参考:
https://blog.csdn.net/hczjb/article/details/87915207
https://www.cnblogs.com/ajianbeyourself/p/11259984.html
https://blog.csdn.net/lixiangchibang/article/details/84793901
https://www.codercto.com/a/44517.html
lucene从4开始大量使用的数据结构是FST(Finite State Transducer)。FST有两个优点:1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;2)查询速度快。O(len(str))的查询时间复杂度。
Maven:
<!--字典数据结构-FST(Finite State Transducers) -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>5.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>5.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>5.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-smartcn</artifactId>
<version>5.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>5.3.1</version>
</dependency>
数据结构
FST 是一种类似于Trie或自动机的数据结构,所以在学习之前您一定要对自动机有一个简单的了解,鉴于篇幅,自动机的内容本文不做介绍。
在查找最优的Value时,会用到求最短路径的Dijikstra算法,但建图过程于此无关。
存储FST
FST 本身并不要求输入要按照字典序从小到大,FST只是一个映射,只能成为我们应用程序的一个工具,所以决不能让这个工具占用我们过多宝贵的内存空间,因此我们要把不用的节点存入到文件中。所以他的存储文件也非常小,几百万的数据也只有几kb大小。
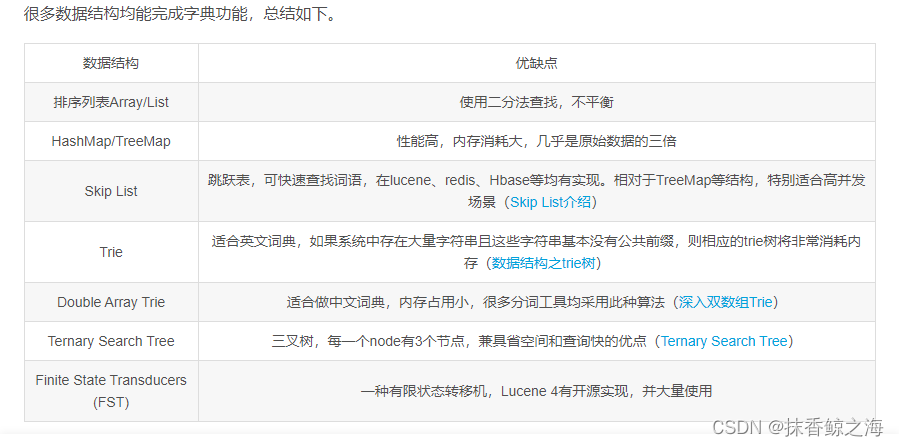
常用字典数据结构
代码实现:
package com.naixin.clickhouse.utils;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.core.WhitespaceTokenizer;
import org.apache.lucene.analysis.synonym.SynonymFilterFactory;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.util.FilesystemResourceLoader;
import org.apache.lucene.store.DataInput;
import org.apache.lucene.store.InputStreamDataInput;
import org.apache.lucene.util.*;
import org.apache.lucene.util.fst.*;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.Arrays;
import java.util.Map;
/**
* @author lgn
* @version 1.0
* @date 2022/1/13 9:44
*/
public class FSTUtils {
/**
* 创建fst文件
* 创建存3百万个数字也只有2kb的文件那么大
* @throws IOException
*/
public static void FSTBuilder() throws IOException {
String pathname = "C:\\Users\\liangguannan\\Desktop\\PDF\\test.fst";
FST<CharsRef> fst=null;
File file = new File(pathname);
CharSequenceOutputs charSequenceOutputs = CharSequenceOutputs.getSingleton();
Builder<CharsRef> builder = new Builder<CharsRef>(FST.INPUT_TYPE.BYTE1, charSequenceOutputs);
IntsRefBuilder intsRefBuilder = new IntsRefBuilder();
for (int i=0;i<3000000;i++){
if (i!=2002300){
String key="key:"+i;
builder.add(Util.toIntsRef(new BytesRef(key), intsRefBuilder), new CharsRef("value:"+i));
}else {
builder.add(Util.toIntsRef(new BytesRef("kg"), intsRefBuilder), new CharsRef("value:"+i));
}
}
fst = builder.finish();
fst.save(file.toPath());
}
/**
* 读取数据
* FST,不但能 共享前缀 还能 共享后缀 。不但能判断查找的key是否存在,还能给出响应的输入output。
* 它在时间复杂度和空间复杂度上都做了最大程度的优化,使得Lucene能够将Term Dictionary完全加载到内存,快速的定位Term找到响应的output(posting倒排列表)。
* @param documentFileName
* @throws IOException
*/
public static void FSTRead(String documentFileName) throws IOException {
String fstFileName = "C:\\Users\\liangguannan\\Desktop\\PDF\\test.fst";
// 开始时间
long stime = System.currentTimeMillis();
File fstFile = new File(fstFileName);
FST<CharsRef> fst = FST.read(fstFile.toPath(), CharSequenceOutputs.getSingleton());
int n=0,m=0;
CharsRef output = Util.get(fst, new BytesRef(documentFileName));
if (output == null) {
n++;
} else {
m++;
Arrays.asList(output.toString().split("\\|"));
}
System.out.println(documentFileName);
System.out.println("FST returned null: " + n);
System.out.println("Found match: " + m);
// 结束时间
long etime = System.currentTimeMillis();
// 计算执行时间
System.out.printf("执行时长:%d 毫秒.", (etime - stime));
}
public static void main(String[] args) {
try {
FSTBuilder();
FSTRead("kg");
} catch (IOException e) {
e.printStackTrace();
}
}
}
版权声明:本文为u010797364原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。