综述
本文是对程序动态工具的调研,通对各种动态分析工具的***原理***、
功能
、***优缺点***等方面的调研分析来使读者在使用工具时更有针对性。
作为调研,本文并不过多的涉及工具的细节,主要关注点在于工的原理、功能、优缺点(使用领域)。具体工具可做具体了解。
Gprof
简介
Gprof 是GNU gnu binutils工具之一,默认情况下linux系统当中都带有这个工具。Gprof给出了函数调用的次数、调用耗时以及函数的调用关系,通过分析产生的数据结果可以确定程序的执行流程,进而有针对性的对程序进行优化。
功能
可以获得的几种格式的数据:
1
-
flat profile
:给出了每个函数的耗时以及函数被调用的次数。 -
call graph
:给出了函数调用关系,以及对函数耗时的一个估计。 -
注释的源代码
--是程序源代码的一个复本,标记有程序中每行代码的执行次数。
原理
实现原理
2
gcc -pg 在应用程序的每个函数中添加了名为 mcount/mcount/_mcount的函数。 应用程序每个函数执行时都会执mcount,而mcount则会在内存中保存一张函数调用图,通过函数调用堆栈的形式,查找子函数、父函数的地址,也保存了与函数相关的调用时间、次数等信息。
程序运行结束后,会在程序退出的路径下生成一个 gmon.out文件。这个文件就是记录并保存下来的监控数据。可以通过命令行方式的gprof或图形化的Kprof来解读这些数据并对程序的性能进行分析。
另外,如果想查看库函数的profiling,需要在编译是再加入“-lc_p”编译参数代替“-lc”编译参数,这样程序会链接libc_p.a 库,才可以产生库函数的profiling信息。如果想执行一行一行的profiling,还需要加入“-g”编译参数。
结果产生与分析
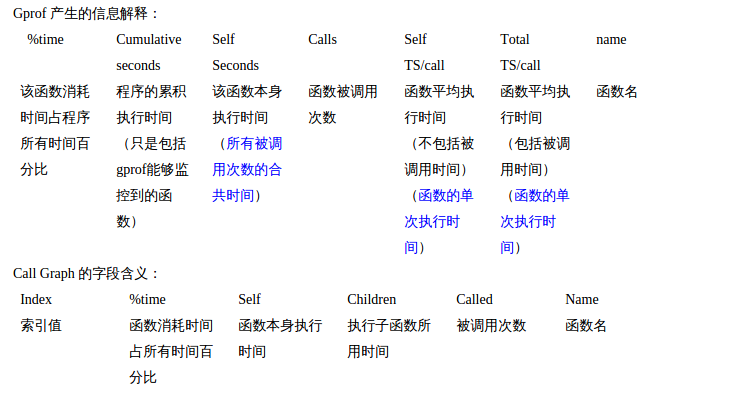
图1 Gprof结果信息
3
用法
- 在编译和链接时 加上-pg选项。一般我们可以加在 makefile 中。
- 执行编译的二进制程序。执行参数和方式同以前。
- 在程序运行目录下 生成 gmon.out 文件。如果原来有gmon.out 文件,将会被重写。
- 结束进程。这时 gmon.out 会再次被刷新。
- 用 gprof 工具分析 gmon.out 文件。
优缺点
4
###优点
- Gprof为GNU binutils工具之一,默认情况下linux系统当中都带有这个工具,使用方便。
- 生成结果包括函数调用时间以及函数调用关系,可以方便用户利用该数据做进一步分析 。
缺点
- 使用插桩技术,消耗系统资源。函数的每次执行都会调用插桩函数mcount,并且mcount函数会在内存中维护一个函数调用图,使得对CPU和内存资源都带来消耗。
- 程序必须是正常退出才能生成gmon.out文件,也就是说程序必须执行到main函数的return或者exit()。
- 如果程序运行的时间非常短,则Gprof可能无效,因为受到启动、初始化、退出等函数运行时间的影响。
- 不支持多进程,如果分析多进程程序则可能一个进程的gmont.out文件会覆盖另一个进程的gmont.out文件。 解决方法是在执行程序之前执行:export GMON_OUT_PREFIX=x.out 则之后生成的文件名就如x.out.pid,多进程的gmon.out就不会相互覆盖。
- 不支持多线程。缘故是gprof使用ITIMER_PROF定时器, 当超时时由内核向应用程序发送信号。但多线程程序只有主线程接收ITIMER_PROF。 这里有一个简单的实现方法: 对pthread_create进行包装,并以动态库的形式在程序运行前加载。
- 只能分析应用程序在运行过程中所消耗掉的用户时间,无法得到程序内核空间的运行时间。
Ftrace
简介
5
6
ftrace 的作用是帮助开发人员了解 Linux 内核的运行时行为,以便进行故障调试或性能分析。最早 ftrace 是一个 function tracer,仅能够记录内核的函数调用流程。如今 ftrace 已经成为一个framework,采用 plugin (以下一般称为tracer)的方式支持开发人员添加更多种类的 trace 功能。
ftrace一个鲜明的特点就是,对所有的操作都是对文件的操作,比如,使用某一个tracer便将相应的函数名写入current_tracer文件中,
# echo function tracer > current_tracer
.
