数据库语言-SQL
概览SQL语言
SQL语言概述
SQL语言是集DDL、DML和DCL于一体的数据库语言
SQL语言主要由以下9个单词引导的操作语句来构成,但每一种语句都能表
达复杂的操作请求
DDL语句引导词:Create(建立),Alter(修改),Drop(撤消),模式的定义和删除,包括定义Database,Table,View,Index,完整性约束条件等,也包括定义对象(RowType行对象,Type列对象)。
DML语句引导词:Insert ,Delete, Update, Select,各种方式的更新与检索操作,如直接输入记录,从其他Table(由SubQuery建立)输入。各种复杂条件的检索,如连接查找,模糊查找,分组查找,嵌套查找等,各种聚集操作,求平均、求和、…等,分组聚集,分组过滤等。
DCL语句引导词:Grant,Revoke,安全性控制:授权和撤消授权。
交互式SQL、嵌入式SQL、动态SQL等
利用SQL语言建立数据库
建立数据库包括两件事:定义数据库和表(使用DDL),向表中追加元组(使用DML)。
DDL: Data Definition Language
创建数据库(DB)—Create Database
创建DB中的Table(定义关系模式)—Create Table
定义Table及其各个属性的约束条件(定义完整性约束)
定义View (定义外模式及E-C映像)
定义Index、Tablespace… …等(定义物理存储参数)
上述各种定义的撤消与修正
数据库(Database)是若干具有相互关联关系的Table/Relation的集合
create create database database 数据库名;
创建Table
create table简单语法形式:
Create table 表名( 列名 数据类型 [Primary key|Unique] [Not null] [, 列名 数据类型 [Not null] , … ]) ;
“ [ ] ”表示其括起的内容可以省略,“ | ” 表示其隔开的两项可取其一
Primary key: 主键约束。每个表只能创建一个主键约束。
Unique: 唯一性约束(即候选键)。可以有多个唯一性约束。
Not null: 非空约束。是指该列允许不允许有空值出现,如选择了Not null表明该列不允许有空值出现。
语法中的数据类型在SQL标准中有定义
示例:定义学生表 Student
Create Table Student ( S# char(8) not null , Sname char(10), Ssex char(2), Sage integer, D# char(2), Sclass char(6) );
DML: Data Manipulation Language
向Table中追加新的元组:Insert
修改Table中某些元组中的某些属性的值: Update
删除Table中的某些元组: Delete
对Table中的数据进行各种条件的检索: Select
DML通常由用户或应用程序员使用,访问经授权的数据库
insert into简单语法形式:
insert into 表名[ (列名 [, 列名 ]… ] values (值 [, 值] , …) ;
values后面值的排列,须与into子句后面的列名排列一致
若表名后的所有列名省略, 则values后的值的排列,须与该表存储中的列名排列一致
示例:追加学生表中的元组
Insert Into Student Values ( ‘98030101’ , ‘张三’, ‘男’, 20, ’03’, ‘980301’);
Insert Into Student ( S#, Sname, Ssex, Sage, D# , Sclass) Values ( ‘98030102’ , ‘张四’, ‘女’, 20, ’03’, ‘980301’);
利用SQL语言进行简单查询
Select 的简单语法形式:
Select 列名 [[, 列名] … ] From 表名 [ Where 检索条件 ] ;
示例:检索学生表中所有年龄小于等于19岁的学生的年龄及姓名
Select Sage, Sname From Student Where Sage <= 19;
检索条件的书写
用 and , or, not 来表示, 同时也要注意运算符的优先次序及括弧的使用。
示例:检索教师表中所有工资少于1500元或者工资大于2000元 并且是03系的教师姓名?
