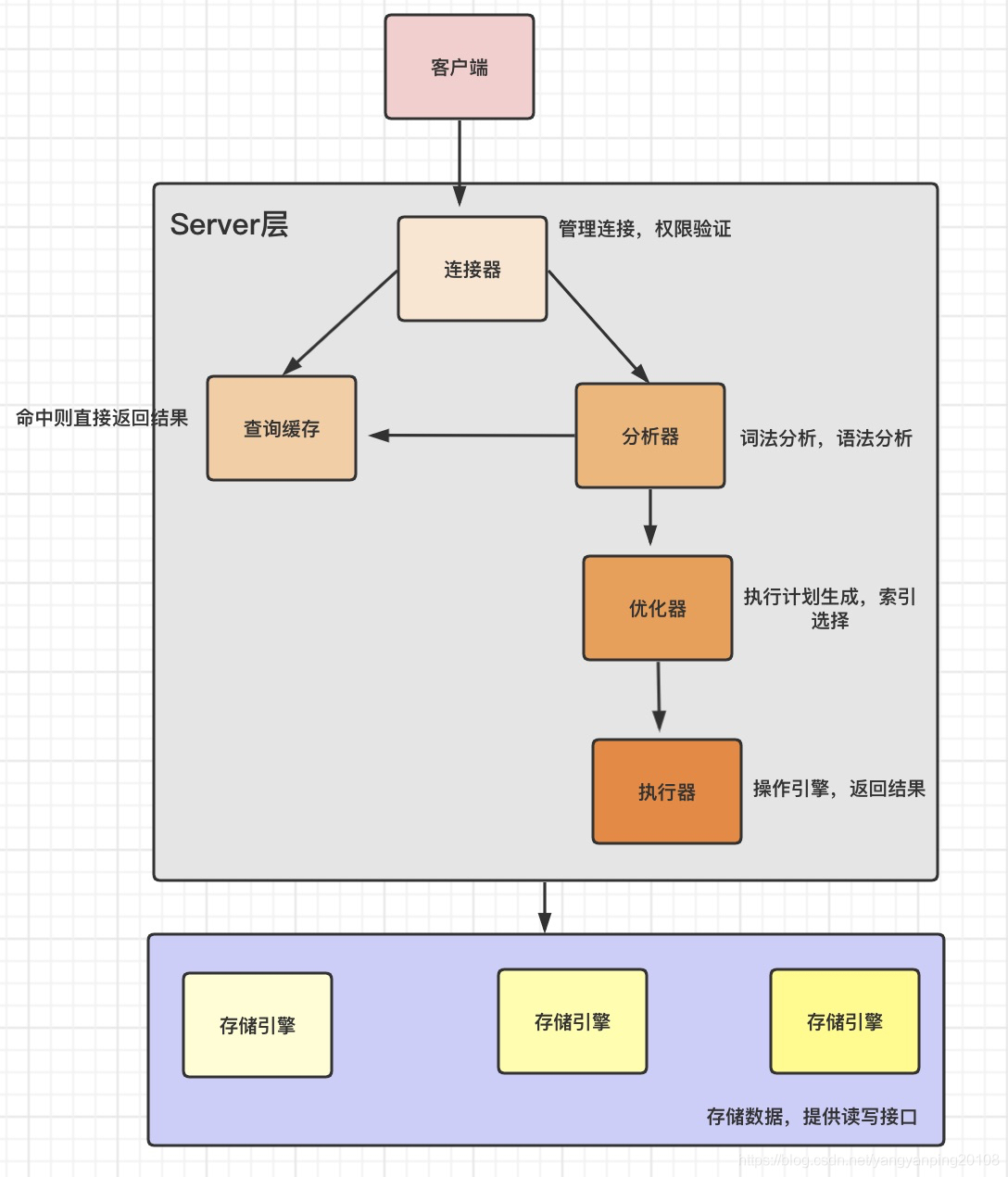
MySQL复制概述
简单来说就是保证主服务器(Master)和从服务器(Slave)的数据是一致性的,向Master插入数据后,Slave会自动从Master把修改的数据同步过来(有一定的延迟),通过这种方式来保证数据的一致性,就是MySQL复制
复制如何工作
复制有三个步骤:
- Master将数据改变记录到二进制日志(binary log)中,也就是配置文件log-bin指定的文件,这些记录叫做二进制日志事件(binary log events)
- Slave通过I/O线程读取Master中的binary log events并写入到它的中继日志(relay log)
- Slave重做中继日志中的事件,把中继日志中的事件信息一条一条的在本地执行一次,完成数据在本地的存储,从而实现将改变反映到它自己的数据(数据重放)
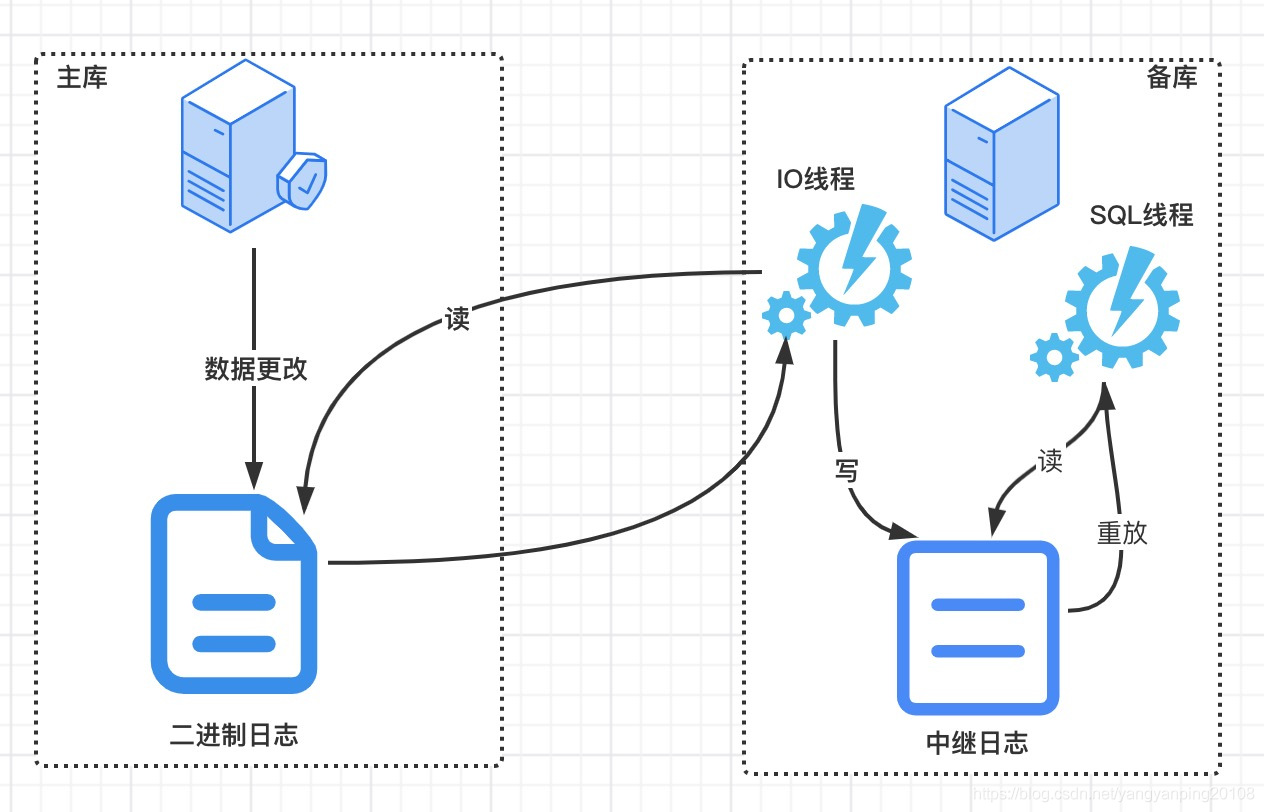
第一步Master记录二进制日志, 每次提交事务完成数据更新前,Master将数据更新的时间记录到二进制日志中,MySql会按事务提交的顺序而非每条语句的执行顺序来记录二进制日志。再记录二进制日志后,主库会告诉存储引擎可以提交事务了。
