本人大三真皮沙发又来了,继上次写了一个爬取捞月狗直播的爬虫后,笔者觉得自己有必要写一个原创的爬虫小框架。可是大家都知道,一个成熟的框架是十分困难的,所以笔者就尝试了不同的数据的抓取方法。在不同的方法中,找到最方便最快捷的爬虫方式。
在上次的爬虫中,抓取的数据主要用到的是第三方的Beautifulsoup库,然后对每一个具体的数据在网页中的selecter来找到它,每一个类别便有一个select方法。对网页有过接触的都知道很多有用的数据都放在一个共同的父节点上,只是其子节点不同。在上次爬虫中,每一类数据都要从其父类(包括其父节点的父节点)上往下寻找ROI数据所在的子节点,这样就会使爬虫很臃肿,因为很多数据有相同的父节点,每次都要重复的找到这个父节点。这样的爬虫效率很低。
因此,笔者在上次的基础上,改进了一下爬取的策略,笔者以实例来描述。
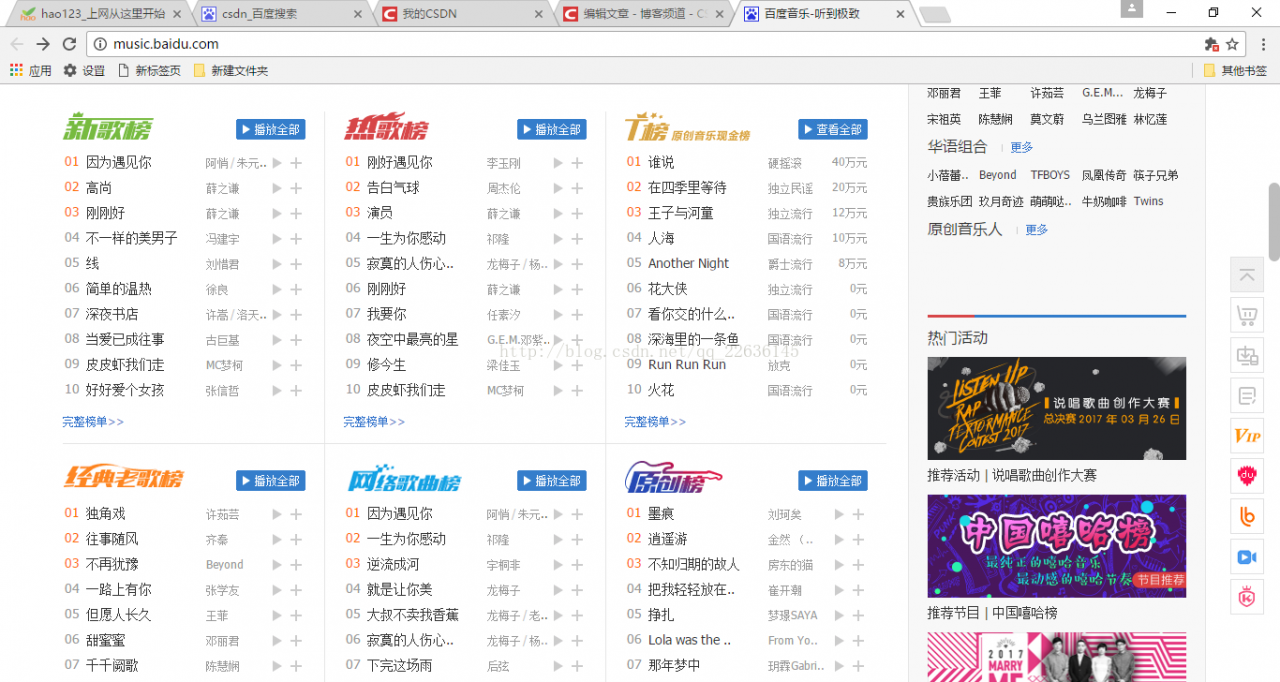
如图,笔者此次爬取的是百度音乐的页面,所爬取的类容是上面榜单下的所有内容(歌曲名,歌手,排名)。如果按照上次的爬虫的方法便要写上三个select方法,分别抓取歌曲名,歌手,排名,但笔者观察得知这三项数据皆放在一个li标签内,如图:
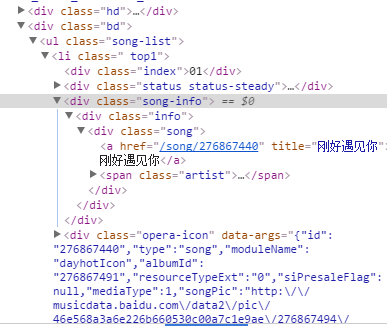
这样我们是不是直接抓取ul标签,再分析其中的数据便可得到全部数据了?答案是,当然可以。
但Beaufulsoup不能直接提供这样的方法,但python无所不能,python里面自带的re模块是我见过最迷人的模块之一。它能在字符串中找到我们让我们roi的区域,上述的li标签中包含了我们需要的歌曲名,歌手,排名数据,我们只需要在li标签中通过re.findall()方法,便可找到我们需要的数据。这样就能够大大提升我们爬虫的效率。
我们先来直接分析代码:
def parse_one_page(html):
soup = BeautifulSoup(html, 'lxml')
data = soup.select('div.ranklist-wrapper.clearfix div.bd ul.song-list li')
pattern1 = re.compile(r'<li.*?<div class="index">(.*?)</div>.*?title="(.*?)".*?title="(.*?)".*?</li>', re.S)