Select Tname From Teacher Where (Salary < 1500 or Salary > 2000) and D# = ’03’;
结果唯一性问题
关系模型不允许出现重复元组。但现实DBMS,却允许出现重复元组,但也允许无重复元组。
在Table中要求无重复元组是通过定义Primary key或Unique来保证的;而在检索结果中要求无重复元组, 是通过DISTINCT保留字的使用来实现的。
示例:在选课表中,检索成绩大于80分的所有学号
Select DISTINCT S# From SC Where Score > 80;
//重复元组被DISTINCT过滤掉,只保留一份
结果排序问题
DBMS可以对检索结果进行排序,可以升序排列,也可以降序排列。Select语句中结果排序是通过增加order by子句实现的
order by 列名列名 [asc | desc]
意义为检索结果按指定列名进行排序,若后跟asc或省略,则为升序;若后跟desc, 则为降序
示例:检索002号课大于80分的所有同学学号并按成绩由高到低顺序显示
Select S# From SC Where C# = ‘002’ and Score > 80 Order By Score DESC ;
模糊查询问题
比如检索姓张的学生,检索张某某;这类查询问题,Select语句是通过在检索条件中引入运算符like来表示的
含有like运算符的表达式
列名 [not] like “字符串”
找出匹配给定字符串的字符串。其中给定字符串中可以出现%, 等匹配符.
匹配规则:
“%” 匹配零个或多个字符
“” 匹配任意单个字符
“ \ ” 转义字符,用于去掉一些特殊字符的特定含义,使其被作为普通字符看待, 如用 “%”去匹配字符%,用_ 去匹配字符_
检索所有姓张的学生学号及姓名
Select S#, Sname From Student Where Sname Like ‘张%’ ;
利用SQL语言进行多表联合查询
多表联合查询
多表联合检索可以通过连接运算来完成,而连接运算又可以通过广义笛卡尔积后再进
行选择运算来实现。
Select 的多表联合检索语句
Select 列名 [ [, 列名] … ] From 表名1, 表名2, … Where 检索条件 ;
多表连接时,如两个表的属性名相同,则需采用表名. 属性名方式来限定该属性是属于哪一个表
示例:按‘数据库’课成绩由高到低顺序显示所有同学姓名(三表连接)
Select Sname From Student, SC, Course Where Student.S# = SC.S# and SC.C# = Course.C# and Cname = ‘数据库’ Order By Score DESC;
重名之处理
连接运算涉及到重名的问题,如两个表中的属性重名,连接的两个表重名(同一表的连接)等,因此需要使用别名以便区分
select中采用别名的方式
Select 列名 as 列别名 [ [, 列名 as 列别名] … ] From 表名1 as 表别名1, 表名2 as 表别名2, … Where 检索条件 ;
上述定义中的as 可以省略,当定义了别名后,在检索条件中可以使用别名来限定属性
示例:求年龄有差异的任意两位同学的姓名
Select S1.Sname as Stud1, S2.Sname as Stud2 From Student S1, Student S2 Where S1.Sage > S2.Sage ;
利用SQL语言进行增-删-改
单一元组新增命令形式:插入一条指定元组值的元组
insert into 表名 [(列名[,列名]…)] values (值 [,值]…);
批数据新增命令形式:插入子查询结果中的若干条元组。待插入的元组由子查询给出。
insert into 表名 [(列名[,列名]…)] 子查询;
示例:单一元组新增
Insert Into Teacher (T#, Tname, D#, Salary) Values (“005”, “阮小七”, “03”, “1250”);
示例:批元组新增新建立Table: St(S#, Sname), 将检索到的满足条件的同学新增到该表中
Insert Into St (S#, Sname) Select S#, Sname From Student Where Sname like ‘%伟 ’ ;
注意:当新增元组时,DBMS会检查用户定义的完整性约束条件等,如不符合完整性约束条件,则将不会执行新增动作(将在后面介绍)。
元组删除Delete命令: 删除满足指定条件的元组
Delete From 表名 [ Where 条件表达式] ;
示例:删除自动控制系的所有同学
Delete From Student Where D# in ( Select D# From Dept Where Dname = ‘自动控制’);
元组更新Update命令: 用指定要求的值更新指定表中满足指定条件的
元组的指定列的值
Update 表名 Set 列名 = 表达式 | (子查询) [ [ , 列名 = 表达式 | (子查询) ] … ] [ Where 条件表达式] ;
如果Where条件省略,则更新所有的元组。
示例:将所有计算机系的教师工资上调10%
