参考文献
1.对数损失函数(Logarithmic Loss Function)的原理和 Python 实现
2.交叉熵与KL散度
3.深度学习剖根问底:交叉熵和KL散度的区别
4.详解机器学习中的熵、条件熵、相对熵和交叉熵
5.为什么交叉熵(cross-entropy)可以用于计算代价?
6.机器学习中的基本问题——log损失与交叉熵的等价性
核心:KL散度=交叉熵-熵
对于给定训练集,熵是已知的,那么求取KL散度等价于求取交叉熵,因此交叉熵才被用作代价函数
要再次强调:我们的目的是通过一种指标,衡量两个概率分布之间的差异(即真实概率分布和模型训练出的概率分布,又因为真实概率分布无法得到,因此以训练数据集的概率分布作为真实概率分布),KL散度满足这一需求,同时又因为KL散度和交叉熵的关系,因此我们才将交叉熵作为问题的代价函数!
通用的说,熵(Entropy)被用于描述一个系统中的不确定性(the uncertainty of a system)。在不同领域嫡有不同的解释,比如热力学的定义和信息论也不大相同。
要想明白交叉嫡(Cross Entropy)的意义,可以从嫡(Entropy)->KL散度(Kulback-Leibler Divergence)->交叉这个顺序入手。当然,也有多种解释方法。
先给出一个“接地气但不严谨”的概念表述:
【1】熵:可以表示一个事件A的自信息量,也就是A包含多少信息。
【2】KL散度:可以用来表示从事件A的角度来看,事件B有多大不同。
【3】交叉滴:可以用来表示从事件A的角度来看,如何描述事件B。
一句话总结的话:KL散度可以被用于计算代价,而在特定情况下最小化KL散度等价于最小化交叉熵。而交叉熵的运算更简单,所以用交叉熵来当做代价。
1.什么是熵
放在信息论的语境里面来说,就是一个事件所包含的信息量。
我们常常听到“这句话信息量好大”,比如“昨天花了10万,终于在西二环买了套四合院”。
这句话为什么信息量大?因为它的内容出乎意料,违反常理。由此引出:
【1】越不可能发生的事件信息量越大,比如“我不会死”这句话信息量就很大。而确定事件的信息量就很低,比如“我是我妈生的”,信息量就很低甚至为0。
【2】独立事件的信息量可叠加。比如“a.张三今天喝了阿萨姆红茶,b.李四前天喝了英式早茶”的信息量就应该恰好等于a+b的信息量,如果张三李四喝什么茶是两个独立事件。
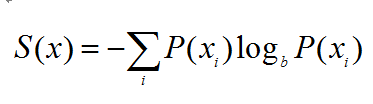
因此熵被定义为上面形式,x指的不同的事件比如喝茶,P(xi) 指的是某个事件发生的概率比如和红茶的概率。对于一个一定会发生的事件,其发生概率为1,S(x)=-log(1)1=-01=0,信息量为0。
2.如何衡量两个事件/分布之间的不同:KL散度
我们上面说的是对于一个随机变量x的事件A的自信息量,如果我们有另一个独立的随机变量x相关的事件B,该怎么计算它们之间的区别?
此处我们介绍默认的计算方法:KL散度,有时候也叫KL距离,一般被用于计算两个分布之间的不同。看名字似乎跟计算两个点之间的距离也很像,但实则不然,因为KL散度不具备有对称性。在距离上的对称性指的是A到B的距离等于B到A的距离。
举个不恰当的例子,事件A:张三今天买了2个土鸡蛋,事件B:李四今天买了6个土鸡蛋。我们定义随机变量x:买土鸡蛋,那么事件A和B的区别是什么?有人可能说,那就是李四多买了4个土鸡蛋?这个答案只能得50分,因为忘记了“坐标系”的问题。换句话说,对于张三来说,李四多买了4个土鸡蛋。对于李四来说,张三少买了4个土鸡蛋。选取的参照物不同,那么得到的结果也不同。更严谨的说,应该是说我们对于张三和李四买土鸡蛋的期望不同,可能张三天天买2个土鸡蛋,而李四可能因为孩子满月昨天才买了6个土鸡蛋,而平时从来不买。

3.KL散度=交叉熵-熵

附:推导

4.机器如何学习

5.为什么交叉熵可以用作代价?

6.交叉熵和对数损失函数之间的关系
交叉熵中未知真实分布 P(x) 相当于对数损失中的真实标记y,寻找的近似分布 q(x) 相当于我们的预测值。如果把所有样本取均值就把交叉熵转化成了对数损失函数。