第二步,Slave将Master的二进制日志复制到本地的中继日志中,首先,Slave会启动一个工作线程,称为I/O线程, I/O线程跟Master建立一个普通的客户端链接,然后再Master上启动一个特殊的二进制转储(binlog dump)线程(该线程没有对应的SQL命令),这个二进制转储线程会读取主库上的二进制日志中的事件。从库I/O线程将接受到事件记录到中继日志中。
第三步从库的SQL线程执行最后异步,该线程的从中继日志中读取事件并在从库执行,从而实现从库数据更新。
这种复制架构实现了获取事件和重放事件的解偶,允许这两个过程异步进行。也就是说I/O线程能够独立于SQL线程之外工作。但这种架构也限制了复制的过程,其中最重要的一点是主库上并发运行的查询在从库只能串行化执行,因为只有一个SQL线程重放中继日志中的事件。这是很多工作负载的性能瓶颈所在。因为始终受限于单线程。
两阶段提交
在执行一条update语句时候,通过连接器、分析器、优化器之后,调用操作引擎,将新行写入内存,写入redo log,状态为prepare->写binlog->redo log状态修改为commit。写入redo的过程分为了prepare和commit称为二阶段提交
redo和binlog这两种日志有以下三点不同:
- redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
- redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
- redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
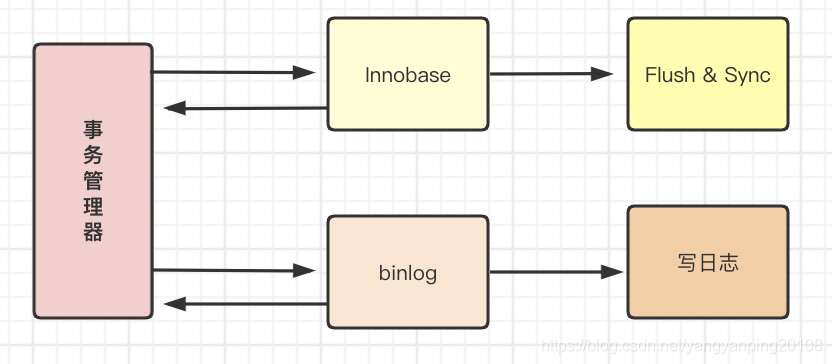
以 update test set num=num+1 where id=1来描述二阶段提交的过程:
- 执行器调用 Innodb的读接口取出id=1这一行的数据,将num改为num+1,然后在调用Innodb的写接口。
- Innodb写接口被调用后,先把数据写到内存,然后写redo log日志,写完后,将redo log日志置为prepare状态,告诉执行器,自己随时可以提交;
- 执行器写bin log日志,写完后,调用Innodb进行事物提交。
prepare:
commit:
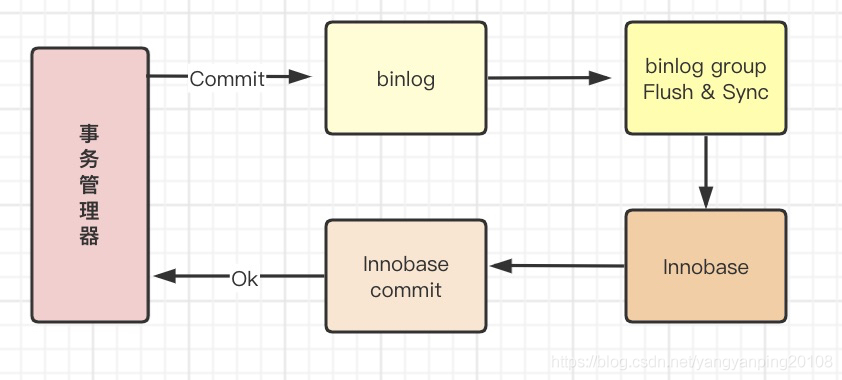
- 可能出现的宕机时机
binlog有记录,redolog状态commit:正常完成的事务,不需要恢复;
binlog有记录,redolog状态prepare:在binlog写完提交事务之前的宕机,恢复操作:提交事务。(因为之前没有提交)
binlog无记录,redolog状态prepare:在binlog写完之前的宕机,恢复操作:回滚事务(因为宕机时并没有成功写入数据库)