Update Teacher Set Salary = Salary * 1.1 Where D# in ( Select D# From Dept Where Dname = ‘计算机’);
利用SQL语言修正与撤销数据库
修正基本表的定义
alter table tablename
[add {colname datatype, …}] 增加新列
[drop {完整性约束名}] 删除完整性约束
[modify {colname datatype, …}] 修改列定义
示例:在学生表Student(S#,Sname,Ssex,Sage,D#,Sclass)基础上增加二列Saddr, PID
Alter Table Student Add Saddr char[40], PID char[18] ;
示例:将上例表中Sname列的数据类型增加两个字符
Alter Table Student Modify Sname char(10) ;
示例:删除学生姓名必须取唯一值的约束
Alter Table Student Drop Unique( Sname );
撤消基本表
drop table 表名
示例:撤消学生表Student
Drop Table Student;
注意,SQL-delete语句只是删除表中的元组,而撤消基本表droptable的操作是撤消包含表格式、表中所有元组、由该表导出的视图等相关的所有内容,所以使用要特别注意。
撤消数据库
drop database 数据库名;
示例:撤消SCT数据库
Drop database SCT;
指定当前数据库
use 数据库名;
关闭当前数据库
close 数据库名;
SQL语言之复杂查询与视图
SQL语言之子查询运用
子查询:出现在Where子句中的Select语句被称为子查询(subquery) , 子查询返回了一个集合,可以通过与这个集合的比较来确定另一个查询集合。
三种类型的子查询:(NOT) IN子查询;Some/ All子查询;(NOT) EXISTS子查询。
(NOT) IN子查询
基本语法:
表达式 [not ] in (子查询 )
语法中,表达式的最简单形式就是列名或常数。语义:判断某一表达式的值是否在子查询的结果中。
示例:求既学过001号课程, 又学过002号课程的学生的学号
Select S# From SC Where C# = ‘001’ and S# in ( Select S# From SC Where C# = ‘002’ ) ;
示例:列出没学过李明老师讲授课程的所有同学的姓名?
Select Sname From Student Where S# not in ( Select S# From SC, Course C, Teacher T Where T.Tname = ‘李明’ and SC.C# = C.C#
and T.T# = C.T# );
带有子查询的Select语句区分为内层和外层,非相关子查询:内层查询独立进行,没有涉及任何外层查询相关信息的子查询。相关子查询:内层查询需要依靠外层查询的某些参量作为限定条件才能进行的子查询。外层向内层传递的参量需要使用外层的表名或表别名来限定。
示例:求学过001号课程的同学的姓名
Select Sname From Student Stud Where S# in ( Select S# From SC Where S# = Stud.S# and C# = ‘001’ ) ;
注意:相关子查询只能由外层向内层传递参数,而不能反之;这也称为变量的作用域原则。
some / all子查询
基本语法:
表达式 比较运算符 some|all (子查询)
语义:将表达式的值与子查询的结果进行比较:
如果表达式的值至少与子查询结果的某一个值相比较满足关系,则 some (子查询) 的结果便为真;
如果表达式的值与子查询结果的所有值相比较都满足关系,则all (子查询)的结果便为真;
示例:找出001号课成绩不是最高的所有学生的学号
Select S# From SC Where C# = “001” and Score < some ( Select Score From SC Where C# = “001” );
示例:找出所有课程都不及格的学生姓名(相关子查询)
Select Sname From Student Where 60 > all ( Select Score From SC Where S# = Student.S# );
如下两种表达方式含义是相同的
表达式 = some (子查询)
表达式 in (子查询)
与notin等价的是
表达式 <> all (子查询)
(NOT) EXISTS 子查询
基本语法:
[not] Exists (子查询)
语义:子查询结果中有无元组存在
示例:列出没学过李明老师讲授任何一门课程的所有同学的姓名
Select Sname From Student Where not exists ( Select * From Course, SC, Teacher Where Tname=‘李明’ and Course.T# =Teacher.T# and Course.C# = SC.C# and S# = Student.S# );
