ECCV 2018和ApolloScape
目前,自动驾驶公司主要依赖于激光雷达来检测和识别物体,但相比激光雷达,基于视觉信息(如图像或视频)的3D感知或将大大降低成本。
此次ECCV 2018以解决潜在的计算机视觉为挑战,赛事主要包括基于视觉的细粒度车道标记分割、实时自定位及3D汽车实例了解等3大内容,所有参赛者都将基于ApolloScape提供的数据集进行挑战
目前的自动驾驶开发测试中,鲜少有团队有能力开发并维持一个适用的自动驾驶平台,长期的、系统的收集和标注新数据,因此行业亟需一个数据量充沛、标注详实的自动驾驶专用数据平台。
2018年3月,百度大规模自动驾驶数据集ApolloScape应需开放,致力于为全世界自动驾驶技术研究者提供更为实用的数据资源及评估标准。ApolloScape是百度在2017年创立的Apollo开放平台的一部分,目前采集图像来自于中国的不同城市,比如北京、上海和深圳等。
自动驾驶公开数据集比较
为了刻画高细粒度的静态3D世界,ApolloScape使用移动激光雷达扫描仪器从Reigl收集点云。这种方法产生的三维点云要比Velodyne产生点云更精确、更稠密。在采集车车顶上安装有标定好的高分辨率相机以每一米一帧的速率同步记录采集车周围的场景。而且,整个系统配有高精度GPS和IMU,相机的实时位姿都可以被同步记录。据介绍,ApolloScape是目前行业内环境最复杂、标注最精准、数据量最大的三维自动驾驶公开数据集。ApolloScape的标注精细度上超过同类型的KITTI,Cityscapes数据集,也超过UC Berkley最新发布的BDD100K。
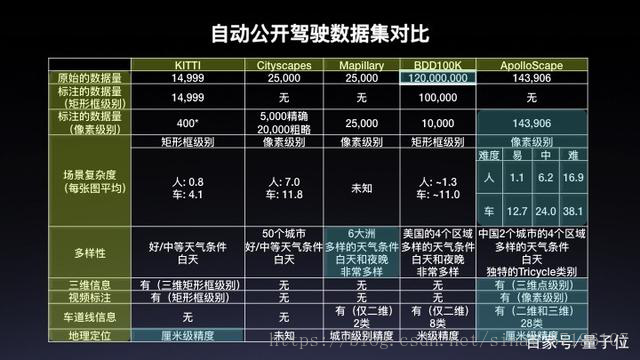
目前,ApolloScape已经开放了14.7万帧的像素级语义标注图像,包括感知分类和路网数据等数十万帧逐像素语义分割标注的高分辨率图像数据,以及与其对应的逐像素语义标注,覆盖了来自三个城市的三个站点周围10KM的地域。
而且,每个区域都在不同的天气和光照条件下进行了重复扫描。未来,ApolloSacpe将会发展成为一个不断更新进化的数据集,涵盖更复杂的环境、天气和交通状况,添加更多的传感器来扩充数据的多样性,致力于打造真实世界还原度最高、场景最丰富的仿真平台。未来,来自新的城市的数据标注也会陆续的加入其中。ApolloSacpe计划产出至少20万张图片用于举行不同的挑战赛,其中将会覆盖来自三个城市的5个站点的20KM的道路。
ApolloScape自动驾驶数据集
Apollo开放资源数据集分为以下三大部分:
- 仿真数据集,包括自动驾驶虚拟场景和实际道路真实场景;
- 演示数据集,包括车载系统演示数据,标定演示数据,端到端演示数据,自定位模块演示数据;
- 标注数据集,包括6部分数据集:激光点云障碍物检测分类,红绿灯检测,Road Hackers,基于图像的障碍物检测分类,障碍物轨迹预测,场景解析;
除开放数据外,还配套开放云端服务,包括数据标注平台,训练学习平台以及仿真平台和标定平台,为Apollo开发者提供一整套数据计算能力的解决方案,加速迭代创新。
平台使用教程:https://cloud.tencent.com/developer/article/1063258
Scene Parsing数据集
Scene Parsing数据集是ApolloScape的一部分,它为高级自动驾驶研究提供了一套工具和数据集。场景解析旨在为图像中的每个像素或点云中的每个点分配类(语义)标签。它是2D / 3D场景最全面的分析之一。鉴于自动驾驶的兴起,环境感知有望成为关键的技术部分。百度公司提供的ApolloScape数据集将包括具有高分辨率图像和每像素注释的RGB视频,具有语义分割的测量级密集3D点,立体视频和全景图像。