功能
ftrace作为一个平台,采用插件的方式支持开发人员添加自定义的trace功能,简而言之,开发人员可以根据自己的需求来使用已有功能或者根据ftrace提供的API来开发满足自己需求的插件。ftrace自带插件如下表
6
| 插件 | 功能描述 |
|---|---|
|
function tracer |
仅能够记录内核的函数调用流程 |
|
Schedule switch tracer |
跟踪进程调度情况 |
|
Wakeup tracer |
跟踪进程的调度延迟,即高优先级进程从进入 ready 状态到获得 CPU 的延迟时间。该 tracer 只针对实时进程。 |
|
Irqsoff tracer |
当中断被禁止时,系统无法相应外部事件,比如键盘和鼠标,时钟也无法产生 tick 中断。这意味着系统响应延迟,irqsoff 这个 tracer 能够跟踪并记录内核中哪些函数禁止了中断,对于其中中断禁止时间最长的,irqsoff 将在 log 文件的第一行标示出来,从而使开发人员可以迅速定位造成响应延迟的罪魁祸首。 |
|
Preemptoff tracer |
和前一个 tracer 类似,preemptoff tracer 跟踪并记录禁止内核抢占的函数,并清晰地显示出禁止抢占时间最长的内核函数。 |
|
Preemptirqsoff tracer |
同上,跟踪和记录禁止中断或者禁止抢占的内核函数,以及禁止时间最长的函数。 |
|
Branch tracer |
跟踪内核程序中的 likely/unlikely 分支预测命中率情况。 Branch tracer 能够记录这些分支语句有多少次预测成功。从而为优化程序提供线索。 |
|
Hardware branch tracer |
利用处理器的分支跟踪能力,实现硬件级别的指令跳转记录。在 x86 上,主要利用了 BTS 这个特性。 |
|
Initcall tracer |
记录系统在 boot 阶段所调用的 init call 。 |
|
Mmiotrace tracer |
记录 memory map IO 的相关信息。 |
|
Power tracer |
记录系统电源管理相关的信息。 |
|
Sysprof tracer |
缺省情况下,sysprof tracer 每隔 1 msec 对内核进行一次采样,记录函数调用和堆栈信息。 |
|
Kernel memory tracer |
内存 tracer 主要用来跟踪 slab allocator 的分配情况。包括 kfree,kmem_cache_alloc 等 API 的调用情况,用户程序可以根据 tracer 收集到的信息分析内部碎片情况,找出内存分配最频繁的代码片断,等等。 |
|
Workqueue statistical tracer |
这是一个 statistic tracer,统计系统中所有的 workqueue 的工作情况,比如有多少个 work 被插入 workqueue,多少个已经被执行等。开发人员可以以此来决定具体的 workqueue 实现,比如是使用 single threaded workqueue 还是 per cpu workqueue。 |
|
Event tracer |
跟踪系统事件,比如 timer,系统调用,中断等。 |
注意:
- 这里只是列出了比较常用的tracer,并没有列出所有的tracer,ftrace 是目前非常活跃的开发领域,新的 tracer 将不断被加入内核。
- available_tracers文件记录了当前编译进内核的跟踪器的列表,换句话说,默认情况下,用户的机器上并不支持上面所有tracer。
原理
实现原理
Ftrace 有两大组成部分,一是 framework,另外就是一系列的 tracer 。每个 tracer 完成不同的功能,它们统一由 framework 管理。 ftrace 的 trace 信息保存在 ring buffer 中,由 framework 负责管理。 Framework 利用 debugfs 系统在 /debugfs 下建立 tracing 目录,并提供了一系列的控制文件。其架构图如下:
