在使用C语言编程时,我们常用memcpy来复制内存数据,但很少有人会关注到memcpy怎么实现。最简单的memcpy功能实现如下:
void *low_memcpy(void *dst, const void *src, size_t length)
{
char *srcp = (void*)src;
char *dstp = (void*)dst;
char *tail = srcp + length;
while(srcp < tail) *dstp ++ = *srcp ++;
return dst;
}一.数据对齐
这通常是一个初学者的实现,满足memcpy的功能,但性能非常低,因为while()每一次循环只能复制一个字节。如果要进一步的优化,就需要用到更多的知识,例如CPU位宽、数据对齐、时钟周期等等,学过计算机原理应该知道CPU字长、寄存器位宽等概念。现在常见的CPU通常为32/64位,今天我们以32位CPU来讲解。32位CPU字长为32BIT,即它的每个通用寄存器包含32个位,占4个字节,一个内存访问周期可以完成4个字节的读写,如果按照low_memcpy()函数的实现,每次while()循环只能复制1个字节,会浪费大量的内存访问周期。那我们能否按照32位CPU位宽,即4个字节为单位进行内存复制呢?CPU从内存取数据的过程,了解的人都知道,对齐存放的数据可加快CPU处理的速度,因为在同一个时钟周期内,CPU访问的数据总是按32位对齐访问的。例如CPU寄存器从内存0x20000001开始取32位数据需要两次访问内存:第一次取3字节0x20000001~0x20000003,第二次取1字节0x20000004。但是,如果从0x20000008开始取32位数据则可以一次性全部取出。
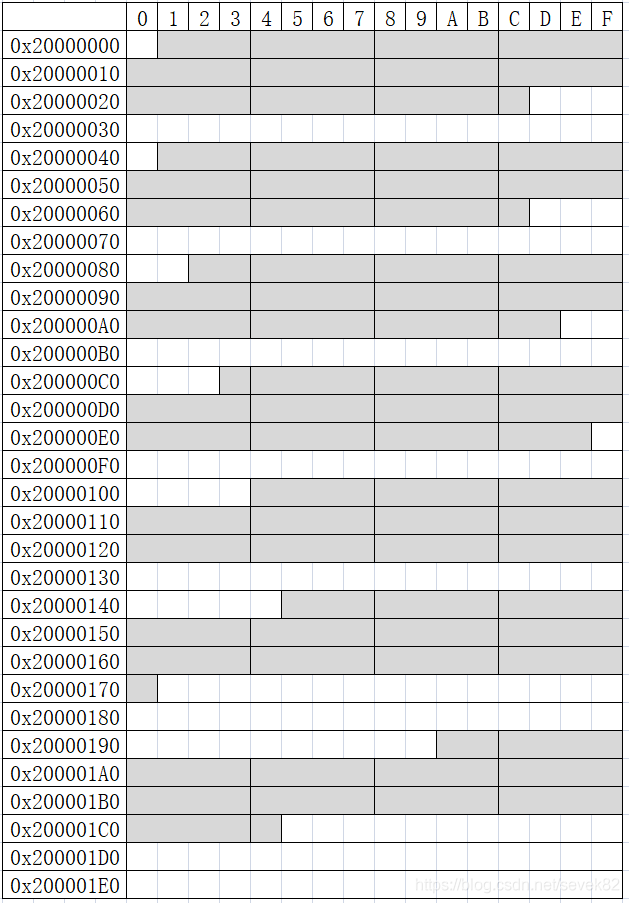
参考上图,如果需要按对齐方式将0x20000001到0x2000002C中总共48字节的数据复制到0x20000041、0x20000082,0x200000C3,0x20000104,0x20000145,0x2000019A等几个目标位置,复制过程包括哪些步骤呢?