数据集定义
类别定义
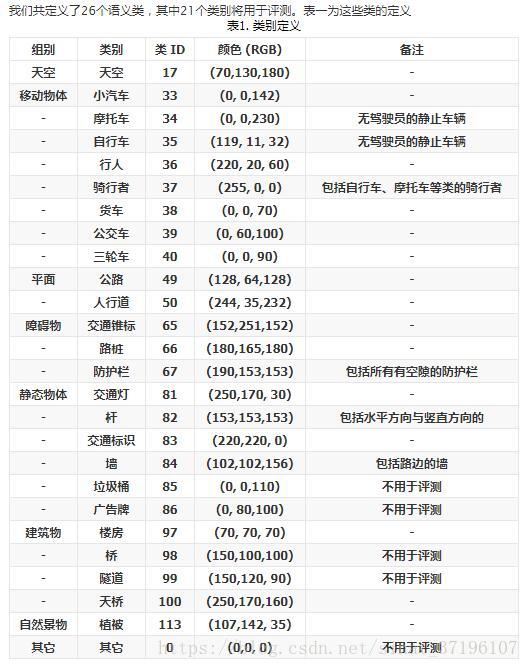
数据摘要
我们的数据集中的图像帧由我们的采集系统每分钟收集一次,分辨率为3384 x 2710.预计发布的数据集将包括具有相应像素级注释和姿势信息的200K图像帧。实例级注释可用于数据集的子集。还将提供静态背景的深度图。
数据集分为三个子集,分别用于训练,验证和测试。未提供用于测试图像的语义注释。用于测试图像的地面实况注释中的所有像素都标记为255.将很快提供包含训练,验证和测试子集的图像列表的文件。
- 训练RGB图像总数:17,062
- 验证深度图像总数:17,062
- 测试RGB图像的总数:1,973
- 测试深度图像总数:1,973
- 类别总数:27
- 用于评测的类别总数:21
- 图像分辨率:3384 x 2710
数据规范
在第一版数据集中,我们提供了 17062 张图像和相对应的语义标注与深度信息,用于设计算法和训练模型。train.txt 包括了这些图像的相对路径。每个图片的名字由时间戳和相机编号组成,如 170908_06190754_Camera_5。训练集的目录结
构如下:
train_image/ // 训练集图像根目录
|-- image
| |-- Record014
| | |-- Camera 5
| | | |-- 170908_061910754_Camera_5.jpg
| | | |-- ...
| | | |--170908_061912275_Camera_5.jpg
| | |-- Camera 6
| | | |-- 170908_061910754_Camera_6.jpg
| | | |-- ...
| |-- :
| |-- Record031
| | |-- Camera 5
| | | |-- ...
train_depth/ // 训练集深度图像根目录
|-- depth
| |-- Record014
| | |-- Camera 5
| | | |-- 170908_061910754_Camera_5.png
| | | |-- ...
| | | |--170908_061912275_Camera_5.png
| | |-- Camera 6
| | | |-- 170908_061910754_Camera_6.png
| | | |-- ...
| |-- :
| |-- Record031
| | |-- Camera 5
| | | |-- ...
train_label/ //训练集标注根目录
|-- image
| |-- Record014
| | |-- Camera 5
| | | |-- 170908_061910754_Camera_5.png
| | | |-- ...
| | | |--170908_061912275_Camera_5.png
| | |-- Camera 6
| | | |-- 170908_061910754_Camera_5.png
| | | |-- ...
| |-- :
| |-- Record031
| | |-- Camera 5
| | | |-- ...附:
数据集使用手册:http://data.apollo.auto/static/pdf/apollo_scape_label.pdf
平台使用教程:https://cloud.tencent.com/developer/article/1063258
样例数据下载