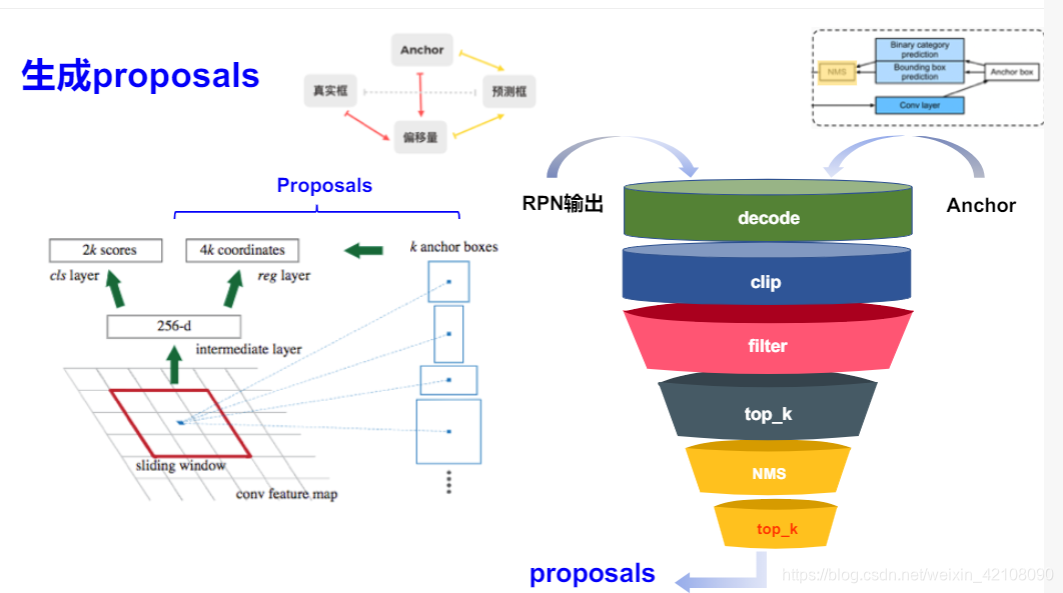
在提出RPN之前候选区域如何生成
2013年,R-CNN提出了两阶段目标检测,分为region proposal 阶段和区域分类与精细化阶段。

在上图中,R-CNN 首先使用一种称为selective search的技术从输入图像中提取出感兴趣的潜在区域。selective search并不真正尝试理解前景目标,相反,它依靠启发式方法对相似的像素进行分组: 相似的像素通常属于同一个目标。因此,selective search的结果很有可能包含一些有意义的内容。
接下来,R-CNN 将这些 region proposals 变换成带有一些填充的固定大小的图像,并将这些图像提供给网络的第二阶段,以便进行更细粒度的识别。
与那些使用selective search的旧方法不同,R-CNN 在第二阶段将 HOG 替换为 CNN,从所有 region proposals 中提取特征。这种方法需要注意的是,许多 region proposals 实际上并不是一个完整的目标,**因此 R-CNN 不仅需要学习如何对包含的类别进行分类,还需要学习如何拒绝负类。**为了解决这个问题,R-CNN 将所有与一个ground truth框重叠度≥0.5 IoU 的 region proposal 视为正,其余视为负。
selective search 的 region proposal 高度依赖于相似性假设,因此只能提供大致的位置估计。为了进一步提高定位精度,R-CNN 借鉴了“Deep Neural Networks for Object Detection”(又名 DetectorNet)的思想,引入了额外的边界框回归来预测框的中心坐标、宽度和高度。这种回归器被广泛应用于未来的目标检测器中。
然而,像 R-CNN 这样的两阶段检测器存在两个大问题:
- selective search并不是卷积,因此它不是端到端可训练的。
-
region proposal 阶段与单阶段检测器相比通常非常慢,而且在每个 region proposal上分别运行会使其更慢。
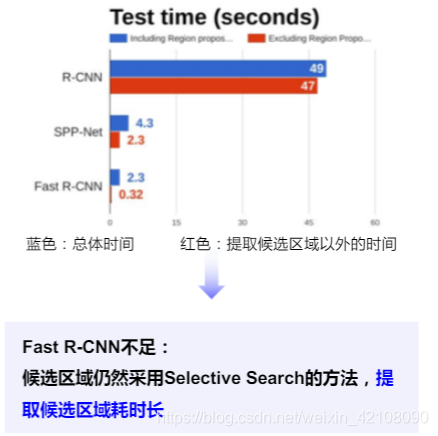
2015: Fast R-CNN
R-CNN 的一个快速后续是减少对多个 region proposals 的重复卷积。由于这些 region proposals 都来自一个图像,自然而然地想到,可以通过对整个图像运行一次 CNN,并在许多 region proposals 之间共享计算,来改进 R-CNN。然而,不同的 region proposals 有不同的大小,如果我们使用相同的 CNN 特征提取器,会导致不同的输出特征图大小。这些具有不同大小的特征图将阻止我们使用全连接层进行进一步的分类和回归,因为全连接层的输入只能是固定大小。
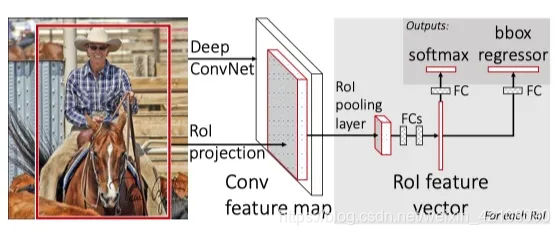
在 SPPNet 中,在卷积层和 FC 层之间引入了特征金字塔池化,以创建bag-of-words式的特征向量。这个向量有固定的大小和不同尺度的特征特征,所以我们的卷积层现在可以接受任意尺寸的图像作为输入,而不用担心 FC 层的不兼容性。
