1.1 HDFS端口
|
参数 |
描述 |
默认 |
配置文件 |
例子值 |
|
fs.default.name namenode |
namenode高可用 RPC交互端口 |
8020 |
core-site.xml |
hdfs://master:8020/ |
|
dfs.http.address |
NameNode web管理端口 |
50070 |
hdfs- site.xml |
0.0.0.0:50070 |
|
dfs.datanode.address |
datanode的服务端口,用于数据传输 |
50010 |
hdfs -site.xml |
0.0.0.0:50010 |
|
dfs.datanode.ipc.address |
datanode的RPC服务器地址和端口 |
50020 |
hdfs-site.xml |
0.0.0.0:50020 |
|
dfs.datanode.http.address |
datanode的HTTP服务器和端口 |
50075 |
hdfs-site.xml |
0.0.0.0:50075 |
| fs.default.name | 非高可用的HDFS RPC通讯端口 | 9000 | hdfs-site.xml | 0.0.0.0:9000 |
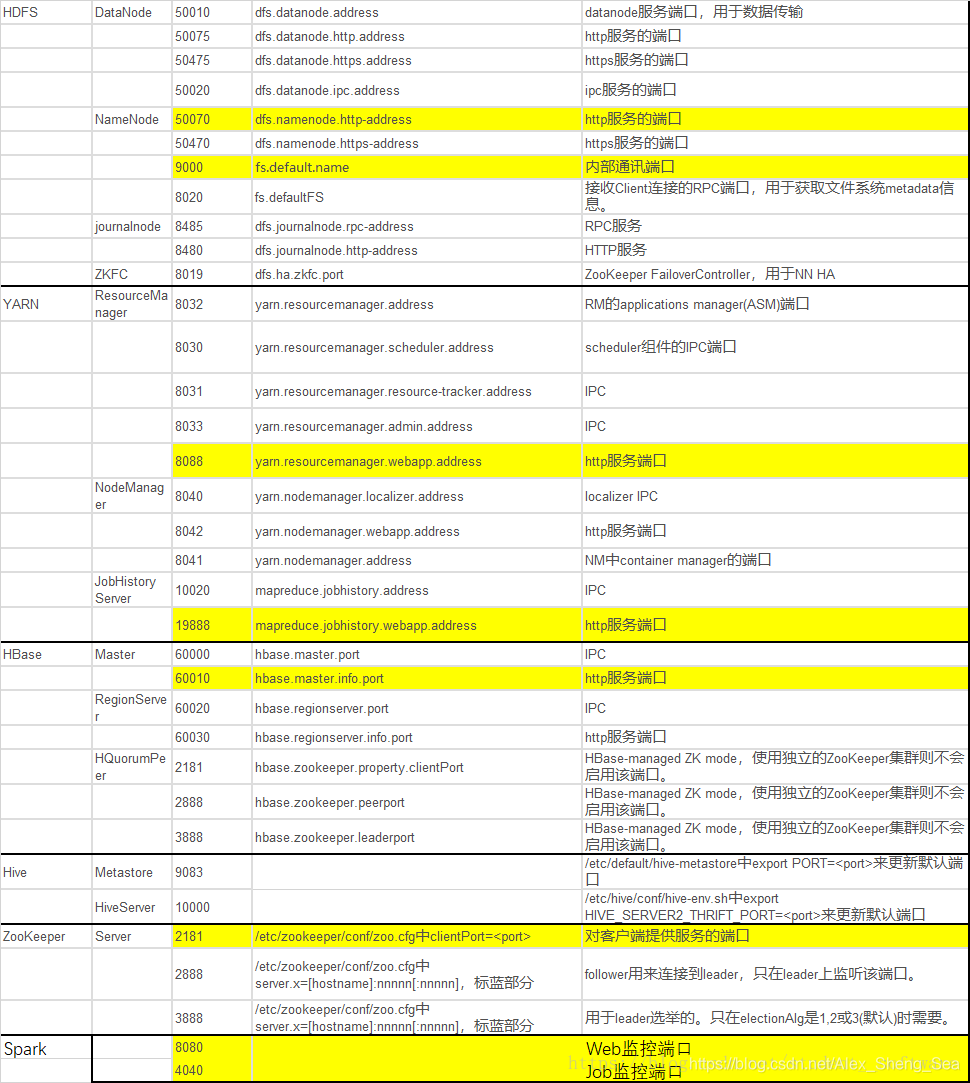
常见端口汇总:
Hadoop:
50070:HDFS WEB UI端口
8020 : 高可用的HDFS RPC端口
9000 : 非高可用的HDFS RPC端口
8088 : Yarn 的WEB UI 接口
8485 : JournalNode 的RPC端口
8019 : ZKFC端口
19888:jobhistory WEB UI端口
Zookeeper:
2181 : 客户端连接zookeeper的端口
2888 : zookeeper集群内通讯使用,Leader监听此端口
3888 : zookeeper端口 用于选举leader
Hbase:
60010:Hbase的master的WEB UI端口 (旧的) 新的是16010
60030:Hbase的regionServer的WEB UI 管理端口
Hive:
9083 : metastore服务默认监听端口
10000:Hive 的JDBC端口
Spark:
7077 : spark 的master与worker进行通讯的端口 standalone集群提交Application的端口
8080 : master的WEB UI端口 资源调度
8081 : worker的WEB UI 端口 资源调度
4040 : Driver的WEB UI 端口 任务调度
18080:Spark History Server的WEB UI 端口
Kafka:
9092: Kafka集群节点之间通信的RPC端口
Redis:
6379: Redis服务端口
CDH:
7180: Cloudera Manager WebUI端口
7182: Cloudera Manager Server 与 Agent 通讯端口
HUE:
8888: Hue WebUI 端口
1.2 HDFS的细节参数说明
①整个集群中所有的NamdeNode、DataNode、JournalNode而言,每个节点中的ClusterID相同
