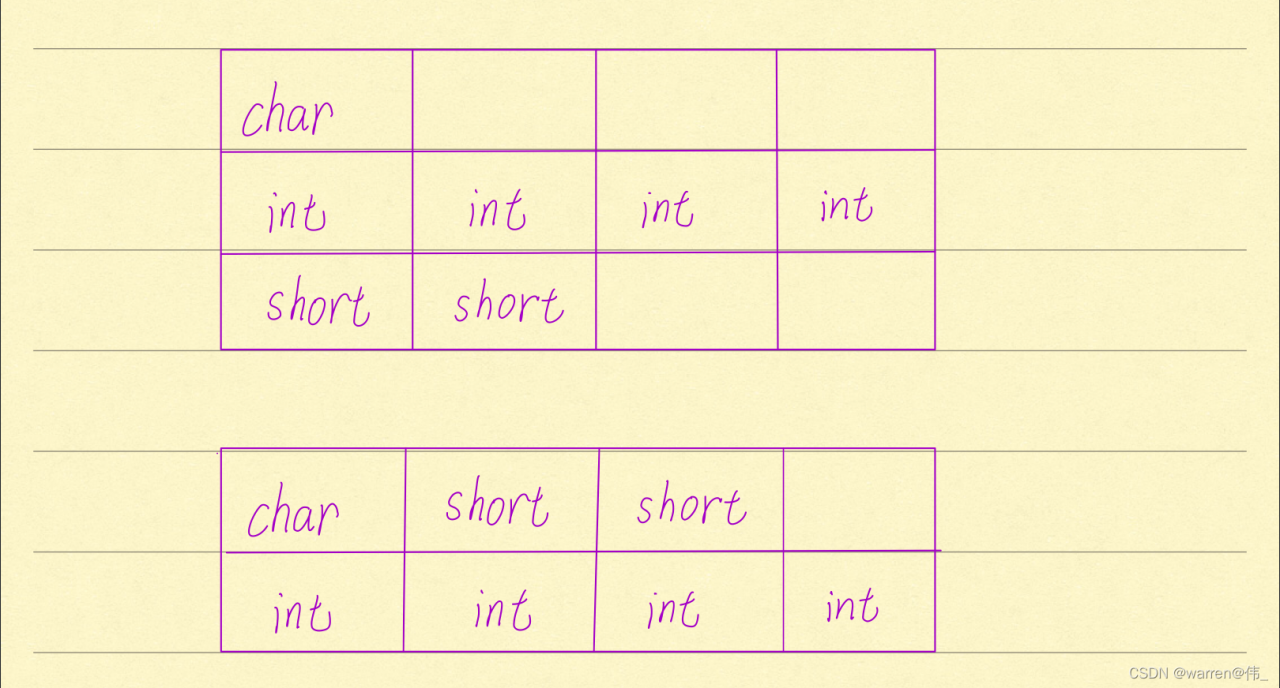
以上是我的个人理解,若有错误,希望大佬指正!
版权声明:本文为warren103098原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。