目录
引言
计算机视觉作为人工智能的一个重要分支,其显著的研究成果已逐渐应用于人们的实际生活中,如人脸识别、目标追踪等。而图像分类是计算机视觉中的一个基础问题,如何高效准确的实现图像分类具有重要的研究意义和实用价值。
一、数据集的准备
手写数字识别数据集(MNIST)包含60000条训练数据和10000条测试数据,一共有 10 类,分别对应数字从0-9。数据集中每一条数据均由feature(数字图像)和labels(标签)组成。如图1所示,每个图像都是固定大小(28×28像素),其值为0到1。每个图像都被平展并转换为 784(28×28)个特征的一维numpy数组。

图1 MNIST数据集
二、算法设计
-
SVM
支持向量机(SVM)是一种基于统计学习理论的二分类模型,在特征空间上使用间隔最大化进行分类。对于线性可分问题,SVM 利用二次规划来实现最大分类间隔;对于非线性分类问题,SVM 先通过合适的核函数将输入空间映射到高维空间,再在高维空间实现线性可分。SVM非线性映射的目的是寻求一个最优的超平面使分类间隔最大,同时,在样本数据的学习泛化能力和映射的复杂性方面达到最佳。
假设 x 表示二分类的数据点,用 y 表示类别,那么线性分类器的学习目标是在 n 维的数据空间寻找到一个超平面,这个超平面的方程如下:
(1)
其中,中的 T代表转置;w和 b 分别表示权重和偏置;在超平面确定的情况下,
表示点 x 到距离超平面的远近。如图2所示,五角星和圆点分别表示两种类别,分布在超平面的两侧。
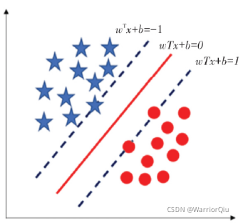
图2 SVM的分类超面
超平面离数据点的“间隔”越大,分类的确信度也越大。为了提高分类的确信度,需要让所选择的超平面能够最大化这个“间隔”。目标函数为:
![]() s.t.
s.t. (2)
其中,是非线性映射,将数据从低维空间映射高维空间。目标函数是二次的,约束条件是线性的,(2)是一个凸二次规划问题。
-
KNN
KNN算法也叫K邻近算法,该算法最早由Cover和Hart于1967年提出,既可以实现分类也可以实现回归。以KNN实现分类算法为例,该算法的工作原理可以理解为给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分到这个类中。
从图3中可以看出,样本实例总共被分成了两类:三角形代表的类别和六角星代表的类别,下文给出对于新的样例圆圈,使用 KNN 算法来进行分类的步骤。先假设一个K值,如果K等于3,那就选最邻近的两个三角形和一个六角星,显然此时圆圈应该和2个三角形分为一类;如果K等于5,那就选最邻近的3个六角星和两个三角形,则圆圈表示的样例应该和六角星代表的类别分为一类。
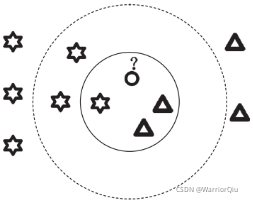
图3 理解KNN算法示意图
KNN算法有两个难点问题,其一是如何确定 K 值的大小,其二是如何寻找与待预测样例距离最近的K个样例。对于第一个问题,如果 K 值太小,会使预测值不够准确;如果K 值太大,又会使预测过程太过复杂。因此,常规的选择 K值的方法是采用交叉验证法。即将训练集中的一部分数据用作训练集,另一部分用作验证集,利用验证集中的样本不断调整 K 的取值来寻找最佳取值。
第二个问题是如何寻找与待预测样本距离最近的 K 个样本。解决该问题的关键是如何计算两个样本之间的距离。目前计算距离的方法主要有欧式距离(Euclidean Distance),曼哈顿距离(Manhattan Distance)等,也可以根据实际情况自行设计距离计算方法。以二维空间的两个节点(x1,y1)和(x2,y2)为例,式 3 和式 4 分别列出了欧式距离和曼哈顿距离的计算方法:
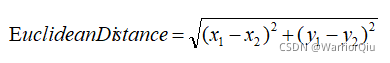 (3)
(3)
![]() (4)
(4)
-
VGGNet
VGGNet 是由牛津大学视觉几何小组(Visual Geometry Group,VGG)提出的一种深度卷积网络结构。模型特点为:使用了3个3×3卷积核来代替7×7卷积核,使用了2个3×3卷积核来代替5×5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
-
ResNet
基于残差网络(Residual Networks,ResNet)结构ResNet模型是由何凯明等人提出的。ResNet 模型的主要创新之处,在于把残差网络引入到了深度卷积神经网络之中。将深层网络模型构建为浅层网络模型和自身映射的增加层,把训练好的浅层结构与自身映射的増加层,通过残差块巧妙的连接在一起。
对于一个堆积层结构(几层堆积而成)当输入为 x时其学习到的特征记为H(x),现在我们希望其可以学习到残差,这样其实原始的学习特征是。之所以这样是因为残差学习相比原始特征直接学习更容易。当残差为0时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。残差学习的结构如图4所示。这有点类似与电路中的“短路”,所以是一种短路连接(shortcut connection)。
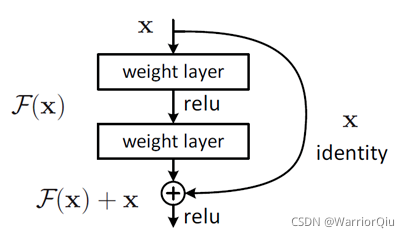
图4 残差学习单元
ResNet使用两种残差单元,如图5所示。左图对应的是浅层网络,而右图对应的是深层网络。对于短路连接,当输入和输出维度一致时,可以直接将输入加到输出上。但是当维度不一致时(对应的是维度增加一倍),这就不能直接相加。有两种策略:(1)采用zero-padding增加维度,此时一般要先做一个downsamp,可以采用strde=2的pooling,这样不会增加参数;(2)采用新的映射(projection shortcut),一般采用1×1的卷积,这样会增加参数,也会增加计算量。短路连接除了直接使用恒等映射,当然都可以采用projection shortcut。
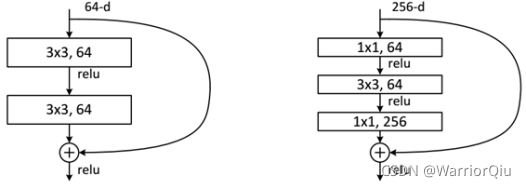
图5 残差学习单元
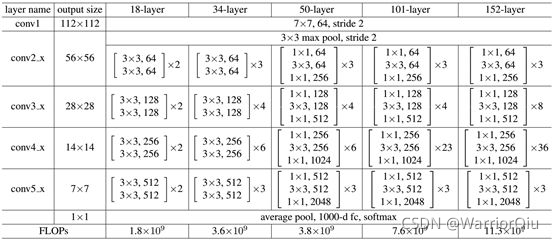
不同深度的ResNet如下表所示,从表中可以看到,对于18-layer和34-layer的ResNet,其进行的两层间的残差学习,当网络更深时,其进行的是三层间的残差学习,三层卷积核分别是1×1,3×3和1×1,一个值得注意的是隐含层的feature map数量是比较小的,并且是输出feature map数量的1/4。
三、实验与分析
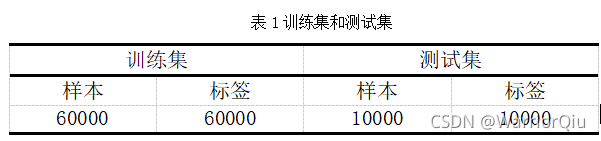
本次实验数据集一共有70000条数据,其中训练集和测试集数量划分如下表1所示:本次实验数据集一共有70000条数据,其中训练集和测试集数量划分如下表1所示:
KNN算法分类的精准度受K值大小影响,如果K值太小,会使预测值不够准确;如果K值太大,又会使预测过程太过复杂。表2列出了不同K值得到的平均精准度,从表2可以看出,当K=3时,在MINIST测试集上识别最优准确率为0.9604。

