参考:台大机器学习技法 http://blog.csdn.net/lho2010/article/details/42927287
stacking&blending http://heamy.readthedocs.io/en/latest/usage.html
1.stacking&blending
blending:
比如数据分成train和test,对于model_i(比如xgboost,GBDT等等)
对train做CV fold=5,使用其中4份做训练数据,另外一份作为val数据,得出模型model_i_j,然后对val预测生成向量v_i_j,对test预测生成向量t_i_j
同样的方式做5次,把所有train都预测完一边遍,将5份向量concat对应生成t_i与v_i
每个模型都能生成这样两组向量,一个是训练集的,一个是测试集的(测试集的在同一个模型预测多次后取平均)
有多少个模型就生成多少维的向量
然后在顶层的模型比如LR或者线性模型对v向量进行训练,生成模型对t向量进行预测
|
id |
model_1 |
model_2 |
model_3 |
model_4 |
label |
|
1 |
0.1 |
0.2 |
0.14 |
0.15 |
0 |
|
2 |
0.2 |
0.22 |
0.18 |
0.3 |
1 |
|
3 |
0.8 |
0.7 |
0.88 |
0.6 |
1 |
|
4 |
0.3 |
0.3 |
0.2 |
0.22 |
0 |
|
5 |
0.5 |
0.3 |
0.6 |
0.5 |
1 |
stacking:
将数据划分成train,test,然后将train划分成不相交的两部分train_1,train_2
使用不同的模型对train_1训练,对train_2和test预测,生成两个1维向量,有多少模型就生成多少维向量
第二层使用前面模型对train_2生成的向量和label作为新的训练集,使用LR或者其他模型训练一个新的模型来预测test生成的向量

两者区别是:
数据划分方式不同,blending在划分完train,test之后,将train进行cv划分来训练。也就是说第二层用到了第一层的全部数据
stacking是
划分完train,test之后对train划分为2份不相交的数据,一份训练,一份用来生成新的特征,在第二层用来训练,第二层只用到了部分数据
下面是一个blending代码
from __future__ import division
import numpy as np
import load_data
from sklearn.cross_validation import StratifiedKFold
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier, GradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
from utility import *
from evaluator import *
def logloss(attempt, actual, epsilon=1.0e-15):
"""Logloss, i.e. the score of the bioresponse competition.
"""
attempt = np.clip(attempt, epsilon, 1.0-epsilon)
return - np.mean(actual * np.log(attempt) + (1.0 - actual) * np.log(1.0 - attempt))
if __name__ == '__main__':
np.random.seed(0) # seed to shuffle the train set
# n_folds = 10
n_folds = 5
verbose = True
shuffle = False
# X, y, X_submission = load_data.load()
train_x_id, train_x, train_y = preprocess_train_input()
val_x_id, val_x, val_y = preprocess_val_input()
X = train_x
y = train_y
X_submission = val_x
X_submission_y = val_y
if shuffle:
idx = np.random.permutation(y.size)
X = X[idx]
y = y[idx]
skf = list(StratifiedKFold(y, n_folds))
clfs = [RandomForestClassifier(n_estimators=100, n_jobs=-1, criterion='gini'),
RandomForestClassifier(n_estimators=100, n_jobs=-1, criterion='entropy'),
ExtraTreesClassifier(n_estimators=100, n_jobs=-1, criterion='gini'),
ExtraTreesClassifier(n_estimators=100, n_jobs=-1, criterion='entropy'),
GradientBoostingClassifier(learning_rate=0.05, subsample=0.5, max_depth=6, n_estimators=50)]
print "Creating train and test sets for blending."
dataset_blend_train = np.zeros((X.shape[0], len(clfs)))
dataset_blend_test = np.zeros((X_submission.shape[0], len(clfs)))
for j, clf in enumerate(clfs):
print j, clf
dataset_blend_test_j = np.zeros((X_submission.shape[0], len(skf)))
for i, (train, test) in enumerate(skf):
print "Fold", i
X_train = X[train]
y_train = y[train]
X_test = X[test]
y_test = y[test]
clf.fit(X_train, y_train)
y_submission = clf.predict_proba(X_test)[:,1]
dataset_blend_train[test, j] = y_submission
dataset_blend_test_j[:, i] = clf.predict_proba(X_submission)[:,1]
dataset_blend_test[:,j] = dataset_blend_test_j.mean(1)
print("val auc Score: %0.5f" % (evaluate2(dataset_blend_test[:,j], X_submission_y)))
print
print "Blending."
# clf = LogisticRegression()
clf = GradientBoostingClassifier(learning_rate=0.02, subsample=0.5, max_depth=6, n_estimators=100)
clf.fit(dataset_blend_train, y)
y_submission = clf.predict_proba(dataset_blend_test)[:,1]
print "Linear stretch of predictions to [0,1]"
y_submission = (y_submission - y_submission.min()) / (y_submission.max() - y_submission.min())
print "blend result"
print("val auc Score: %0.5f" % (evaluate2(y_submission, X_submission_y)))
print "Saving Results."
np.savetxt(fname='blend_result.csv', X=y_submission, fmt='%0.9f')
2.rank_avg
这种融合方法适合排序评估指标,比如auc之类的
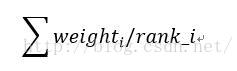
其中weight_i为该模型权重,权重为1表示平均融合
rank_i表示样本的升序排名 ,也就是越靠前的样本融合后也越靠前
能较快的利用排名融合多个模型之间的差异,而不用去加权样本的概率值融合
3.weighted
加权融合,给模型一个权重weight,然后加权得到最终结果
weight为0.5时为均值融合,result_i为模型i的输出
一般会考虑多个模型之间的相似度和得分情况
得分高的模型权重大,尽量融合相似度相对低的模型
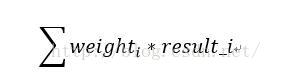
4.bagging
从特征,参数,样本的多样性差异性来做多模型融合,参考随机森林

5.boosting
参考adaboost,gbdt,xgboost