文章目录
问题
各大平台都有长语音转写的服务,但是收费昂贵,而且有次数和时间限制。
因此我想到了一个白嫖的好办法。将长音频根据语句停顿切割得到短音频,使用他们提供的短音频识别服务来识别长音频不是更好吗?粗略计算了下,可以使用的时长为50000分钟,(提供的短音频识别服务次数以及时长远大于长音频)白嫖。
至于视频声音的停顿时间也是很容易得到的。
最后根据文字与文字出现的时间很容易就得到了视频的srt字幕
解决
工程路径:https://download.csdn.net/download/lidashent/15453846
注意字幕导出的地址,自己修改一下,原理都讲清楚了,有需求根据自己的需求改就行了。
有疑问留言,我必解释好吧
思路
- 导出视频声音,根据声音停顿得到短句,同时导出短句的时间信息
- 将长音频切割得到的多个短句文件分别进行语音识别,得到识别文字
- 识别得到的文字与短句的时间信息处理得到视频srt字幕文件
导入srt字幕文件即可得到效果,如图
播放器推荐暴风影音或者迅雷,文字可以调节变色,大小,位置都比较方便。

原先视频是没有字幕的,经过上述处理得到srt文件就如同看字幕电影一样了。
得到的srt文件如图
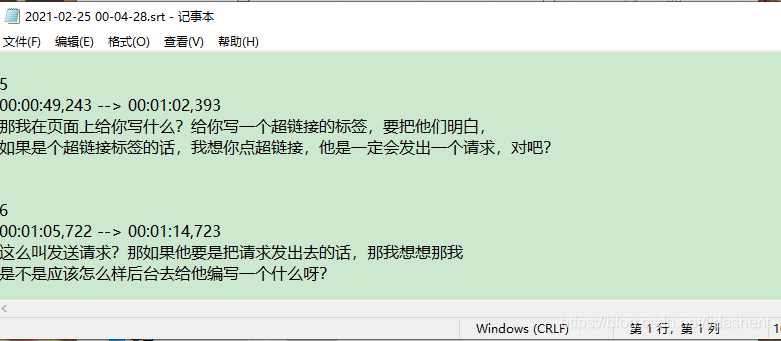
接下来就一步一步开始吧,srt文件格式原理是什么,看我另一篇有关视频声音转为字幕的。那篇使用的长录音转文字接口,优惠力度不大,用几次就没了,所以特意写了这一篇可以白嫖而且时间非常长的,用个几个月都没有问题。
只需要关注srt格式就可以了
https://blog.csdn.net/lidashent/article/details/113987349
导出音频分片,导出音频时间信息
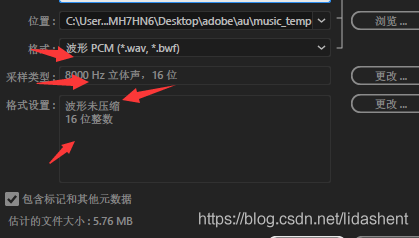
先将视频声音导出,设定标准为16bit,8000hz,这里使用的au,adobe audition
(—解释—:)【这是短语音识别要求的】
(—解释—:)【这里需要注意的是,虽然切片对人声进行了保留,但是不乏切割到的音频有的是空白,因此需要一个大小判断,低于100kb可以默认为无声,当然条件自己设定吧】
自动识别停顿,对声音切片
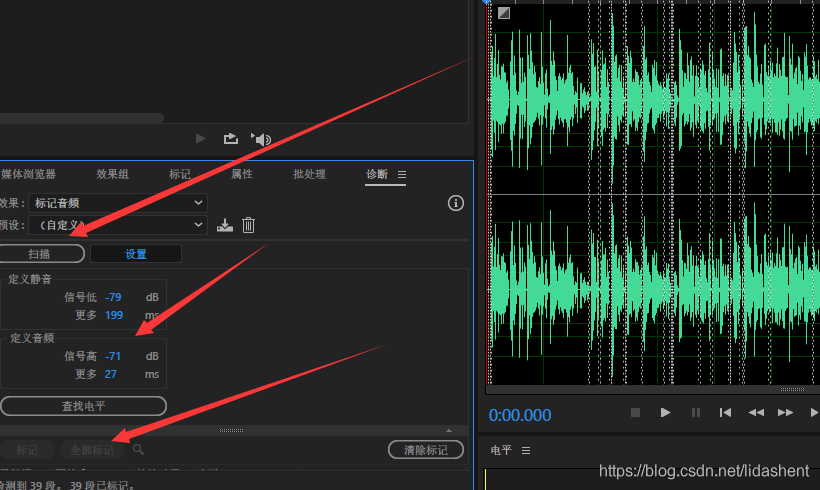
效果-诊断-标记音频
设置静默阈值,时长越低分片越多,反向同理
声音阈值,时长越长,分片越少,反向同理
设置合适的阈值,注意自动分割的音频片,极限60s,最好不要超过45s
有音频片长度过长也不行,影响字幕观看,你不想看视频的时候视频上都是字幕吧?我一般看到分片间隔差不多10s就够了,这意味着10s左右会自动切换到下一个视频字幕信息
然后点击扫描,
再点击全部标记,就会显示灰色的标记信息
点击到标记条,可以看到分片信息,
ctrl a全选,然后右键选择导出音频,导出csv
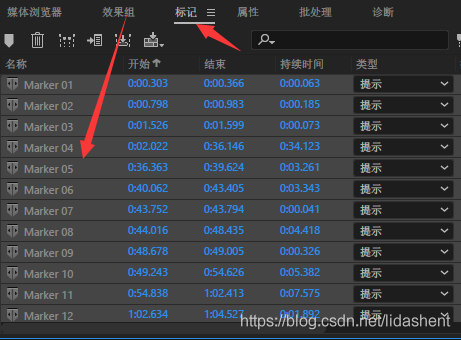
得到声音的发音时间,得到这段发音时间内的音频

编写函数,对语音分片实现语音识别,得到文字信息
import os
from aip import AipSpeech#这是百度的aip包,
def get_need_music_file(file_path):
file_list=os.listdir(file_path)
real_list=[]
for i in file_list:
if i[-3:]=="wav":
real_list.append(i)
real_name_sort=sorted(real_list)
file_real=[]
for i in real_name_sort:
new_path=file_path+"\\"+i
if os.path.getsize(new_path)/1024<100:
pass
else:
file_real.append(new_path)
return file_real
def get_txt(file_music):
#百度语音的id,key,申请一个,5万条呢
APP_ID = ''
API_KEY = ''
SECRET_KEY = ''
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
get_voice_file = open(file_music, "rb")
voice_text = get_voice_file.read()
# try:
result = client.asr(voice_text, 'wav', 16000, {'dev_pid': '1537', })
# print(result)
if result['err_no'] == 0:
return result['result'][0]
else:
return "识别错误"
对csv文件处理,得到编写srt文件需要的信息
import time_format
import datetime
def get_csv_info(file_path):
a=open(file_path,'r', encoding='UTF-8')
basic_data=a.read()
b=basic_data.split("\n")
b=b[1:]
music_name=[]
music_start=[]
music_ed=[]
