目录
前言
本文只是记录自己的学习过程,并不是面向技术向的硬核文章。
U-net简介
U-net首见于这篇论文
U-Net: Convolutional Networks for Biomedical
,距今7年,算是比较老的模型了,但是它的引用量突破了四万,由此看来,它的重要性不言而喻。U-net初始论文的标题就告诉我们,它是一个用于医学图像分割的卷积神经网络。在医学领域,如果仅仅对图像进行分类,这是不够的。医生在对病人进行医疗诊断时,需要综合更多的信息来得出病情的判断。
所以,U-net做的事就是,在已有图像类别的基础上,对图像进行进一步分类—即像素这一级别的分类(图像分割),定位每个像素的类别,使图像中解剖或病理结构的变化更加清晰,最后输出根据像素点的类别而分割好的图像。
U-net网络架构理解
论文中的U-net网络架构如下:
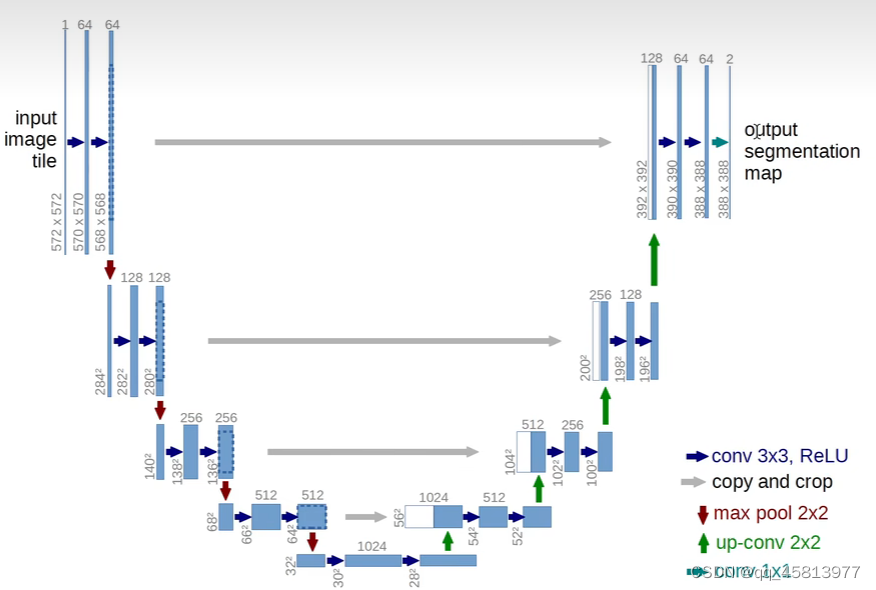
# 上图图标以及操作讲解
蓝色图标:3*3 卷积操作 pad = 0 stride = 1 + ReLU激活函数(稀疏激活、收敛速度快、梯度计算简单)
红色图标:2*2 最大池化操作 pad = 0 stride = 2 下采样
# 每次下采样步骤后通道数翻倍,即64--->128--->256--->512--->1024 共四步
## 反卷积
反卷积本质还是卷积,并不是卷积的逆操作,而且也无法还原成原来的图像,只能还原图像的大小
绿色图标:up-Conv 上采样,每次上采样图像大小翻倍,通道数减半
青色图标:Conv 1*1 2个1×1的卷积核把64个特征通道变成2个,也就是最后的388×388×2,这里就是一个二分类的操作,
把图片分成背景和目标两个类别。
灰色图标:对左边下采样得到的特征图进行裁剪复制,与右边对应通道数的上采样输出特征图合并。
说明:在卷积过程中,我们会丢失边缘像素信息,此外,而上采样并不能恢复图像,只能恢复大小,所以需要复制
左边的特征图然后再和右边的特征图合并,弥补缺失的信息,使得最终结果更加准确。
#同样,上采样也是有四步,特点是,图像大小翻倍,通道数减半可以看到图中U-net的网络结构呈U形,左半部分我们称之为编码器,右半部分我们称之为解码器。编码器将图片不断压缩,分辨率变得越来越低,解码器将图像分辨率不断还原,分辨率逐步升高。下面我们针对上图,对网络操作流程进行说明。
输入与输出说明
我们的输入图像大小为572,572单通道,输出为388,388二通道。图像分割不应该原图和输出图片大小一样吗?实质上,U-net这边做的处理是,根据预先设置的输出图像大小,然后对输入图像进行镜像填充。具体怎么做的呢?