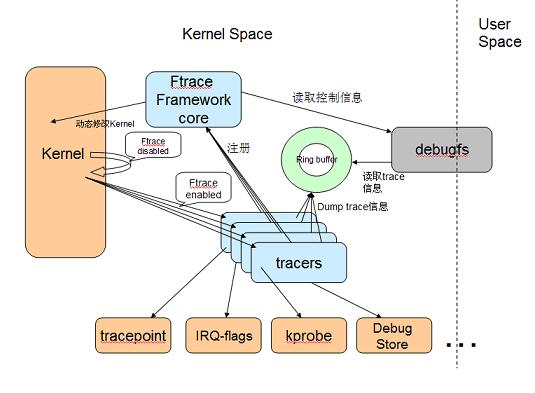
图2 ftrace实现原理
6
Ftrace本身也使用的是插桩技术, 原理类似于Gprof,但是ftrace没有在内存中保存函数调用图,并且动态地使用mcount指令,只是在用户需要时替换nop指令为mcount指令
7
。具体操作上,ftrace 采用 GCC 的 profile 特性在所有内核函数的开始部分加入一段 stub 代码,ftrace 重载这段代码来实现 trace 功能。gcc 的 -pg 选项将在每个函数入口处加入对 mcount 的调用代码。
结果产生与分析
由于ftrace针对不同的应用场景有不同的tracer来完成相应的工作,故而,各个tracer返回来的数据格式也不尽相同。这里仅以ftrace中最常用的function tracer为例
6
:
# tracer: function
#
# TASK-PID CPU# TIMESTAMP FUNCTION
# | | | | |
bash-4251 [01] 10152.583854: path_put <-path_walk
bash-4251 [01] 10152.583855: dput <-path_put
bash-4251 [01] 10152.583855: _atomic_dec_and_lock <-dput
可以看到,tracer 文件类似一张报表,前 4 行是表头。第一行显示当前 tracer 的类型。第三行是 header 。对于 function tracer,该表将显示 4 列信息。首先是进程信息,包括进程名和 PID ;第二列是 CPU,在 SMP 体系下,该列显示内核函数具体在哪一个 CPU 上执行;第三列是时间戳;第四列是函数信息,缺省情况下,这里将显示内核函数名以及它的上一层调用函数。通过对这张报表的解读,用户便可以获得完整的内核运行时流程。这对于理解内核代码也有很大的帮助。有志于精读内核代码的读者,或许可以考虑考虑 ftrace 。如上例所示,path_walk() 调用了 path_put 。此后 path_put 又调用了 dput,进而 dput 再调用 _atomic_dec_and_lock 。
用法
- 编译内核使得内核支持所需要的trace。注意,ftrace是内核自带的分析工具,如没有特需的需求可不进行此步。
-
挂载debugfs,
# mount -t debugfs nodev /sys/kernel/debug
。debugfs虚拟文件系统是内核空间和用户空间数据通信的工具,挂载后,挂载点目录下包含了ftrace相应的文件。比如,记录当前可用tracer的文件available_tracers就在其中。 - 切换到目录 /sys/kernel/debug/tracing/ 下。
-
查看 available_tracers 文件,获取当前内核支持的跟踪器列表。
5. 关闭 ftrace 跟踪,即将 0 写入文件 tracing_enabled。
# echo 0 > tracing_enabled
在新的内核版本中,tracing_enabled 被删除了,也就是说这步是不需要的,同理第9步关于tracing_enabled部分也是不需要的。关于原因
9
,有人问过 Ftrace 的维护人Steven Rostedt,他说使用 tracing_on 可以快速的打开 Ftrace 的追踪,这让 tracing_enabled 显得很轻量级或者说显得比较冗余,下面可以会说到,我们写内核程序时可以使用Ftrace 提供的内核函数 tracing_on() or tracing_off() 直接打开追踪,这其实就是使用的 tracing_on ,所以在新内核中 tracing_enabled 这个看起来比较冗余的选项已经被删除
-