利用SQL语言进行结果计算与聚集计算
结果计算
Select-From-Where语句中,Select子句后面不仅可是列名,而且可是一些计算表达式或聚集函数,表明在投影的同时直接进行一些运算
Select 列名 | expr | agfunc(列名) [[, 列名 | expr | agfunc(列名) ] … ] From 表名1 [, 表名2 … ] Where 检索条件 ] ;
expr可以是常量、列名、或由常量、列名、特殊函数及算术运算符构成的算术运算式。特殊函数的使用需结合各自DBMS的说明书
agfunc()是一些聚集函数
示例:依据学生年龄求学生的出生年份,当前是2015年
Select S.S#, S.Sname, 2015 – S.Sage+1 as Syear From Student S;
聚集函数
SQL提供了五个作用在简单列值集合上的内置聚集函数agfunc,分别是:COUNT、SUM、AVG、MAX、MIN
示例:求计算机系教师的工资总额
Select Sum(Salary) From Teacher T, Dept Where Dept.Dname = ‘计算机’ and Dept.D# = T.D#;
利用SQL语言进行分组查询与分组过滤
分组:SQL可以将检索到的元组按照某一条件进行分类,具有相同条件值
的元组划到一个组或一个集合中,同时处理多个组或集合的聚集运算。
分组的基本语法:
Select 列名 | expr | agfunc(列名) [[, 列名 | expr | agfunc(列名) ] … ] From 表名1 [, 表名2 … ] [ Where 检索条件 ] [ Group by 分组条件 ] ;
分组条件可以是 列名1, 列名2, …
示例: 求每一个学生的平均成绩
Select S#, AVG(Score) From SC Group by S#;
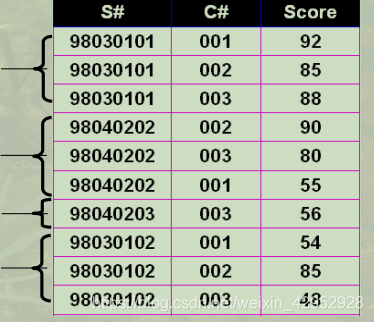
聚集函数是不允许用于Where子句中的:Where子句是对每一元组进行条件过滤,而不是对集合进行条件过滤。
分组过滤:若要对集合(即分组)进行条件过滤,即满足条件的集合/分组留下,不满足条件的集合/分组剔除。
Having子句,又称分组过滤子句。需要有Groupby子句支持,换句话说,没有Groupby子句,便不能有Having子句。
Select 列名 | expr | agfunc(列名) [[, 列名 | expr | agfunc(列名) ] … ] From 表名1 [, 表名2 … ]
[ Where 检索条件 ]
[ Group by 分组条件 [ Having 分组过滤条件] ] ;
示例:求不及格课程超过两门的同学的学号
Select S# From SC Where Score < 60 Group by S# Having Count()>2;
示例:求有两门以上不及格课程同学的学号及其平均成绩
Select S#, Avg(Score) From SC
Where S# in
( Select S# From SC
Where Score < 60
Group by S# Having Count()>2 )
Group by S# ;
利用SQL语言实现关系代数操作
SQL语言:并运算 UNION, 交运算INTERSECT, 差运算EXCEPT。
基本语法形式:
子查询 { Union [ALL] | Intersect [ALL] | Except [ALL] 子查询 }
通常情况下自动删除重复元组:不带ALL。若要保留重复的元组,则要带ALL。
假设子查询1的一个元组出现m次,子查询2的一个元组出现n次,则该元组在:
子查询1 Union ALL 子查询2 ,出现m + n次
子查询1 Intersect ALL 子查询2 ,出现min(m,n)次
子查询1 Except ALL 子查询2 ,出现max(0, m – n)次
示例: 假定所有学生都有选课,求没学过002号课程的学生学号
不能写成如下形式:
Select S# From SC Where C# <> ‘002’
可写成如下形式:所有学生 减掉 学过002号课的学生
Select DISTINCT S# From SC EXCEPT Select S# From SC Where C# = ‘002’;
前述语句也可不用EXCEPT的方式来进行
Select DISTINCT S# From SC SC1 Where not exists ( Select * From SC Where C# = ‘002’ and S# = SC1.S#) ;
差运算符Except也没有增强SQL的表达能力,没有Except, SQL也可以用其他方式表达同样的查询需求。只是有了Except更容易表达一些,但增加了SQL语言的不唯一性。
空值是其值不知道、不确定、不存在的值
数据库中有了空值,会影响许多方面,如影响聚集函数运算的正确性,不能参与算术、比较或逻辑运算等。
在SQL标准中和许多现流行的DBMS中,空值被用一种特殊的符号Null来
标记,使用特殊的空值检测函数来获得某列的值是否为空值。
空值检测
is [not ] null
测试指定列的值是否为空值
