前言
Redis是一个支持多语言
NoSql数据库
,提供多种API,本文会从Redis的命令角度进行讲解。这些命令都是单线程操作的,不用担心线程安全问题,基于内存操作加IO多路复用,存取数据快。以下讲解基于redis-6.2.6实现。不同版本的命令可能稍有差异,大家可以去Redis官网查看。
官网地址:
Command reference – Redis
一、String
简介
String底层由int、emstr、raw实现,是Reids最基本的数据类型,一个key对应一个value,可以包含任何数据,每个String最大支持512M的存储。
常用命令
• 设置值:SET key
• 获取值:GET key
• 批量设置值:MSET key1 value key2 value
• 批量获取值:MGET key1 key2
• 如果value是数字
• 递增数字:INCR key
• 增加指定的整数:INCRBY key increment
• 递减数值:DECR key
• 减少指定的整数:DECRBY key decrement
命令操作如下图所示
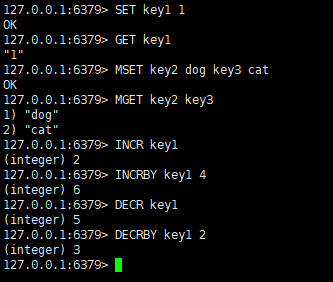
应用场景:
• 存储对象(不推荐使用)如果要存储对象,一般来说会把对象序列化成一个json的字符串,取出的话也需要反序列化,这样话增加了系统的开销。如果要修改对象中某个值,这个对象需要全部取出来,只修改了一个值,然后再放回去,同样会增加系统的开销。
• 存储Mysql中的某个字段
• 文章的点赞数,小视频的点赞数,有点击喜欢的操作就 +1,
取消喜欢的操作就 -1。
二、hash
简介
hash底层由ziplist、hashtable实现, 是一个键值对集合,是一String类型的field和value的映射表,类似Java中的Map<String,Object>
常用命令
• 一次设置一个字段值:HSET key field value
• 一次获取一个字段值:HGET key field
• 一次设置多个字段值:HMSET key field1 value [field value …]
• 一次获取多个字段值:HMGET key field [field ….]
• 获取所有字段值:HGETALL key1 key2
• 获取某个key内的全部数量:HLEN key
命令操作如下图所示
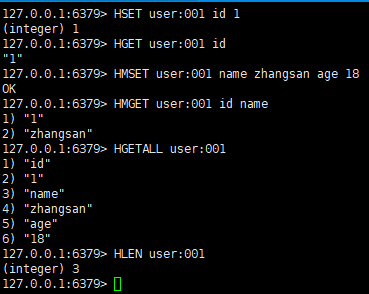
应用场景
适用于存储对象,比如说存储user:001这个对象,直接存储成hash即可,要想修改user:001 的age 属性,直接把通过set user:001 age 108,
省去了String中因为修改对象的一个属性,把整个对象都操作一遍的麻烦。
三、list
简介
list底层由ziplist、linkedlist实现,可以理解为是一个简单的字符串列表(双向链表),按照插入顺序排序,可以添加元素到列表的头部(左边)或者尾部(右 边),其底层实现是一个双向链表,连端添加元素的时间复杂度是O(1),效率高,通过索引下标操作中间节点的数据效率可能低,可参考Java中的LinkedList。容量是2的32次方减1个元素,大概40多亿(4294967295)
常用命令
• 向列表左边添加元素:LPUSH key value [value …]
• 向列表右边添加元素:RPUSH key value [value ….]
• 从左边取值:LPOP key
• 从右边取值:RPOP key
• 查看列表:LRANGE key start stop
• 查看所有的值:LRANGE key 0 -1
命令操作如下图所示
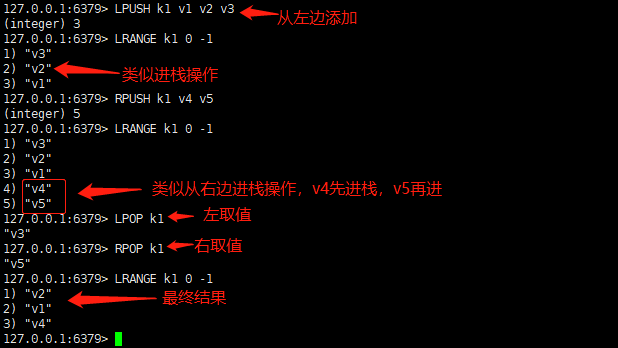
应用场景
• 顺序任务池:可以利用Lists的PUSH操作,将任务存在List中,然后工作线程再用POP操作将任务取出进行执行,类似消息队列
• 按时间顺序排序,文章列表
• 也可以自由组合:
队列:LPUSH + RPUSH
栈:LPUSH + LPOP
四、set
简介
set底层由intset、hashtable 实现,对外提供的功能和list相似的列表的功能,但set是不允许数据重复,是String类型的无序集合,底层是一个value为null的hash表,所以添加、删除、查找的复杂度是O(1)。