激活 ftrace_enabled ,否则 function 跟踪器的行为类似于 nop;另外,激活该选项还可以让一些跟踪器比如 irqsoff 获取更丰富的信息。建议使用 ftrace 时将其激活。要激活 ftrace_enabled ,可以通过 proc 文件系统接口来设置:
# echo 1 > /proc/sys/kernel/ftrace_enabled
。 -
将所选择的跟踪器的名字写入文件 current_tracer。
# echo funtion tracer > current_tracer
。 -
跟踪函数过滤。 将要跟踪的函数写入文件 set_ftrace_filter ,将不希望跟踪的函数写入文件 set_ftrace_notrace。通常直接操作文件 set_ftrace_filter 就可以了。
9. 激活 ftrace 跟踪,即将 1 写入文件 tracing_enabled。还要确保文件 tracing_on 的值也为 1,该文件可以控制跟踪的暂停如果是对应用程序进行分析的话,启动应用程序的执行,ftrace 会跟踪应用程序运行期间内核的运作情况。
- 通过将 0 写入文件 tracing_on 来暂停跟踪信息的记录,此时跟踪器还在跟踪内核的运行,只是不再向文件 trace 中写入跟踪信息;或者将 0 写入文件 tracing_enabled 来关闭跟踪。
- 查看文件 trace 获取跟踪信息,对内核的运行进行分析调试。
优缺点
优点
-
执行选择性插桩,而非对所有的函数进行插桩,即,动态的使用mcount函数,只是在用户需要的时候将nop替换为mcount,这样就可以有针对的进行函数分析
7
。 -
ftrace不需要将函数调用图保存在内存中,这样就减轻了内存资源的消耗
7
。 -
ftrace作为一个framework,本身自带了各种特定功能的tracer,用户可以直接使用。同时,用户也可以根据自己的需求修改已有tracer或者调用ftrace提供的API编写复合自己需求的tracer
6
。
缺点
- ftrace虽然执行的是选择性插桩技术,但是还是会影响到程序本身性能。
SystemTap
简介
SystemTap 是监控和跟踪运行中的 Linux 内核的操作的动态方法。这句话的关键词是动态,因为SystemTap 没有使用工具构建一个特殊的内核,而是允许您在运行时动态地安装该工具。它通过一个名为Kprobes 的应用编程接口(API)来实现该目的。
Kprobe机制,可以用来动态地收集调试和性能信息的工具,是一种非破坏性的工具,用户可以用它跟踪运行中内核任何函数或执行的指令等。相比之前的做法已经有了质的提高了,但Kprobe并没有提供一种易用的框架,用户需要自己去写模块,然后安装,对用户的要求还是蛮高的。
相比Kprobe,systemtap更加简单,提供给用户简单的命令行接口,以及编写内核指令的脚本语言。对于开发人员,systemtap是一款难得的工具。
功能
利用Kprobe机制动态的收集函数调用和程序性能相关的信息,以此来实现动态地监控和跟踪运行中的Linux内核。
原理
实现原理
SystemTap 用于检查运行的内核的两种方法是 Kprobes 和 返回探针。但是理解任何内核的最关键要素是内核的映射,它提供符号信息(比如函数、变量以及它们的地址)。有了内核映射之后,就可以解决任何符号的地址,以及更改探针的行为。
Kprobes 从 2.6.9 版本开始就添加到主流的 Linux 内核中,并且为探测内核提供一般性服务。它提供一些不同的服务,但最重要的两种服务是 Kprobe 和 Kretprobe。Kprobe 特定于架构,它在需要检查的指令的第一个字节中插入一个断点指令。当调用该指令时,将执行针对探针的特定处理函数。执行完成之后,接着执行原始的指令(从断点开始)。