for i in b:
if i:
new_list=i.split("\t")
# print(new_list)
music_name.append(new_list[0])
start_time,stop_time=time_format.get_start_stop_time(new_list[1],new_list[2])
music_start.append(start_time)
music_ed.append(stop_time)
dic_name_to_start=dict(zip(music_name,music_start))
dic_start_to_long=dict(zip(music_start,music_ed))
return dic_name_to_start,dic_start_to_long
def split_txt(a):
flag_word=[",","。","?","!"]
basic_line=28
basic_step=10
word=""
loc_rec=0
len_rec=len(a)
temp_data=a
while(len_rec>basic_line+basic_step):
a=temp_data
#设定的基础线会影响语句长度显示
for i in flag_word:
if i in a[basic_line:basic_line+basic_step]:
temp_len=a[basic_line:basic_line+basic_step]
loc_rec=temp_len.index(i)
break
word=word+a[:basic_line+loc_rec+1]+"\n"
temp_data=a[basic_line + loc_rec+1:]
print(temp_data)
len_rec=len(temp_data)
return word+temp_data
def make_srt(myword,file_name):
# nowTime_str = datetime.datetime.strftime(datetime.datetime.now(), '%Y-%m-%d %H-%M-%S')
path_file = r"C:\Users\Administrator.DESKTOP-KMH7HN6\Desktop\video_text\%s.srt" % (file_name)
f = open(path_file, 'w')
f.write(myword)
f.write('\n')
f.close()
print('已经识别完成,见%s.srt文件'%(file_name))
input("按任意键结束")
处理时间格式的代码
# coding=utf-8
def time_format(a):
basic_format="00:00:00,000"
a=a.replace(".",",")
temp=a.split(",")[1]
if len(temp)<3:
a=a.split(",")[0]+",0"+temp
basic_format_len=len(basic_format)
if len(a)<basic_format_len:
a=basic_format[:-len(a)]+a
return a
def get_hmsmil(a):
mymillis_a=int(a.split(",")[1])
hms_a_basic=a.split(",")[0].split(":")
mys_a=int(hms_a_basic[2])
mym_a=int(hms_a_basic[1])
myh_a=int(hms_a_basic[0])
return myh_a,mym_a,mys_a,mymillis_a
def judg_over(a,b,over):
c=int((a+b)/over)
return c,a+b-over*c
def get_format_time(num):
if len(str(num))>1:
return str(num)
else:
return "0"+str(num)
def get_end_time(a,b):
a_h,a_m,a_s,a_ms=get_hmsmil(a)
b_h,b_m,b_s,b_ms=get_hmsmil(b)
c_h,c_m,c_s,c_ms=get_hmsmil(a)
flag_s_change=0
num_wave=0#数据溢出的波动
if judg_over(a_ms,b_ms,1000)[0]>0:
c_s=judg_over(a_ms, b_ms, 1000)[0]+a_s
c_ms=judg_over(a_ms, b_ms, 1000)[1]
flag_s_change=1
else:
c_ms=a_ms+b_ms
flag_m_change=0
#如果s改变了
#判断分钟是否因此发生改变
if judg_over(c_s, b_s, 60)[0] > 0:
#分钟改变了,重新得到新的分钟,秒也会因此改变
c_m=judg_over(c_s, b_s, 60)[0]+a_m
print(c_m)
c_s=judg_over(c_s, b_s, 60)[1]
flag_m_change=1
else:
#否则
c_s=c_s+b_s
flag_h_change=0