受此启发,Fast R-CNN 提出了一个类似的层称为
ROI Pooling
层。这个池化层将不同大小的特征图 downsample 为一个固定大小的向量。这样我们就可以使用相同的 FC 层进行分类和框回归,不管 ROI 是大还是小。
ROI Pooling
Fast RCNN is essentially SPPNet with trainable feature extraction network and RoIPooling in replacement of the SPP layer. RoIPooling (region of interest pooling) is simply a special case of
SPP where here only one pyramid level is used. RoIPooling generates a fixed 7×7 feature volume for each RoI (region proposal) by dividing the RoI feature volume into a 7×7 grid of sub-windows and then max-pooling the values from each sub-window.
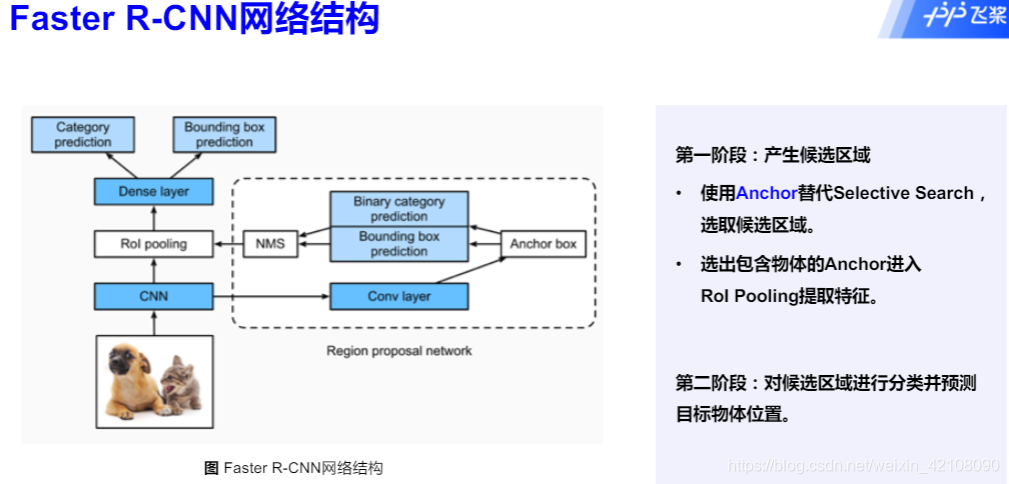
Faster R-CNN: 通过Region Proposal Networks实现实时目标检测
有了 Fast R-CNN,网络中唯一的非卷积部分就是 selective search 的 region proposal了。
2015年,研究人员开始意识到深层神经网络是如此神奇,只要有足够的数据,它就可以学习任何东西。那么,是否有可能训练一个 region proposal 的神经网络,而不是依赖于 selective search 等启发式和手工的方法?
Faster R-CNN 遵循这个方向和思路,并成功地创建了Region Proposal Network(RPN)。简单地说,RPN 是一个 CNN,以图像作为输入,并输出一组矩形目标建议,每个都有一个 objectiveness 得分。论文最初使用的是 VGG,但其他主干网络如 ResNet 后来变得更加普及。为了生成 region proposals,在 CNN 特征图输出上应用一个3×3滑动窗口每个位置生成2个得分(前景和背景)和4个坐标值。
RPN is a sliding-window class-agnostic object detector. In the original RPN design, a small subnetwork is evaluated on dense 3×3 sliding windows, on top of a singlescale convolutional feature map, performing object/nonobject binary classification and bounding box regression.