Kretprobes 有所不同,它操作调用函数的返回结果。注意,因为一个函数可能有多个返回点,所以听起来事情有些复杂。不过,它实际使用一种称为 trampoline 的简单技术。您将向函数条目添加一小段代码,而不是检查函数中的每个返回点。这段代码使用 trampoline 地址替换堆栈上的返回地址 —— Kretprobe 地址。当该函数存在时,它没有返回到调用方,而是调用 Kretprobe(执行它的功能),然后从 Kretprobe 返回到实际的调用方。
systemtap 的核心思想是定义一个事件(event),以及给出处理该事件的句柄(Handler)。当一个特定的事件发生时,内核运行该处理句柄,就像快速调用一个子函数一样,处理完之后恢复到内核原始状态。这里有两个概念:
事件(Event):
systemtap 定义了很多种事件,例如进入或退出某个内核函数、定时器时间到、整个systemtap会话启动或退出等等。
***句柄(Handler):***就是一些脚本语句,描述了当事件发生时要完成的工作,通常是从事件的上下文提取数据,将它们存入内部变量中,或者打印出来。
Systemtap 工作原理是通过将脚本语句翻译成C语句,编译成内核模块。模块加载之后,将所有探测的事件以钩子的方式挂到内核上,当任何处理器上的某个事件发生时,相应钩子上句柄就会被执行。最后,当systemtap会话结束之后,钩子从内核上取下,移除模块。整个过程用一个命令 stap 就可以完成。
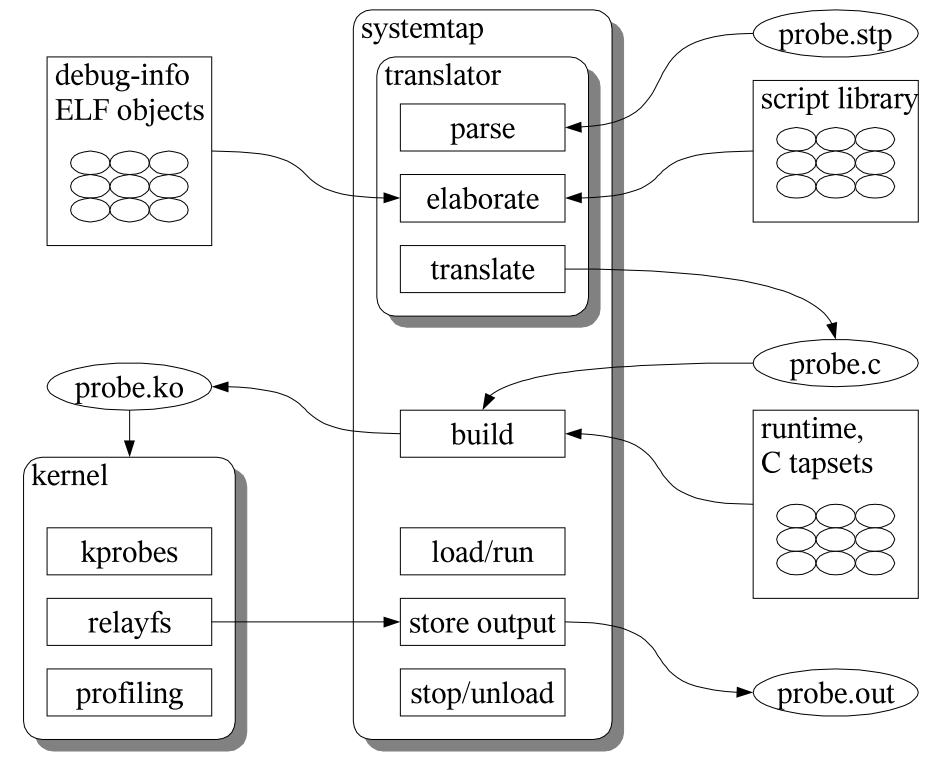
图 3 SystemTap流程图
数据产生与分析
由于在使用SystemTap时,用户通过其提供的配套脚本语言来实现自己所需功能,所以数据的产生和分析往往也是千差万别的。往往用户通过SystemTap提供的API获取自己想要的数据,根据自己的需求对其进行格式化处理以便对其进行特定的分析。
用法
SystemTap的用法比较简单灵活性也比较强,用根据其通过的脚本语言规则和相应的API就可以很方便的得到自己想要的数据,并且按照自己需要的格式进行输出。这里,以一个监控 sync 系统调用应用作为例子
10
。
注意:
同Ftrace一样SystemTap的使用需要获取到也行系统的调试信息,在一般的Linux发行版本这些调试信息是被关闭的所以需要重新编译内核并将这些需要的调试选项勾选。一种更文件简单的方法是直接现在按照debug版本的内核。具体如何操作已经超出本文范围,读者可以参见参考文献
11
给出的相关资料。
global syscalllist
probe begin {
printf("System Call Monitoring Started (10 seconds)...\n")
}
probe syscall.*
{
syscalllist[pid(), execname()]++
}
probe timer.ms(10000) {
foreach ( [pid, procname] in syscalllist ) {
printf("%s[%d] = %d\n", procname, pid, syscalllist[pid, procname] )
}
exit()
}
脚本包含一个全局变量定义和 3 个独立的探针。在首次加载脚本时调用第一个探针(begin 探针)。在这个探针中,您可以发出一条表示脚本在内核中运行的文本消息。接下来是一个 syscall 探针。注意这里使用的通配符 (*),它告诉 SystemTap 监控所有匹配的系统调用。当该探针触发时,将为特定的 PID 和进程名增加一个关联数组元素。最后一个探针是 timer 探针。这个探针在 10,000 毫秒(10 秒)之后触发。与这个探针相关联的脚本将发送收集到的数据(遍历每个关联数组成员)。当遍历了所有成员之后,将调用 exit 调用,这导致卸载模块和退出所有相关的 SystemTap 进程。
脚本的输出如下所示。从这个脚本中您可以看到运行在用户空间中的每个进程,以及在 10 秒钟内发出的系统调用的数量。
$ sudo stap profile.stp
System Call Monitoring Started (10 seconds)...