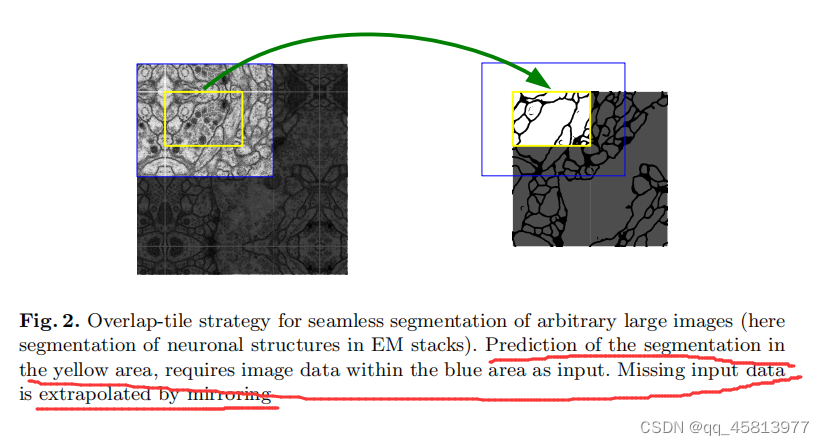
如上图所示,预测的分割区域在黄色区域,蓝色区域作为输入,提供更多的局部信息,但实质上我们是没有那么大的蓝色区域的,所以缺失的数据就以镜像的方式被填充了。这样的操作会带来图像重叠问题,即某一图像的周围可能会和另一张图片重叠。因此作者在卷积时只使用有效部分。
下采样
网络左半部分为下采样,一共有四步。
#input 572*572*1 ---(卷积)--->570*570*64(ReLu激活)---(卷积)--->568*568*64(ReLu)激活
下采样
step1:568*568*64---(max pooling)--->284*284*128---(卷积)--->282*282*128(ReLu激活)---
(卷积)--->280*280*128(ReLu激活)
之后的三步与step1类似
上采样以及输出
网络右半部分为上采样,同样有四步,与左半部分不同的是,它每次进行上采样采用的都是反卷积(pytorch总的transpose函数即可实现),而且每次都会引入裁剪后高分辨率的图像信息。
step1:28*28*1024---(反卷积)--->56*56*512+左半部分64*64*512---(裁剪合并)=56*56*1024
---(卷积)--->54*54*512(ReLu激活)---(卷积)--->52*52*512(ReLu激活)
接下来三步与上面一步类似
1*1Conv:
388*388*64--->388*388*2 将前景和背景分割出来,变成一个二分类问题
U-net的特点
- U-net是一个完全的卷积层,所以输入和输出图像的大小可以是任意的
- 分为编码器和解码器,编码器将图片不断压缩,分辨率变得越来越低,解码器将图像分辨率不断还原,分辨率逐步升高
- 解码器在解码过程中会用到编码器提取的特征
谷歌Colab复现基于U-Net的眼底图像血管分割
在学习过U-net的相关资料后,我准备通过学习代码来加深对U-net的理解,同时记录学习过程中遇到的坑,正好之前浏览博文的时候有过相关收藏,具体链接:
基于U-Net的眼底图像血管分割实例
。
1.环境配置
查看是否有相关的库,具体如下:

由于这个代码已经比较久了,所以里面有些环境并不是很适配,所以在复现的时候遇到了不少坑。笔者在实验过程中发现colab有上面所有的库,只不过需要做些改动。
#首先 colab中的h5py版本是比较高的,到时候导入模型的时候会报解码错误
所以,我们需要执行指令
!pip uninstall h5py
!pip install h5py==2.7.1
#其次,colab的tensorflow默认是2.x版本,而这边是1.x版本,所以,我们需要进行tensorflow版本切换
%tensorflow_version 可以查看当前的tf环境,以及可用的版本
%tensorflow_version 1.x 切换到1.x环境
train文件中,导入的Adam应该改为adam_v2