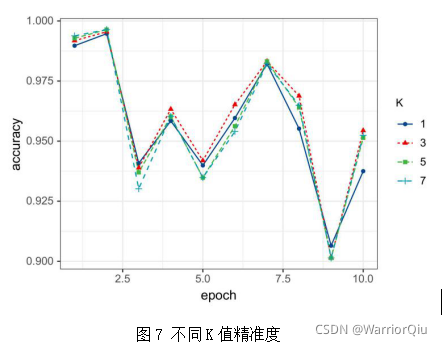
为了更好的呈现不同K值的识别准确率,图7显示了不同K值预测准确率,从图7可以看出,当K=3时,识别准确率优于其他K值。
为了更好地呈现识别手写数字的结果,图8列出了部分识别手写数字失败的样例。从图8中可以看出,有些图像中数字不清晰、有些图像中数字书写不规范,人眼也无法识别,还有些图像中数字与其他数字容易混淆,比如6和9、0和8、0和6、1和7等。

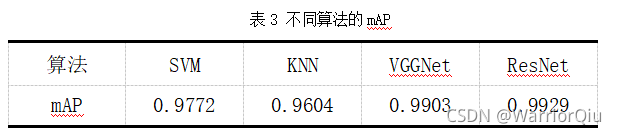
本次实验的四种算法SVM、KNN、VGGNet、ResNet在MNIST测试集上的平均精度如表3所示,由表3可以看出ResNet的mAP高于其他三种算法。
在K=3最优的情况下,四种算法在运行不同次数下,迭代次数与分类精确度的关系如图 9 所示。可以看出,深度学习算法的分类精确度优于机器学习,在机器学习算法中,SVM优于KNN。在第2-10个迭代中,ResNet的精确度明显高于其他三个算法,其精确度随着迭代次数逐渐收敛,准确率也越来越高,并趋于稳定。
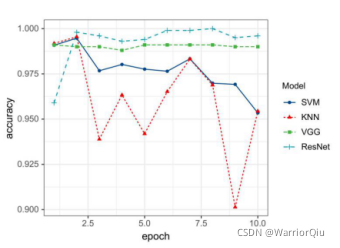
图9 accuracy对比图
四、总结
通过四种算法实现MNIST手写数字识别,实验结果表明,四种方法均能有效识别手写数字。就测试集的分类识别准确率来说,ResNet较优于其他三种算法。