This is realized by a 3×3 convolutional layer followed by two sibling 1×1 convolutions for classification and regression, which we refer to as a network head.
The object/nonobject criterion and bounding box regression target are defined with respect to a set of reference boxes called anchors. The anchors are of multiple pre-defined scales and aspect ratios in order to cover objects of different shapes.
虽然滑动窗口有一个固定的大小,我们的目标可能有不同的尺度。因此,Faster R-CNN 引入了一种称为 anchor box 的技术。Anchor boxes 是预先定义的具有不同宽高比和尺寸的框,但共享相同的中心位置。在 Faster R-CNN 中,每个滑动窗口位置都有 k = 9个anchors,每个anchor 覆盖3个高宽比和3个尺度。这些不同尺度的重复 anchor boxes 在共享同一特征图输出的同时,为网络带来了良好的平移不变性和比例不变性。

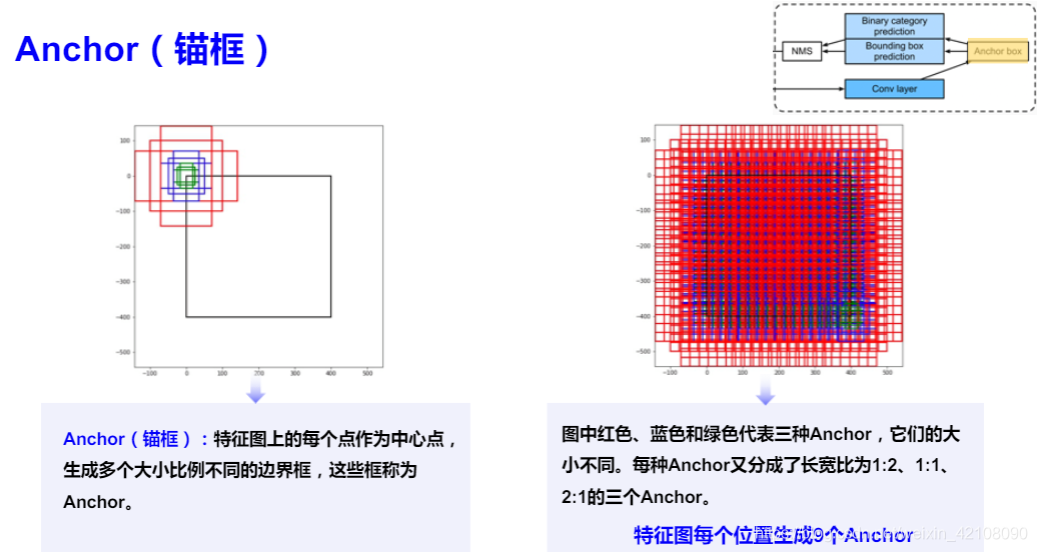
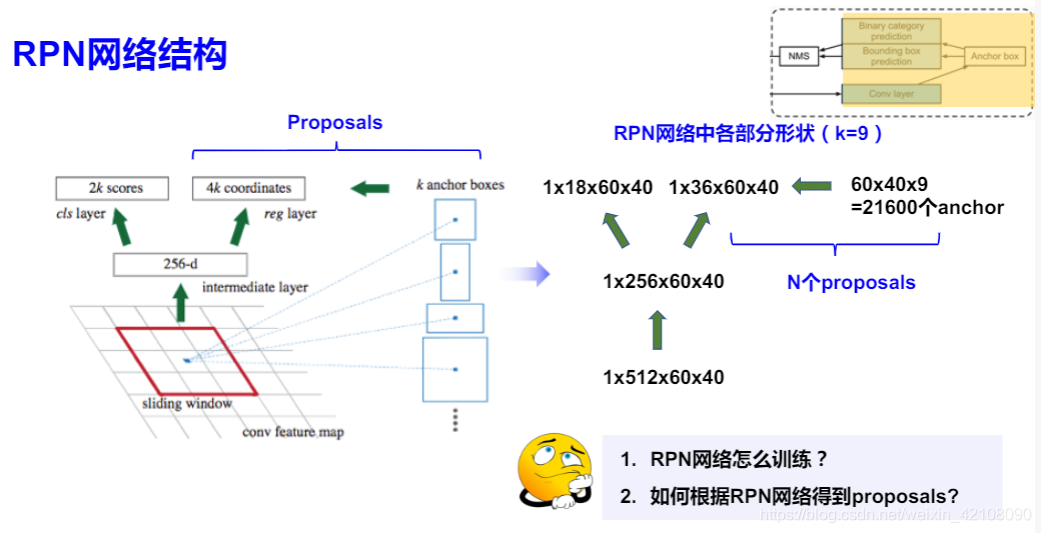
一共有21600个anchor ,后续通过采样选择256个样本。
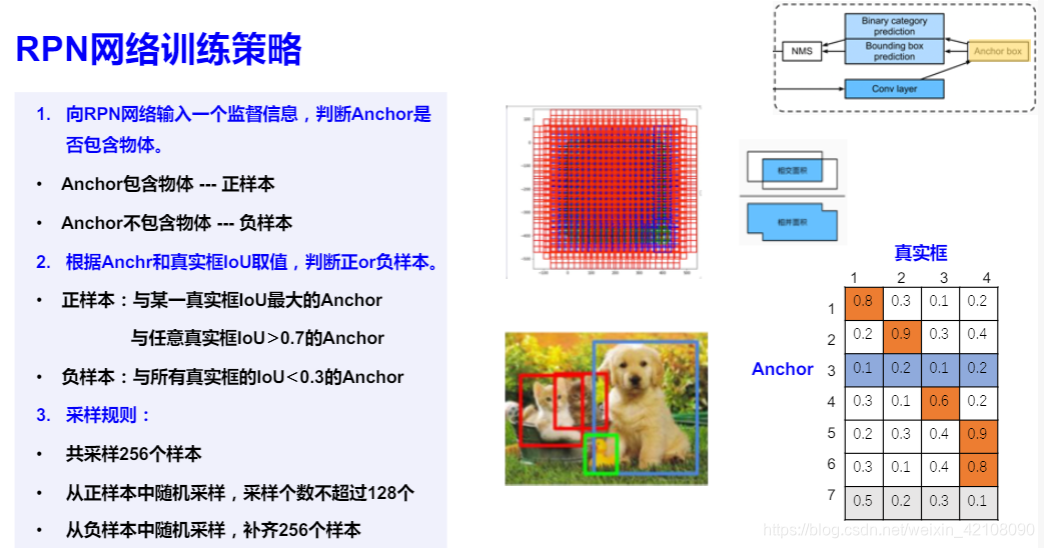
右图举例说明了anchor的选取策略。
进一步采样,一共选取了256个anchor。

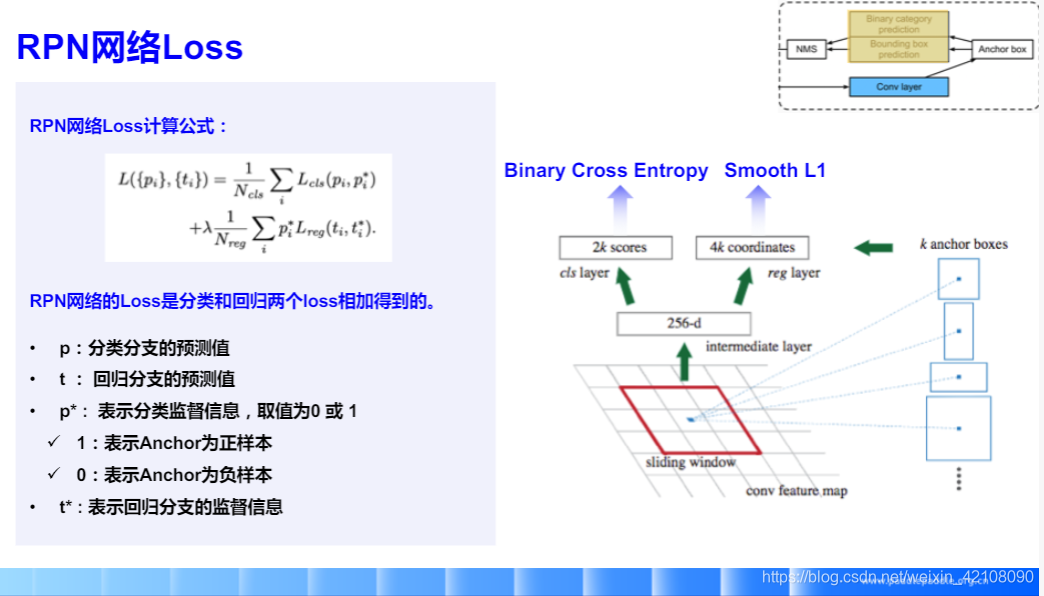
Smooth L1 是L1 和L2的综合