pattern2 = re.compile(r'<li.*?<div class="index">(.*?)</div>.*?title="(.*?)".*?target="_blank">(.*?)</a>', re.S)
wants = []
for item in data:
# print(item)
final = re.findall(pattern1, str(item))
if len(final) == 1:
# print(final[0])
wants.append(final[0])
else:
other = re.findall(pattern2, str(item))
# print(other[0])
wants.append(other[0])
return wants
上面的代码是我分析网页数据的全部代码,这里不得不说python语言的魅力,数十行代码便能完成java100行的任务,C/C++1000行的任务。上述函数中,笔者首先通过Beautifulsoup得到该网页的源代码,再通过select()方法得到所有li标签中的数据。
到这里,这个爬虫便要进入到最重要的环节了,相信很多不懂re模块的童靴们有点慌张,在这里笔者真的是强烈推荐对python有兴趣的童靴们一定要学习这个非常重要的一环。首先,我们知道re的方法大多只针对string型数据,因此我们调用str()方法将每个list中的数据(即item)转换为string型。然后便是定义re的pattern了,这是个稍显复杂的东西,其中主要用到re.compile()函数得到要在string中配对的pattern,这里笔者便不累述了,感兴趣的童靴可以去网上查阅一下资料。
上述代码中,笔者写了两个pattern,因为百度音乐的网页里,li标签有两个结构,当用一个pattern在li中找不到数据时,便使用另一个pattern。关于re.findadd()方法,它会返回一个list,里面装着tuple,但其实我们知道我们找到的数据就是list[0],再将每个数据添加到另一个List中,让函数返回。
相信很多看到这里的小伙伴已经云里雾里,无奈笔者对re板块也知道的不多,对python感兴趣的同学可以查阅相关资料再来看一下代码,相信能够如鱼得水。完整的代码如下:
import requests
from bs4 import BeautifulSoup
import re
def get_one_page(url):