示例:找出年龄值为空的学生姓名
Select Sname From Student Where Sage is null ;
现行DBMS的空值处理小结
除is[not]null之外,空值不满足任何查找条件
如果null参与算术运算,则该算术表达式的值为null
如果null参与比较运算,则结果可视为false。在SQL-92中可看成unknown
如果null参与聚集运算,则除count(*)之外其它聚集函数都忽略null
SQL的高级语法中引入了内连接与外连接运算,具体形式:
Select 列名 [ [, 列名] … ]From 表名1 [NATURAL]
[ INNER | { LEFT | RIGHT | FULL} [OUTER]] JOIN 表名2
{ ON 连接条件 | Using (Colname {, Colname …}) }
[ Where 检索条件 ] … ;
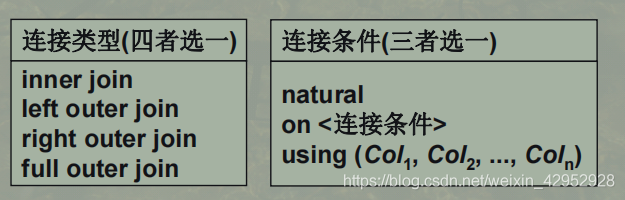
连接中使用 natural
出现在结果关系中的两个连接关系的元组在公共属性上取值相等,且公共属性只出现一次
连接中使用 on <连接条件>
出现在结果关系中的两个连接关系的元组取值满足连接条件,且公共属性出现两次
连接中使用 using (Col1, Col2, …, Coln)
(Col1, Col2, …, Coln)是两个连接关系的公共属性的子集,元组在(Col1, Col2, …, Coln)上取值相等,且(Col1, Col2, …, Coln)只出现一次
示例: 求所有教师的任课情况(没有任课的教师也需列在表中)
Select Teacher. T#, Tname, Cname From Teacher Left Outer Join Course ON Teacher.T# = Course.T# Order by Teacher.T# ASC ;
SQL语言之视图及其应用
对应概念模式的数据在SQL中被称为基本表(Table),而对应外模式的数据称为视图(View)。视图不仅包含外模式,而且包含其E-C映像。
SQL数据库结构
基本表是实际存储于存储文件中的表,基本表中的数据是需要存储的
视图在SQL中只存储其由基本表导出视图所需要的公式,即由基本表产生
视图的映像信息,其数据并不存储,而是在运行过程中动态产生与维护的
对视图数据的更改最终要反映在对基本表的更改上。
定义视图
create view view_name [(列名[,列名] …)]
as 子查询 [with check option]
如果视图的属性名缺省,则默认为子查询结果中的属性名;也可以显式指明其所拥有的列名。
with checkoption指明当对视图进行insert,update,delete时,要检查进行insert/update/delete的元组是否满足视图定义中子查询中定义条件表达式
定义视图,有时可方便用户进行检索操作。
示例:定义视图StudStat, 描述学生的平均成绩、最高成绩,最低成绩等
Create View StudStat(S#, Sname, AvgS, MinS, MaxS, CNT)
as ( Select S#, Sname, AVG(Score), MIN(Score), Max(Score), Count(*)
From Student S, SC Where S.S# = SC.S#
Group by S.S# ) ;
示例:基于视图StudStat检索某一学生平均成绩
Select Sname, AvgS From StudStat Where Sname = ‘张三’ ;
SQL视图更新:是比较复杂的问题,因视图不保存数据,对视图的更新最终要反映到对基本表的更新上,而有时,视图定义的映射不是可逆的。
SQL视图更新的可执行性
如果视图的select目标列包含聚集函数,则不能更新
如果视图的select子句使用了unique或distinct,则不能更新
如果视图中包括了groupby子句,则不能更新
如果视图中包括经算术表达式计算出来的列,则不能更新
如果视图是由单个表的列构成,但并没有包括主键,则不能更新
对于由单一Table子集构成的视图,即如果视图是从单个基本表使用选择、投影操作导出的,并且包含了基本表的主键,则可以更新
撤消视图
Drop View view_name
SQL语言与数据库完整性和安全性
数据库完整性的概念及分类
数据库完整性(DB Integrity)是指DBMS应保证的DB的一种特性–在任何情况下的正确性、有效性和一致性
广义完整性:语义完整性、并发控制、安全控制、DB故障恢复等
狭义完整性:专指语义完整性,DBMS通常有专门的完整性管理机制与程序来处理语义完整性问题。(本讲专指语义完整性)
DBMS允许用户定义一些完整性约束规则(用SQL-DDL来定义)
当有DB更新操作时,DBMS自动按照完整性约束条件进行检查,以确保更新操作符合语义完整性
按约束对象分类
域完整性约束条件
施加于某一列上,对给定列上所要更新的某一候选值是否可以接受进行约束条件判断,这是孤立进行的
关系完整性约束条件
施加于关系/table上,对给定table上所要更新的某一候选元组是否可以接受进行约束条件判断,或是对一个关系中的若干元组和另一个关系