导入的sgd语句变为from tensorflow.keras.optimizers import SGD

2.数据获取及其处理
使用的数据集为DRIVE数据集,训练图片为40张,测试图片为20张。这个数据集相当小,所以我们需要对其进行数据增强,以得到更好的训练效果。
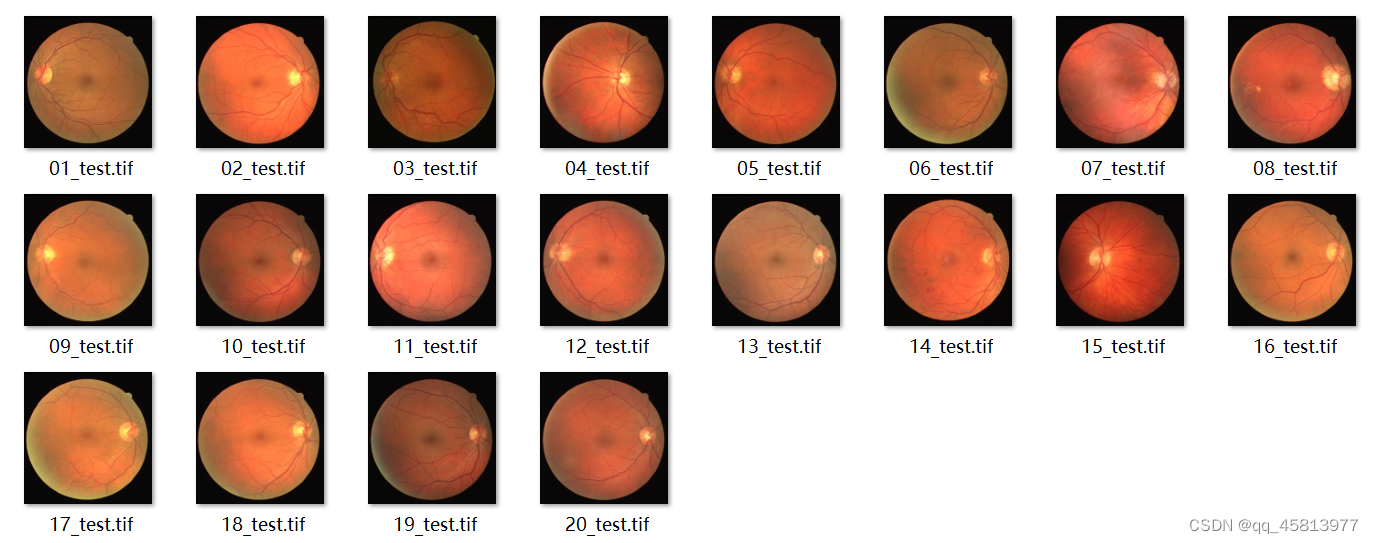
图一 眼底图
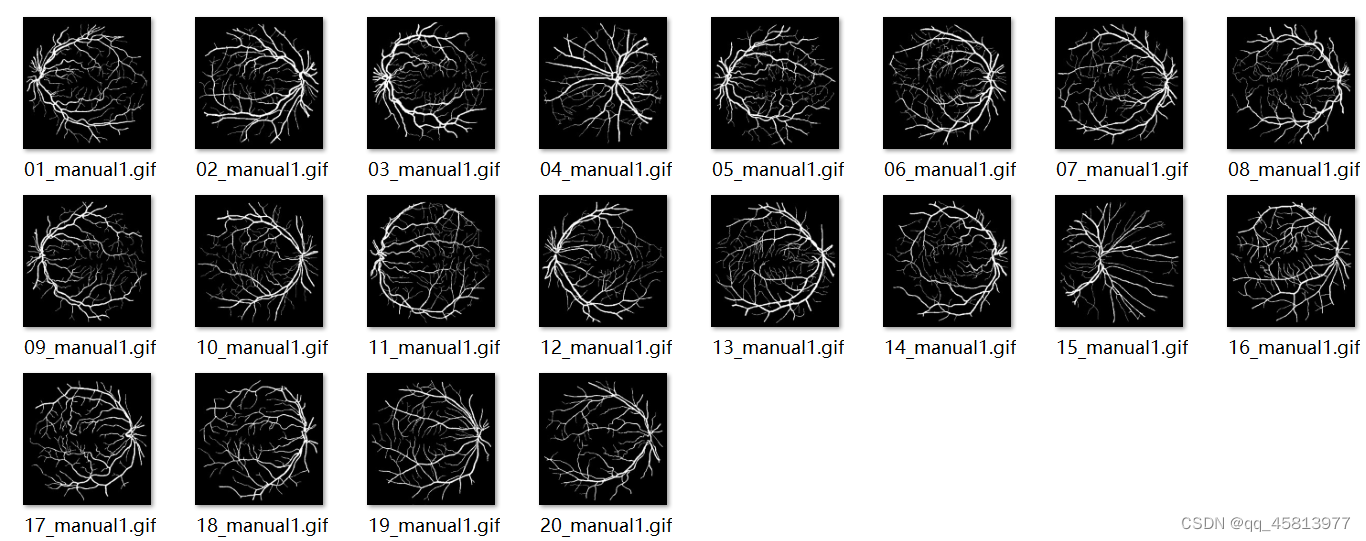
图二 血管图

图三 眼球轮廓图
3.代码框架
3.1 数据预处理:
#对比度受限的直方图均衡化,用于增强图像的对比度
def clahe_equalized(imgs):
assert (len(imgs.shape)==4) #4D arrays
assert (imgs.shape[1]==1) #check the channel is 1
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8,8)) #限制在2
imgs_equalized = np.empty(imgs.shape) # 创建一个和图像矩阵大小一样的矩阵
for i in range(imgs.shape[0]):
imgs_equalized[i,0] = clahe.apply(np.array(imgs[i,0], dtype = np.uint8))
return imgs_equalized
#伽马变换用来图像增强,其提升了暗部细节,简单来说就是通过非线性变换
#让图像从暴光强度的线性响应变得更接近人眼感受的响应,即将漂白(相机曝光)或过暗(曝光不足)的图片,进行矫正。
def adjust_gamma(imgs, gamma=1.0):
assert (len(imgs.shape)==4) #4D arrays
assert (imgs.shape[1]==1) #check the channel is 1
invGamma = 1.0 / gamma
table = np.array([((i / 255.0) ** invGamma) * 255 for i in np.arange(0, 256)]).astype("uint8")
new_imgs = np.empty(imgs.shape)
for i in range(imgs.shape[0]):
new_imgs[i,0] = cv2.LUT(np.array(imgs[i,0], dtype = np.uint8), table)
return new_imgs
3.2 数据增强:
def extract_random(full_imgs,full_masks, patch_h,patch_w, N_patches, inside=True):
if (N_patches%full_imgs.shape[0] != 0):
print("N_patches: please enter a multiple of 20")
exit()