常用命令
• 添加元素:SADD key member [member …]
• 删除元素:SREM key member [member …]
• 遍历集合中的所有元素:SMEMBERS key
• 判断元素是否在集合中:SISMEMBER key member
• 获取集合中的元素总数:SCARD key
• 从集合中随机弹出N元素,元素不删除:SRANDMEMBER key [N]
• 从集合中随机弹出N元素,出一个删一个:SPOP key [N]
• 集合的交集运算 A∩B(属于A同时也属于B的共同拥有的元素构成的集合)
SINTER key [key …]
• 集合的差集运算 A-B(属于A但不属于B的元素构成的集合)
SDIFF key [key …]
• 集合的并集运算 A ∪ B(属于A或者属于B的元素合并后的集合)
SUNION key [key …]
命令操作如下图所示
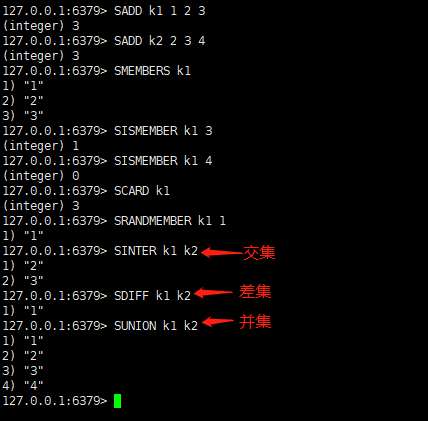
应用场景
• 随机抽奖
• 社交需求(共同关注,可能认识的人等)
五、zset
简介
zset底层由ziplist、skiplist实现,是一个没有重复元素的字符串集合,其中每个成员都关联了一个评分(score),这个评分(score)按照最低分到最高的方式对该集合中的成员进行排序,集合是唯一的,评分可以重复。
常用命令
•
添加元素:ZADD key score member [score member …]
• 获取元素的排名(从小到大)
ZRANGE key start stop(最后两位标识元素角标的位置)
• 获取元素的排名(从大到小):ZREVRANGE key member
• 按照元素分数从小到大的顺序,返回索引从start到stop之间的所有元素
ZRANGE key start stop [WITHSCORES]
• 获取元素的分数:ZSCORE key member
• 增加某个元素的分数:ZINCRBY key increment member
• 获取集合中元素的数量:ZCARD key
• 删除元素:ZREM key member [member …]
• 按照排名范围删除元素:ZREMRANGEBYRANK key start stop
命令操作如下图所示:
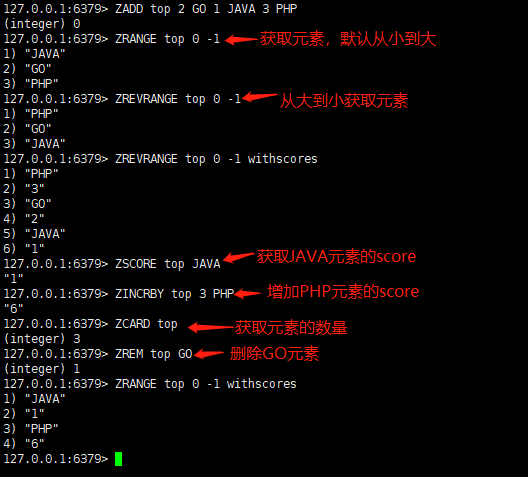
应用场景
• 实现文章阅读量排行榜
• 打赏排行榜
六、bitmap
简介
bitmap是由0和1状态表现的二进制位的bit数组,本身不是一种数据类型, 实际上它就是字符串(key-value) , 但是它可以对字符串的位进行操作。
Bitmaps单独提供了一套命令, 所以在Redis中使用Bitmaps和使用字符串的方法不太相同。可以把Bitmaps想象成一个以位为单位的数组, 数组的每个单元只能存储0和1, 数组的下标在Bitmaps中叫做偏移量
常用命令
• 设置值:SETBIT key offset value(offset的偏移量从零开始,value的值
只能是0或者1)
• 获取值:GETBIT getbit key offset
命令操作如下图所示
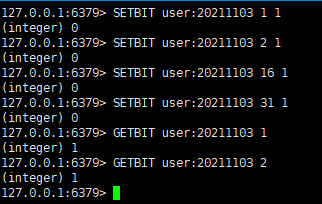
• 统计
字符串
被设置为1的bit数: bitcount key
一般情况下,给定的整个字符串都会被进行计数,通过指定额外的 start 或 end 参数,可以让计数只在特定的位上进行。start 和 end 参数的设置,都可以使用负数值:比如 -1 表示最后一个位,而 -2 表示倒数第二个位,start、end 是指bit组的字节的下标数。
•
BITCOUNT key [start end] 统计字符串从start字节到end字节比特值为1的数量
举例: K1 【01000001 01000000 00000000 00100001】
对应 0 1 2 3
• 代码如下图
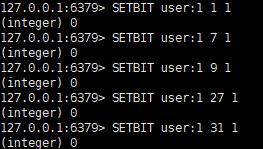
• 统计下标1、2字节组中bit=1的个数:bitcount K1 1 2
即统计 01000000 00000000 中值为1的个数(bitcount K1 1 2–>1)
• 结果如下图

