参考连接:
http://www.cnblogs.com/supersteven/archive/2012/09/01/2666565.html
首先非常感谢作者不辞辛苦整理与分享。
根据作者描述以及提供的代码和数据我主要做了一下事情:
(1)进行本地测试运行,同时记录下代码每个大的模块主要逻辑。
(2)特别利用作者提供的NDCG效果评估代码,仔细研究了下如何对排序效果进行测评。
1、业务背景
世纪佳缘推荐系统比赛,根据用户在首页的互动行为以及用户的基础属性,提高推荐的准确度。主要的操作行为:发件(msg),查看资料页(click),曝光(rec),其中动作强度为发件>查看资料>曝光。主要用户属性:性别,年龄,婚姻,学历,收入等13个。
2、原作者大体推荐方法
“Popularity = msg_weight * msg_times + click_weight * click_times + rec_weight * rec_times”
即根据被推荐用户的受欢迎度进行排序,最终利用NDCG测评方法与实践用户操作行为进行比较。期望好的推荐结果是,被推荐用户的受欢迎度越大,动作强度越大。
3、代码主要模块,和功能:
- 0数据说明
train.txt :
USER_ID_A: 主动方用户
USER_ID_B:被曝光用户,即推荐给A的用户。
ROUND: 该用户A推荐次数
ACTION:用户A对用户B产生的行为,rec(B曝光给A),click(A查看了B的资料页),msg(A发送消息给B)
注:用户A对用户B产生3中行为,train.txt存三条记录。
test.txt: 只包含USER_ID_A,USER_ID_B,ROUND
profile_f.txt: 女性用户基本资料信息,共34个特征。
profile_m.txt: 男性用户基本资料信息,共34个特征
预测:测试集中,用户A对用户B的操作行为。(这里的预测是指,预测已经推给用户A的用户B,基于模型重新排序后,用户的点击情况,不是推出一批新的用户给A)
注意:预测用户A对用户B产生的行为,取行为最强(msg>click>rec)的做为最后预测目标- 1.split_data: 训练数据分为测试集与训练集
import split_data
split_data.split_data('train.txt', 2, 'train_train.txt', 'train_test.txt')
包含主要步骤:
1)利用随机数,将train.txt分割为训练集和测试集5:1;分别输出到train_train.txt,train_test.txt占1/6。 方便后期模型交叉验证。- 2.compute_popularity: 计算userB受欢迎度得分
import compute_user_popularity
popDict = compute_user_popularity.compute_user_popularity('train_train.txt', 'user_popularity.txt')
包含主要步骤:
1) 计算userB被操作行为,即userB被推荐次数,被点击click次数,收到msg次数。K-v格式存储: key=“userB action“, v=次数
2) 计算用户受欢迎得分: score_b=w1*rec+w2*click+w3*msg,按(userB,score) 存入list
3) 按得分进行降序排序,后存入user_popularity.txt- 3.train_sort
import train_sort
result = train_sort.train_sort('train.txt', 'train_sort.txt')
主要步骤:
1)对train.txt按user_A,升序排列,并输出到train_sort.txt
方便后面对userA的交互用户B进行处理。- 4.labels_train_v2: 训练集处理
import labels_train
labels_train.labels_train_v2('train_sort.txt', 'labels_train.txt', 'user_recommend.txt')
主要步骤:
1)求与用户A交往多次的用户B,B被操作最强的行为。