# 进行断言判断,满足这些条件才会继续进行下去
assert (len(full_imgs.shape)==4 and len(full_masks.shape)==4) #4D arrays
assert (full_imgs.shape[1]==1 or full_imgs.shape[1]==3) #check the channel is 1 or 3
assert (full_masks.shape[1]==1) #masks only black and white
assert (full_imgs.shape[2] == full_masks.shape[2] and full_imgs.shape[3] == full_masks.shape[3])
patches = np.empty((N_patches,full_imgs.shape[1],patch_h,patch_w))
patches_masks = np.empty((N_patches,full_masks.shape[1],patch_h,patch_w))
img_h = full_imgs.shape[2] #height of the full image
img_w = full_imgs.shape[3] #width of the full image
# (0,0) in the center of the image
patch_per_img = int(N_patches/full_imgs.shape[0]) #N_patches equally divided in the full images
print("patches per full image: " +str(patch_per_img))
iter_tot = 0 #iter over the total numbe rof patches (N_patches)
for i in range(full_imgs.shape[0]): #loop over the full images
k=0
while k <patch_per_img:
# 随机选择x,y中心点
x_center = random.randint(0+int(patch_w/2),img_w-int(patch_w/2))
y_center = random.randint(0+int(patch_h/2),img_h-int(patch_h/2))
#检查这个patch是不是全部在FOV中
if inside==True:
if is_patch_inside_FOV(x_center,y_center,img_w,img_h,patch_h)==False:
continue
patch = full_imgs[i,:,y_center-int(patch_h/2):y_center+int(patch_h/2),x_center-int(patch_w/2):x_center+int(patch_w/2)]