• bitcount K1 0 -2 :统计下标0到下标倒数第2字节组中bit=1的个数,
即01000001 01000000 00000000中值为1的个数(bitcount K1 1 -2–>3)

• BITOP是一个复合操作, 它可以做多个Bitmaps的
and(交集)or(并集)、not(非)、xor(异或)
BITOP and(or/not/xor)
• 2021-11-03 日访问某网站的user = 1,2,5,9
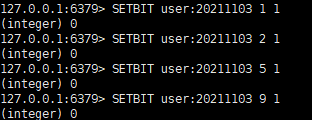
• 2021-11-03 日访问网站的userid=0,1,4,9
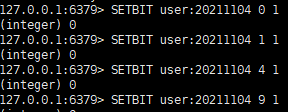
• 使用BITOP AND 操作后的结果,得出交集的数量如下图

剩下的 or(并集) 、 not(非) 、 xor(异或)不做展示
应用场景
• 大数据量场景下可以用来存储网站的访问次数
• 统计连续打卡的天数等
七:hyperloglog
简介
HyperLogLog 是用来做基数统计的算法,其优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。只是进行不重复的基数统计,只统计数量,不记录数据的具体内容。
常用命令
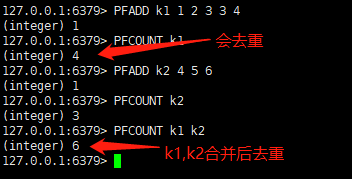
• 添加元素:PFADD key element [element…]
• 查询元素:PFCOUNT key [key…]
• 合并元素:PFMERGE sourcekey[sourcekey…]
命令操作如下图所示:
应用场景
• 针对大数据量的基数统计,例如:做一些门户网站UV(独立访客)的统计。
八、GEO
简介
Redis 3.2 中增加了对GEO类型,即 Geographic,地理信息的缩写,就是元素的2维坐标,在地图上就是经纬度。
常用命令
• 添加元素:
GEOADD key longitude latitude member [longitude latitude member…]

• 获取指定元素:GEOPOS key menber [member…]
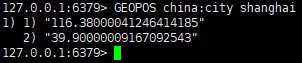
• 获取两个位置之间的直线距离:
GEODIST key member1 menber2 [m|km|ft|mi](默认距离是m)

• 以给定的经纬度坐标,找出某一半径内的元素:
GEORADIUS key longitude latitude radius [m|km|ft|mi]

应用场景
用于直线距离的计算
• 外卖软件中附近的美食店铺
• 打车软件附近的车辆等等
以上简单介绍了reids八个数据类型的使用,学习知识最好要知其然,知其所以然,这样写出撸出来的代码才更加的健壮。
下期将会写Redis数据类型的底层实现。
我是小小的程序员,咱们不见不散~~~
码字不易,最后请大家动动小手,点播关注
![]()