中的若干元组间的联系是否可以接受进行约束条件判断
按约束来源分类
结构约束
来自于模型的约束,例如函数依赖约束、主键约束(实体完整性)、外键约束(参照完整性),只关心数值相等与否、是否允许空值等;
内容约束
来自于用户的约束,如用户自定义完整性,关心元组或属性的取值范围。例如Student表的Sage属性值在15岁至40岁之间等。
按约束状态分类
静态约束
要求DB在任一时候均应满足的约束;例如Sage在任何时候都应满足大于0而小于150(假定人活最大年龄是150)。
动态约束
要求DB从一状态变为另一状态时应满足的约束;例如工资只能升,不能降:工资可以是800元,也可以是1000元;可以从800元更改为1000
元,但不能从1000元更改为800元。
利用SQL语言实现数据库的静态完整性
静态约束
列完整性—域完整性约束
表完整性–关系完整性约束
CREATE TABLE tablename
( ( colname datatype [ DEFAULT { default_constant | NULL} ]
[ col_constr {col_constr. . .} ]
| , table_constr
{, { colname datatype [DEFAULT { default_constant | NULL} ]
[col_constr {col_constr. . .} ]
| , table_constr }
. . . } );
一种域约束类型,对单一列的值进行约束
{ NOT NULL | //列值非空
[ CONSTRAINT constraintname ] //为约束命名,便于以后撤消
{ UNIQUE //列值是唯一
| PRIMARY KEY //列为主键
| CHECK (search_cond) //列值满足条件,条件只能使用列当前值
| REFERENCES tablename [(colname) ]
[ON DELETE { CASCADE | SET NULL } ] } }
引用另一表tablename的列colname的值,如有ON DELETE CASCADE 或ON DELETE SET NULL语句,则删除被引用表的某列值v 时,要将本表该列值为v 的记录删除或列值更新为null;缺省为无操作 。
Col_constr列约束:只能应用在单一列上,其后面的约束如UNIQUE, PRIMARY KEY及search_cond只能是单一列唯一、单一列为主键、和单一列相关。
示例
Create Table Student ( S# char(8) not null unique, Sname char(10),
Ssex char(2) constraint ctssex check (Ssex=‘男’ or
Ssex=‘女’), Sage integer check (Sage>=1 and Sage<150),
D# char(2) references Dept(D#) on delete cascade,
Sclass char(6) );
//假定Ssex只能取{男,女}, 1=<Sage<=150, D#是外键
table_constr表约束
一种关系约束类型,对多列或元组的值进行约束
[ CONSTRAINT constraintname ] //为约束命名,便于以后撤消
{ UNIQUE (colname {, colname. . .}) //几列值组合在一起是唯一
| PRIMARY KEY (colname {, colname. . .}) //几列联合为主键
| CHECK (search_condition) //元组多列值共同满足条件,条件中只能使用同一元组的不同列当前值
| FOREIGN KEY (colname {, colname. . .})//引用另一表tablename的若干列的值作为外键
REFERENCES tablename [(colname {, colname. . .})]
[ON DELETE CASCADE] }
table_constr表约束:是应用在关系上,即对关系的多列或元组进行约束,列约束是其特例
示例
Create Table Course ( C# char(3) , Cname char(12), Chours integer,
Credit float(1) constraint ctcredit check (Credit >=0.0 and
Credit<=5.0 ), T# char(3) references Teacher(T#) on delete
cascade, primary key(C#),
constraint ctcc check(Chours/Credit = 20) );
check中的条件可以是Select-From-Where内任何Where后的语句,包含子查询。
示例
Create Table SC ( S# char(8) check( S# in (select S# from student)) ,
C# char(3) check( C# in (select C# from course)) ,
Score float(1) constraint ctscore check (Score>=0.0 and