patch_mask = full_masks[i,:,y_center-int(patch_h/2):y_center+int(patch_h/2),x_center-int(patch_w/2):x_center+int(patch_w/2)]
patches[iter_tot]=patch
patches_masks[iter_tot]=patch_mask
iter_tot +=1 #total
k+=1 #per full_img
return patches, patches_masks #最终返回该patch及其对应的mask
3.3 U-net网络代码:
#整体经过两次下采样,两次上采样,与原论文略有不同。
#channels_first代表通道位于长宽前面。
#padding = 'same'代表对输入图像进行补0,保证输入与输出的大小是一致的,这与U-net原文进行的valid卷积有所不同
def get_unet(n_ch,patch_height,patch_width):
inputs = Input(shape=(n_ch,patch_height,patch_width))
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(inputs)
conv1 = Dropout(0.2)(conv1)
conv1 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv1)
pool1 = MaxPooling2D((2, 2))(conv1)
#
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(pool1)
conv2 = Dropout(0.2)(conv2)
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv2)
pool2 = MaxPooling2D((2, 2))(conv2)
#
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same',data_format='channels_first')(pool2)
conv3 = Dropout(0.2)(conv3)
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv3)
up1 = UpSampling2D(size=(2, 2))(conv3)
up1 = concatenate([conv2,up1],axis=1)
conv4 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(up1)
conv4 = Dropout(0.2)(conv4)
conv4 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv4)
#
up2 = UpSampling2D(size=(2, 2))(conv4)
up2 = concatenate([conv1,up2], axis=1)