#检测分钟是否发生变化
if judg_over(c_m, b_m, 60)[0] > 0:
#分钟改变了,重新得到新的小时,分钟也会因此改变
c_h=judg_over(c_m, b_m, 60)[0]+a_h
c_m=judg_over(c_m, b_m, 60)[1]
flag_h_change=1
else:
#否则
c_m=c_m+b_m
c_h=c_h+b_h
return c_h,c_m,c_s,c_ms
def get_start_stop_time(a,b):
a=time_format(a)
b=time_format(b)
ed=get_end_time(a,b)
end_time="%s:%s:%s,%s"%(get_format_time(ed[0]),get_format_time(ed[1]),get_format_time(ed[2]),\
get_format_time(ed[3]))
return a,end_time
主文件调用,并主导srt文件生成
# coding=utf-8
import sys
import time
sys.path.append(r"C:\Users\Administrator.DESKTOP-KMH7HN6\AppData\Local\Temp\python_pgm\video_text\baidu")
import csv_info
import time_format
import voice_be_text
import datetime
#如果不输入音频路径,则选择默认路径,其他同理
music_file_path=input("音频路径:").replace("\\",'/')
if music_file_path:
pass
else:
music_file_path=r"C:\Users\Administrator.DESKTOP-KMH7HN6\Desktop\adobe\au\music_temp"
csv_file_path=input("csv路径:").replace("\\",'/')
if csv_file_path:
pass
else:
csv_file_path=r"C:\Users\Administrator.DESKTOP-KMH7HN6\Desktop\adobe\au\music_temp\csv_temp\标记.csv"
srt_file_name=input("srt文件命名:")
#如果不为要生成的srt文件命名,则根据时间自动命名
if srt_file_name:
pass
else:
nowTime_str = datetime.datetime.strftime(datetime.datetime.now(), '%Y-%m-%d %H-%M-%S')
srt_file_name=nowTime_str
my_csv_name,my_csv_start=csv_info.get_csv_info(csv_file_path)
print(my_csv_name)
print(my_csv_start)
real_music=voice_be_text.get_need_music_file(music_file_path)
print(real_music)
all_len=len(real_music)
#已根据大小过滤空白的音频文件
print("无效音频已过滤,当前音频切割%d个,开始识别..."%(all_len))
i_num=1
error_file=0
global all_srt
all_srt=""
def put_txt_srt(i,myword,num):
global all_srt
file_name = i.split("\\")[-1][:-4]
print(file_name)
mystart_time=my_csv_name[file_name]
mystop_time=my_csv_start[mystart_time]
newword = str(num)+"\n"+mystart_time + " --> " + mystop_time + '\n' + csv_info.split_txt(myword) + "\n\n\n"
all_srt+=newword
for i in real_music:
print(i)
time.sleep(1)
word_result=voice_be_text.get_txt(i)
# word_result ="aaaaaaaaaaaaa"*3
if word_result!="识别错误":
put_txt_srt(i,word_result,i_num)
else:
error_file+=1
print("\n"+"--"*30+"已经完成了%.2f"%(i_num*100/all_len)+"--"*20)
i_num+=1
print(all_srt)
# all_srt="""00:01:02,430 --> 00:01:03,610
# 庄 你这次再把轮胎弄坏"""
print("输出完成,共有音频切割%d个,识别错误%d个"%(all_len,error_file))
csv_info.make_srt(all_srt,srt_file_name)
输出会附带进度信息。
得到srt文件导入对应视频就可以看到字幕效果了。