Score<=100.0),
Create Table中定义的表约束或列约束可以在以后根据需要进行撤消或追加。撤消或追加约束的语句是 Alter Table(不同系统可能有差异)
ALTER TABLE tblname
[ADD ( { colname datatype [DEFAULT {default_const|NULL} ]
[col_constr {col_constr…} ] | , table_constr }
{, colname …}) ]
[DROP { COLUMN columnname | (columnname {, columnname…})}]
[MODIFY ( columnname data-type
[DEFAULT {default_const | NULL } ] [ [ NOT ] NULL ]
{, columnname . . .})]
[ADD CONSTRAINT constr_name]
[DROP CONSTRAINT constr_name]
[DROP PRIMARY KEY ]
示例:撤消SC表的ctscore约束(由此可见,未命名的约束是不能撤消)
Alter Table SC
DROP CONSTRAINT ctscore;
示例:若要再对SC表的score进行约束,比如分数在0~150之间,则可新增加一个约束。在Oracle中增加新约束,需要通过修改列的定义来完成
Alter Table SC
Modify ( Score float(1) constraint nctscore check (Score>=0.0 and
Score<=150.0) );
断言ASSERTION
一个断言就是一个谓词表达式,它表达了希望数据库总能满足的条件
表约束和列约束就是一些特殊的断言
SQL还提供了复杂条件表达的断言。其语法形式为:
CREATE ASSERTION CHECK
当一个断言创建后,系统将检测其有效性,并在每一次更新中测试更新是否违反该断言。
示例
“每个分行的贷款总量必须小于该分行所有账户的余额总和”
create assertion sum_constraint check
(not exists (select * from branch
where (select sum(amount ) from loan
where loan.branch_name =
branch.branch_name )
= (select sum (balance ) from account
where account.branch_name =
branch.branch_name )))
利用SQL语言实现数据库的动态完整性
动态约束:触发器
触发器Trigger
Create Table中的表约束和列约束基本上都是静态的约束,也基本上都是对单一列或单一元组的约束(尽管有参照完整性),为实现动态约束以及多个元组之间的完整性约束,就需要触发器技术Trigger
Trigger是一种过程完整性约束(相比之下,Create Table中定义的都是非过程性约束),是一段程序,该程序可以在特定的时刻被自动触发执行,比如在一次更新操作之前执行,或在更新操作之后执行
基本语法
CREATE TRIGGER trigger_name BEFORE | AFTER
{ INSERT | DELETE | UPDATE [OF colname {, colname…}] }
ON tablename [REFERENCING corr_name_def {, corr_name_def…} ]
[FOR EACH ROW | FOR EACH STATEMENT]//对更新操作的每一条结果(前者),或整个更新操作完成(后者)
[WHEN (search_condition)] //检查条件,如满足执行下述程序
{ statement //单行程序直接书写,多行程序要用下行方式
| BEGIN ATOMIC statement; { statement;…} END }
触发器Trigger意义:当某一事件发生时(Before|After),对该事件产生的结果(或是每一元组,或是整个操作的所有元组), 检查条件search_condition, 如果满足条件,则执行后面的程序段。条件或程序段中引用的变量可用corr_name_def来限定。
事件:BEFORE | AFTER { INSERT | DELETE | UPDATE …}
当一个事件(Insert, Delete, 或Update)发生之前Before或发生之后After触发
操作发生,执行触发器操作需处理两组值:更新前的值和更新后的值,这两个值由corr_name_def的使用来区分
corr_name_def的定义
{ OLD [ROW] [AS] old_row_corr_name //更新前的旧元组命别名为
| NEW [ROW] [AS] new_row_corr_name //更新后的新元组命别名为
| OLD TABLE [AS] old_table_corr_name //更新前的旧Table命别名为
| NEW TABLE [AS] new_table_corr_name //更新后的新Table命别名为