wb_data = requests.get(url)
wb_data.encoding = wb_data.apparent_encoding
if wb_data.status_code == 200:
return wb_data.text
else:
return None
def parse_one_page(html):
soup = BeautifulSoup(html, 'lxml')
data = soup.select('div.ranklist-wrapper.clearfix div.bd ul.song-list li')
pattern1 = re.compile(r'<li.*?<div class="index">(.*?)</div>.*?title="(.*?)".*?title="(.*?)".*?</li>', re.S)
pattern2 = re.compile(r'<li.*?<div class="index">(.*?)</div>.*?title="(.*?)".*?target="_blank">(.*?)</a>', re.S)
wants = []
for item in data:
# print(item)
final = re.findall(pattern1, str(item))
if len(final) == 1:
# print(final[0])
wants.append(final[0])
else:
other = re.findall(pattern2, str(item))
# print(other[0])
wants.append(other[0])
return wants
if __name__ == '__main__':
url = 'http://music.baidu.com/'
html = get_one_page(url)
data = parse_one_page(html)
for item in data:
dict = {
'序列': item[0],
'歌名': item[1],
'歌手': item[2]
}
print(dict)
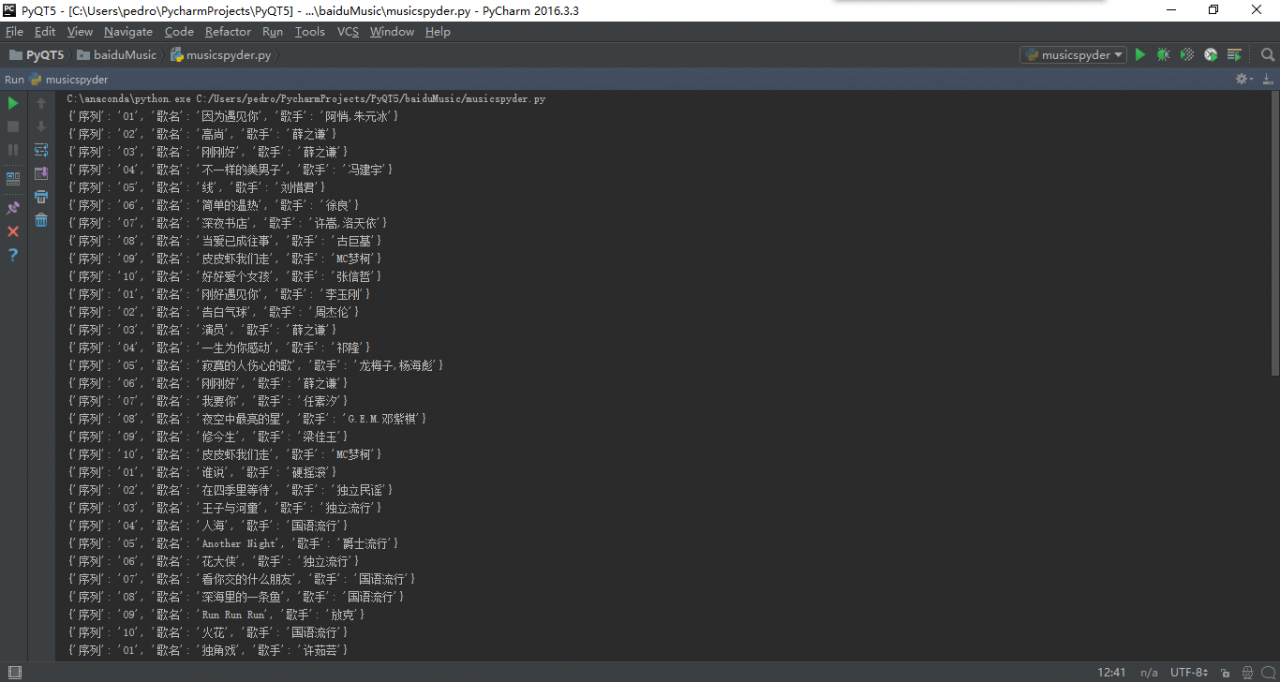
最后我们看到的输出结果如下:
好了,笔者今天就到这里了。希望喜欢python的萌新能够快速实现自己的spider,也希望一些大神们能够看到这篇文章时不吝赐教。