stapio[16208] = 104
gnome-terminal[6416] = 196
Xorg[5525] = 90
vmware-guestd[5307] = 764
hald-addon-stor[4969] = 30
hald-addon-stor[4988] = 15
update-notifier[6204] = 10
munin-node[5925] = 5
gnome-panel[6190] = 33
ntpd[5830] = 20
pulseaudio[6152] = 25
miniserv.pl[5859] = 10
syslogd[4513] = 5
gnome-power-man[6215] = 4
gconfd-2[6157] = 5
hald[4877] = 3
$
优缺点
优点
- SystemTap没有使用工具构建一个特殊的内核,而是采用在运行时动态地安装该工具,它通过一个名为Kprobe的应用编程接口(API)来实现动态安装。
- SystemTap提供语法结构比较简单的脚本语言,可以使的用户根据自己的需求实现相应的脚本来获取相应的数据。
缺点
-
SystemTap 项目是 Linux 社区对 SUN Dtrace 的反应,目标是达到甚至超越 Dtrace 。因此 SystemTap 设计比较复杂,Dtrace 作为 SUN 公司的一个项目开发了多年才最终稳定发布,况且得到了 Solaris 内核中每个子系统开发人员的大力支持。 SystemTap 想要赶超 Dtrace,困难不仅是一样,而且更大,因此她始终处在不断完善自身的状态下,在真正的产品环境,人们依然无法放心的使用她。不当的使用和 SystemTap 自身的不完善都有可能导致系统崩溃
6
。 - 需要支持某种编程接口让用户自定义 trace 行为,这无疑使得用户必须对其有深入的理解,提高了使用门槛,并且需要用户编写大量的脚本,这也增加了用户的工作量。
总结
通过对Gprof、Ftrace、SystemTap三个工具的调用,我们不难得出如下结果:
| 工具 | 功能完备性 | 易用性 | 工具稳定性 |
|---|---|---|---|
| Gprof | + | + | + |
| SystemTap | ++ | ++ | ++ |
| Ftrace | +++ | +++ | +++ |
虽然,这些系统内核自带的工具有些功能已经很强大,但是这些工具的使用前提都是系统必须是完全启动的,也就是说对于系统启动过程中的内核状态函数的调用是完全无能为力的。如果要分析系统从启动到运行整个过程的状态必须借助其他工具如S2E等
关注作者公众号

参考文献
-
《GNU Gprof》:https://sourceware.org/binutils/docs-2.17/gprof/index.html
↩︎
-
《gprof使用和介绍》: http://blog.sina.com.cn/s/blog_4a471ff601013vud.html
↩︎
-
《Linux性能评测工具之一:gprof篇》: http://blog.csdn.net/stanjiang2010/article/details/5655143
↩︎
-
《用gprof分析程序性能》: http://www.berlinix.com/dev/gprof.php
↩︎
-
《ftrace – Function Tracer》:https://www.kernel.org/doc/Documentation/trace/ftrace.txt
↩︎
-
《ftrace简介》:https://www.ibm.com/developerworks/cn/linux/l-cn-ftrace/
↩︎
↩︎
↩︎
↩︎
↩︎
↩︎
↩︎
-
《使用ftrace 调试Linux 内核,第2 部分》:http://www.ibm.com/developerworks/cn/linux/l-cn-ftrace2/
↩︎
-
《 Linux内核调试工具 Ftrace 进阶使用手册》:http://blog.csdn.net/longerzone/article/details/16884703
↩︎
-
《Linux自检和SystemTap》:https://www.ibm.com/developerworks/cn/linux/l-systemtap/
↩︎
-
《内核检测工具SystemTap简介》: http://www.cnblogs.com/hazir/p/systemtap_introduction.html#top
↩︎