}
corr_name_def将在检测条件或后面的动作程序段中被引用处理
设计一个触发器当进行Teacher表更新元组时, 使其工资只能升不能降
create trigger teacher_chgsal before update of salary
on teacher
referencing new x, old y
for each row when (x.salary < y.salary)
begin
raise_application_error(-20003, ‘invalid salary on update’);
//此条语句为Oracle的错误处理函数
end;
假设student(S#, Sname, SumCourse), SumCourse为该同学已学习课程的
门数,初始值为0,以后每选修一门都要对其增1 。设计一个触发器自动完成上
述功能。
create trigger sumc after insert on sc
referencing new row newi
for each row
begin
update student set SumCourse = SumCourse + 1
where S# = :newi.S# ;
end;
数据库安全性的概念及分类
DBMS的安全机制
自主安全性机制:存取控制(AccessControl),通过权限在用户之间的传递,使用户自主管理数据库安全性
强制安全性机制:通过对数据和用户强制分类,使得不同类别用户能够访问不同类别的数据
利用SQL语言实现数据库自主安全性
自主安全性机制
通常情况下,自主安全性是通过授权机制来实现的。用户在使用数据库前必须由DBA处获得一个账户,并由DBA授予该账户一
定的权限,该账户的用户依据其所拥有的权限对数据库进行操作; 同时,该帐户用户也可将其所拥有的权利转授给其他的用户(账户),由此实现权限在用户之间的传播和控制。
授权命令
GRANT {all PRIVILEGES | privilege {,privilege…}}
ON [TABLE] tablename | viewname
TO {public | user-id {, user-id…}}
[WITH GRANT OPTION];
user-id ,某一个用户账户,由DBA创建的合法账户
public, 允许所有有效用户使用授予的权利
privilege是下面的权利
SELECT | INSERT | UPDATE | DELETE | ALL PRIVILEDGES
WITH GRANT OPTION选项是允许被授权者传播这些权利
假定高级领导为Emp0001, 部门领导为Emp0021, 员工管理员为Emp2001, 收发员为Emp5001(均为UserId, 也即员工的P#)
Grant All Priviledges ON Employee TO Emp2001;
收回授权命令
REVOKE {all privilEges | priv {, priv…} } ON tablename | viewname
FROM {public | user {, user…} };
示例
revoke select on employee from UserB;
强制安全性机制
强制安全性通过对数据对象进行安全性分级
绝密(Top Secret), 机密(Secret),可信(Confidential)和无分类(Unclassified) 同时对用户也进行上述的安全性分级
从而强制实现不同级别用户访问不同级别数据的一种机制
嵌入式SQL语言

数据字典(Data dictionary),又称为系统目录(System Catalogs)
是系统维护的一些表或视图的集合,这些表或视图存储了数据库中各类对象的定义信息,这些对象包括用Create语句定义的表、列、索引、视图、权限、约束等,这些信息又称数据库的元数据–关于数据的数据。
不同DBMS术语不一样:数据字典(DataDictionary(Oracle))、目录表(DB2UDB)、系统目录(INFORMIX)、系统视图(X/Open)
不同DBMS中系统目录存储方式可能是不同的,但会有一些信息对DBA公开。这些公开的信息,DBA可以使用一些特殊的SQL命令来检索。
数据字典的内容构成
数据字典通常存储的是数据库和表的元数据,即模式本身的信息:
与关系相关的信息
关系名字
每一个关系的属性名及其类型
视图的名字及其定义
完整性约束
用户与账户信息,包括密码
统计与描述性数据:如每个关系中元组的数目
物理文件组织信息:
关系是如何存储的(顺序/无序/散列等)
关系的物理位置
索引相关的信息
ODBC是一种标准—不同语言的应用程序与不同数据库服务器之间通讯的标准。
一组API(应用程序接口),支持应用程序与数据库服务器的交互。应用程序通过调用ODBC API, 实现与数据服务器的连接,向数据库服务器发送SQL命令,一条一条的提取数据库检索结果中的元组传递给应用程序的变量,具体的DBMS提供一套驱动程序,即Driver库函数,供ODBC调用,以便实现数据库与应用程序的连接。ODBC可以配合很多高级语言来使用,如C,C++, C#, Visual Basic, PowerBuilder等等;