clusterID=CID-93fd95ec-4744-4970-ad8b-42a1bb2ab2a1
②整个集群中所有的NameNode、JournalNode、DataNode节点上,所有的NameSpaceID相同
namespaceID=1563477261
③整个集群中所有的DataNode,每个DataNode上blockpoolID相同,StorageID、DatanodeUuid不同
storageID=DS-55f77a76-67ec-4161-8bfa-4cbb3c7c83be
datanodeUuid=f9456c36-79b5-4333-9f04-835e1b08efeb
blockpoolID=BP-1080241145-10.70.24.84-1544533356457
④ layoutVersion
layoutVersion定义了HDFS持久化数据结构的版本号,它的值是负值。当HDFS的持久化数据结构发生了变化,如增加了一些其他的操作或者字段信息,则版本号会在原来的基础上减1。Hadoop 1.2.1版本中,layoutVersion的值是-41,它与Hadoop的发行版本号是两回事,如果layoutVersion的值变化了(通过减1变化,实际layoutVersion的值更小了),则如果能够读取原来旧版本的数据,必须执行一个升级(Upgrade)过程。layoutVersion主要在fsimage和edit日志文件、数据存储文件中使用。
⑤namespaceID
namespaceID唯一标识了HDFS,在格式化HDFS的时候指定了它的值。在HDFS集群启动以后,使用namespaceID来识别集群中的Datanode节点,也就是说,在HDFS集群启动的时候,各个Datanode会自动向Namenode注册获取到namespaceID的值,然后将该值存储在Datanode节点的VERSION文件中。
⑥cTime
cTime表示Namenode存储对象(即FSImage对象)创建的时间,但是在初始化时它的值为0。如果由于layoutVersion发生变化触发了一次升级过程,则会更新该事件字段的值。
⑦checkpointTime
checkpointTime用来控制检查点(Checkpoint)的执行,为了在集群中获取到同步的时间,使用通过调用FSNamesystem对象的的now方法来生成时间戳。Hadoop使用检查点技术来实现Namenode存储数据的可靠性,如果因为Namenode节点宕机而无法恢复数据,则整个集群将无法工作,我们必须杜绝这种事情的发生,进而采用检查点技术。
⑧in_use.lock锁文件
调用sd.lock()会创建一个${dfs.name.dir}/in_use.lock锁文件,用来保证当前只有同一个进程能够执行格式化操作
//in_use.lock文件中的数字是分别对应namenode和datanode节点中namenode、datanode的进程号
[root@datafactory name]# more in_use.lock
5385@hadoop01.rc.com
[root@datafactory name]# jps
12820 PrestoServer
5735 DFSZKFailoverController
14424 RunJar
14233 RunJar
5385 NameNode
5866 ResourceManager
6783 Jps