从0x20000001到0x20000041:先按字节复制前3个字符,需要循环3次,再按4字节对齐复制0x20000004到0x2000002B之间的数据,共需要循环10次,最后一个字节复制1次,共计14次内存访问。
从0x20000001到0x20000082:因为源和目标无法同时对齐,只能按照字节复制,需要访问内存48次,为什么源和目标必须对齐呢?假设复制到0x20000004时源正好对齐到4字节,但是此时该地址的数据将被复制到0x20000085,但目标地址并不对齐。
从0x20000001到0x200000C3:因为源和目标无法同时对齐,只能按照字节复制,需要访问内存48次。
从0x20000001到0x20000100:因为源和目标无法同时对齐,只能按照字节复制,需要访问内存48次。
从0x20000001到0x20000145:先按字节复制前3个字符,需要循环3次,再按4字节对齐复制0x20000004到0x2000002B之间的数据,共需要循环10次,最后一个字节复制1次,共计14次内存访问。
从0x20000001到0x2000019A:因为源和目标无法同时对齐,只能按照字节复制,需要访问内存48次。
通过上述分析,我们发现:
1.如果数据能够对齐,访问内存的次数只有单字节复制的1/3,即性能提升接近3倍。
2.在32位机上源和目标对4取模的结果一致才能对齐。
二.指令流水线
除了数据对齐外,是否能从CPU指令流水线方面作出一些优化呢?指令流水线的作用是将一条指令分割成多个步骤,并由不同的部件顺序完成,在同一时刻,每个部件可以同时执行多个指令的不同步骤,尽可能保证每个时钟周期都能输出一条指令结果。如果你了解指令流水线应该明白,跳转指令将导致控制冒险,C语言中的if{}else{};while();for(;;){};以及switch case都将可能生成跳转指令。那么,如何避免或减少控制冒险呢?增加循环中的代码量可以减少控制冒险。
int a1[ARRAY_COUNT] = { 0xff };
int a2[ARRAY_COUNT] = { 0x00 };
void test1(void)
{
int i;
for (i = 0; i < ARRAY_COUNT; i++)
{
a2[i] = a1[i];
}
}
void test2(void)
{
int i;
for (i = 0; i < ARRAY_COUNT/8; i+=8)
{
a2[i + 0] = a1[i + 0];
a2[i + 1] = a1[i + 1];
a2[i + 2] = a1[i + 2];
a2[i + 3] = a1[i + 3];
a2[i + 4] = a1[i + 4];
a2[i + 5] = a1[i + 5];
a2[i + 6] = a1[i + 6];
a2[i + 7] = a1[i + 7];
}
}例如以上代码,test1和test2的目的都是将a1复制到a2,但是test1会执行64次循环,每次循环都将导致控制冒险,而test2仅有8次循环,控制冒险减少为8次。除此之外,test1执行过程中CPU需要执行的指令数量比test2至少多56条比较和跳转指令,共计112条指令。
3.优化结果
废话少说,直接上代码:
/*
* Copyright(C) 2013-2015, Fans-rt development team.
*
* All rights reserved.
*
* This is open source software.
* Learning and research can be unrestricted to modification, use and dissemination.
* If you need for commercial purposes, you should get the author's permission.
*
* date author notes
* 2014-09-07 JiangYong new file
*/
#include <config.h>
#include <debug.h>
#include <stddef.h>
#include <stdlib.h>
#include <string.h>
#include <stdbool.h>
#include <stdint.h>
#include <stdio.h>
#include <sys/types.h>
void *fast_memcpy(void *dst, const void *src, size_t length)
{
union{
char *lpstr;
uint32_t *lpint;
}s;
union{
char *lpstr;
uint32_t *lpint;
}d;
char *suffix = (void*)(((uint32_t)src) + length);
char *prefix = (void*)(((uint32_t)src) & (~(sizeof(uint32_t)-1)));
uint32_t *middle = (void*)(((uint32_t)suffix) & (~(sizeof(uint32_t)-1)));
s.lpstr = (void*)src;
d.lpstr = (void*)dst;
if (prefix != src)
{
while(s.lpstr < prefix + sizeof(uint32_t))
{
*d.lpstr++ = *s.lpstr ++;
}
}
while(s.lpint < middle - (sizeof(uint32_t) * 8))
{
*d.lpint++ = *s.lpint ++;
*d.lpint++ = *s.lpint ++;
*d.lpint++ = *s.lpint ++;
*d.lpint++ = *s.lpint ++;
*d.lpint++ = *s.lpint ++;
*d.lpint++ = *s.lpint ++;
*d.lpint++ = *s.lpint ++;
*d.lpint++ = *s.lpint ++;
}
while(s.lpint < middle - (sizeof(uint32_t) * 4))
{
*d.lpint++ = *s.lpint ++;
*d.lpint++ = *s.lpint ++;
*d.lpint++ = *s.lpint ++;
*d.lpint++ = *s.lpint ++;
}
while(s.lpint < middle - (sizeof(uint32_t) * 2))
{
*d.lpint++ = *s.lpint ++;
*d.lpint++ = *s.lpint ++;
}
while(s.lpint < middle) *d.lpint++ = *s.lpint ++;
while(s.lpstr < suffix) *d.lpstr++ = *s.lpstr ++;
return dst;
}
void *memcpy(void *dst, const void *src, size_t length)
{
if ((((uint32_t)src) & (~(sizeof(uint32_t)-1))) != (((uint32_t)dst) & (~(sizeof(uint32_t)-1))))
{
char *lpSrc = (void*)src;
char *lpDst = (void*)dst;
char *lpTail = lpSrc + length;
while(lpSrc < lpTail) *lpDst ++ = *lpSrc ++;
return dst;
}
return fast_memcpy(dst, src, length);
}