小样本测试结果:
"因records的记录过长没法追踪每个步骤的计算结果,所以截取少量数据查看代码"
test_rec=[]
test_rec=['2 104 76 rec\n',
'2 104 78 rec\n',
'2 442 35 rec\n',
'2 442 64 rec\n',
'2 523 9 rec\n',
'2 1445 36 rec\n',
'2 4101 36 rec\n',
'2 5386 26 rec\n',
'2 5386 66 rec\n',
'2 7143 42 rec\n',
'10 26047 64 rec\n',
'10 26047 64 msg\n',
'10 26047 64 click\n',
'11 26047 64 click\n']
"""计算后效果如下:"
labels ['0 0 0 0 0 0 0', '2', '1']
Records ['2 104 442 523 1445 4101 5386 7143', '10 26047', '11 26047']
也就是求: lables: 与用户A交互的用户B,按用户B去重且取交互动作强的行为存储。保存到labels_train.txt
Records: 与用户A交互的用户B,去重后存储,保存到user_recommend.txt
"""
- 5.compute_ranks
import compute_ranks
compute_ranks.compute_ranks_using_popularity('user_recommend.txt', 'user_popularity.txt', 'myranks_train.txt') (这里的myranks_train.txt ,应该是rank_file)
主要步骤:
1) 计算与用户A互动过的用户B的受欢迎度。
2) 在用户A中,按受欢迎度对B重新进行排序。
3) 按user_recommend.txt用户A对应的用户B的排序,保存用户A对应的用户B的排名,并输出到rank_file
如下: 是某个用户A,基于模型后的排名

- 6.evaluate
import evaluate
evaluate.evaluate('labels_train.txt', 'myranks_train.txt') (这里的myranks_train.txt ,应该是rank_file)
主要步骤:
1) 计算模型的DCG
2) 计算理想ideaDCG
3) 求NDCG=DCG/ideaDCG
4) 求总的平均NDCG,作为最后的评判标准,值越大越好。
4、模型NDCG评分
参考:
https://en.wikipedia.org/wiki/Discounted_cumulative_gain
NDCG是一种衡量排序质量的评价指标,该指标考虑了所有元素的相关性,而不是MAP这种二元情况。
1)主要指标说明
NDCG@10指取top10个被推荐用户进行效果评估,该值越大,排序质量越好。
NDCG=DCG/ideaDCG; 全局NDCG为总的平均NDCG
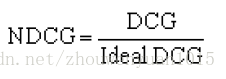
其中,表示模型给出的排序中,排名为的候选会员的实际 ACTION 值(msg=2,click=1,rec=0)
ideaDCG 表示按实际动作强度排序后的DCG
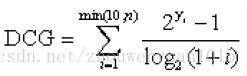
2)计算实例:
注:以下操作行为,做了处理(如果A对B产生多个行为,取行为最强的,msg(2)>click(1)>rec(0))
用户A对20个用户操作情况
对应的操作行为 ‘0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1\n
对应基于模型的排名 14 15 8 3 16 19 6 10 13 11 18 5 20 17 1 4 2 12 7 9
a. 模型DCG
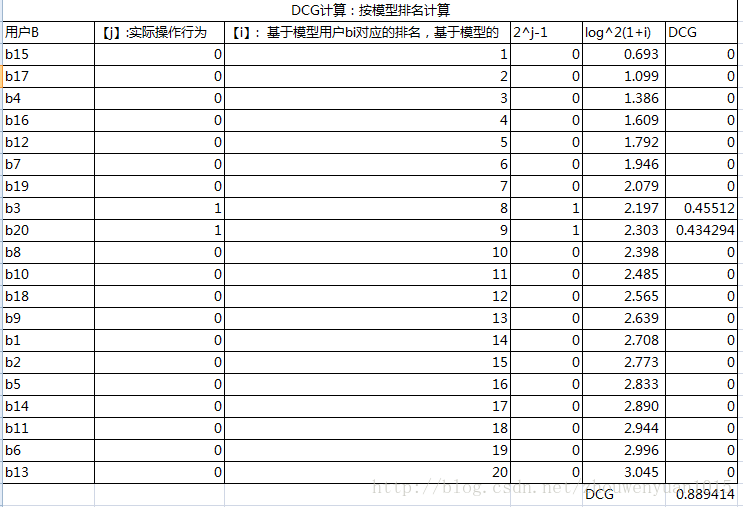
b. ideaDCG(即基于实际action排名后计算DCG)
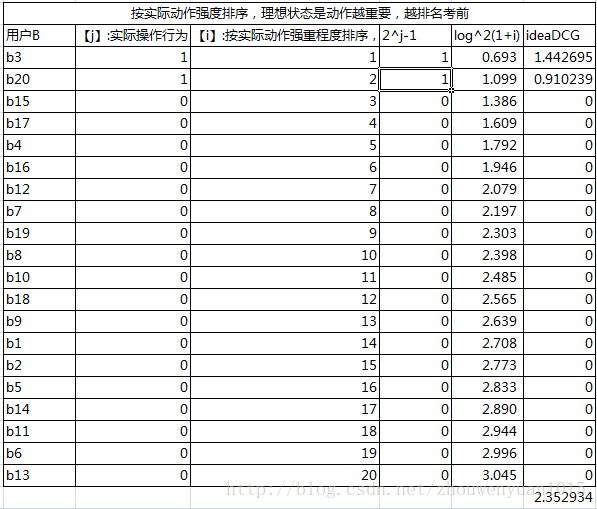
c. 最终的NDCG