conv5 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(up2)
conv5 = Dropout(0.2)(conv5)
conv5 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv5)
#
conv6 = Conv2D(2, (1, 1), activation='relu',padding='same',data_format='channels_first')(conv5)
conv6 = core.Reshape((2,patch_height*patch_width))(conv6)
conv6 = core.Permute((2,1))(conv6)
############
conv7 = core.Activation('softmax')(conv6)
model = Model(inputs=inputs, outputs=conv7)
# sgd = SGD(lr=0.01, decay=1e-6, momentum=0.3, nesterov=False)
model.compile(optimizer='sgd', loss='categorical_crossentropy',metrics=['accuracy'])
return model
3.4 代码运行结果
#先进行数据预处理
%run ./prepare_datasets_DRIVE.py
#运行代码
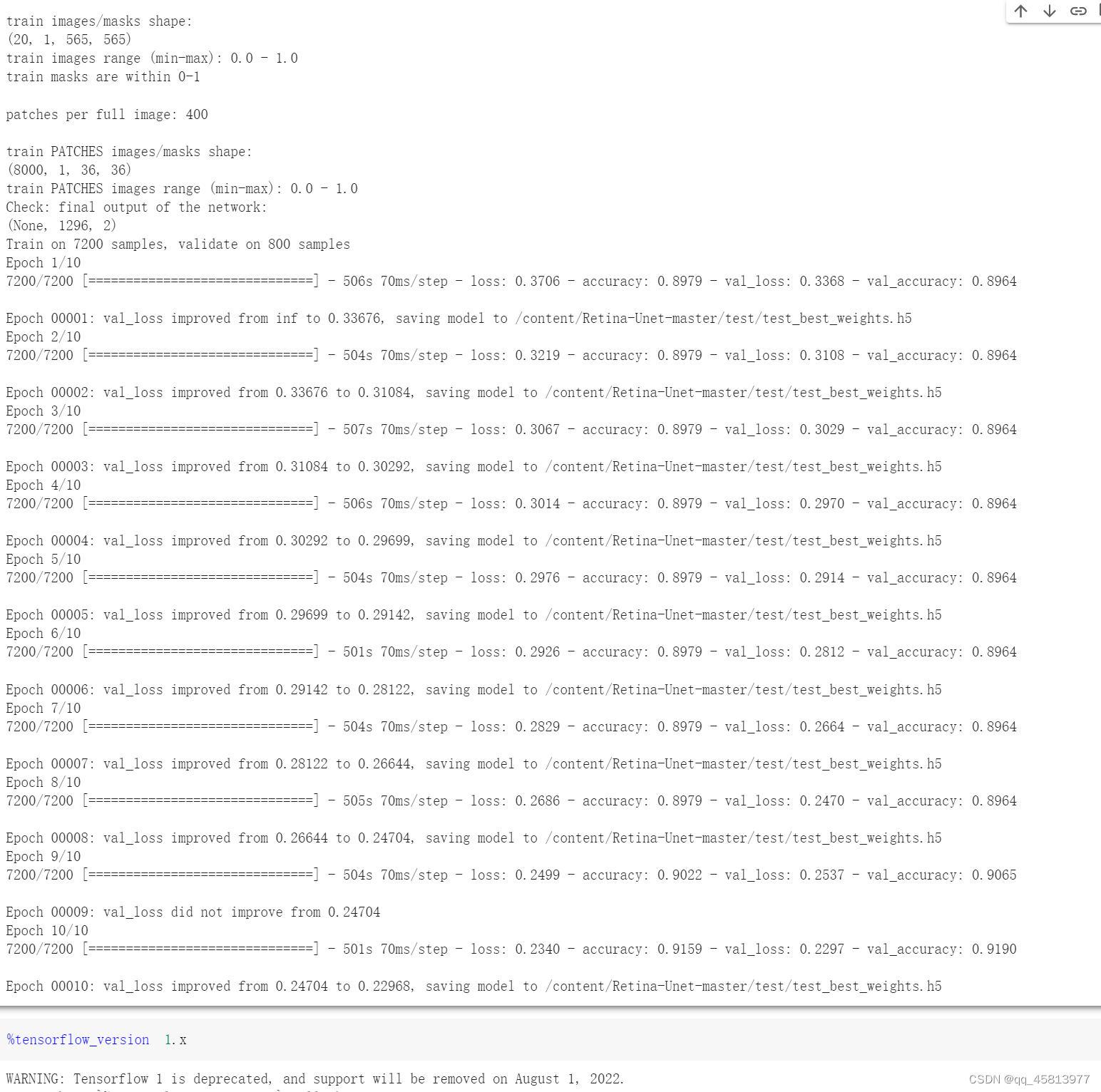
%run ./retinaNN_training.py代码运行结果如下,由于我使用的是CPU,N_subimgs=9000,10个epoches,裁剪大小为36*36,所以运行速度不是很快,每个epoch需要跑500s左右。可以看到在前8个epoch,准确率一直没有变换,直到第9个epoch,准确率才逐步上升。
总结
U-net网络架构较为简单,理解起来也比较容易。它的网络框架完全对称,前半部分是编码, 它的作用是特征提取,进行的下采样可以降低运算量以及增加感受野的大小。后半部分是解码, 也就是上采样过程,即利用前面编码的抽象特征来恢复到原图尺寸的过程, 最终得到分割结果。
在具体实现这个网络的时候,我通过github上的开源代码,以及google的colab将U-Net的眼底图像血管分割任务进行了复现。在解决无数的bug和坑之后,终于在colab上跑通了这个代码。首先是根据数据集进行预处理和数据增强,再之后就是实现网络框架,在数据集上的准确率达到了90%以上。
收获就是学会了U-net网络以及回顾Colab的使用方法,初步在代码上了解了图像分割任务的流程,对于图像如何进行预处理,在数据集过少时,如何进行数据增强,拓增数据。由于时间有限,以及这个代码实在是与当前环境不兼容,没能将相关评测指标进行可视化,对代码运行情况进行进一步分析。下一步可以学习改进U-net的方法以及以U-net为基础的网络架构。