前言
(搬自我自己的简书笔记,简书老是抽风锁文章,还是慢慢移动到csdn吧~20220810)
很久没有写读书笔记了。最近翻公众号,发现一个以前在我公司实习的小朋友的公众号里面满满的工作小结和阅读笔记,不禁感慨学习如逆水行舟,不进则退。
最近读梁永安教授的《阅读、游历和爱情》,里面有一段话非常触动,“如何衡量自我价值?其实很简单:每天都反思一下自己,看看在知识层面有没有增加?文化事业的宽度有没有扩大?情感的含量有没有更加丰富?行动性有没有增强?”。和吾日三省吾身基本一个意思。工作多年的我,慢慢的进入了工作的舒适区,自觉每天完成工作即可,失去了原本对新知识的探索和看到优秀内容的总结之心,实在是不应该。
自我反思结束,今天主要记录一下我上周看到的关于感受野的一些笔记和思考,感受野是深度网络的一个基础了,衡量了在某层
1
×
1
1\times 1
1
×
1
区域实际接收到输入图片的
N
×
N
N\times N
N
×
N
区域的视野的信息量,显然随着网络的加深,每个点的感受野增加,feature map的分辨率逐渐降低(feature map的H,W参数逐渐减小),信息的层次越来越抽象。那么带着几个问题来看待感受野:
- 给定一个网络,你可以计算或者估算感受野区域大小吗?可以得到有效的padding和Stride吗?
- 感受野是越大越好吗?
- 如何理解在分类网络、目标检测网络和分割网络中,感受野的影响?
- 基于Anchor的目标检测来说,如何根据感受野还设置anchor尺寸?为什么有时候我们自己设置的Anchor效果不佳?
- 我们自己设置网络结构的时候,应该怎么设置感受野的范围?
一、理解感受野
感受野Receptive Feild听起来是一个很高大上的词,实际可以理解为感受区域。用我们的眼睛做类比,我们可以看到的区域就是我们人眼的感受野,显然在极限情况下,我们可以看到188度区域内的所有画面,这个就是理论感受野。但是我们对感受野区域中的感知程度是不同的,比如你能聚焦眼球区域的中心,但是对于边缘的信息只能获得一个大概,如果在你视野的边界放一串数字,那么要么数字足够大,否则只能通过移动眼球,让眼球聚焦在这串数字上,才能识别这串数字的内容了。也就是说,虽然我们的感受野很大,但是有效的感受野区域是有限的(当眼球不动的时候,可以聚焦识别的区域),或者说我们对其他区域的权重不够大。这种情况下,要么移动感受野的中心(转动眼球),要么这部分区域本身的信息量足够大可以抵消该区域的低权重(数字很大),否则无法完全利用我们能看到的感受野。
放到深度学习上也是类似的。
感受野:在深度网络中,每个神经元节点都对应输入图像的某个确定区域,仅该区域的图像内容能够对相应神经元的激活产生影响,这个区域就是该神经元的感受野。
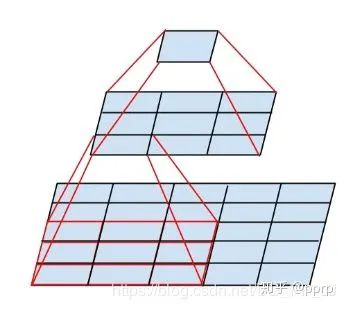
我们的理论感受野是指能够对当前层能够感受到的区域;而实际感受野区域则会更小。如下面张图所示,底层
5
×
5
5\times5
5
×
5
经过两个
3
×
3
3\times3
3
×
3
卷积网络得到顶层的一个
1
×
1
1\times1
1
×
1
区域。那么顶层的感受野区域为
5
×
5
5\times5
5
×
5
。其他区域的信息都不会影响这个区域。
有效的感受野区域更小,在卷积层权重一致的情况下,有效感受野是一个高斯分布:

上面四张图体现了两个区域:随着网络的加深,有效感受野的区域所占比重越来越小,随机权重和relu的非线性可以增加网络的随机性,却也有可能进一步减少了有效感受野的区域。
下面这种图体现了不同激活函数对感受野的影响,上面一行体现了不同激活函数基本也都满足高斯分布;下面一行则是卷积、采样和空洞卷积的有效感受野区域,可见采样和空洞卷积可以增加有效感受野:

比如上面的例子中,底层中间节点参与了中间层9个节点的计算,而右下角的节点只参与了中间层右下角的节点计算,因此如果卷积层的权重都是1,那么中间节点的权重显然是边缘权重的9倍。但是幸运的是我们网络上是可以学习的~
下面体现了通过学习可以增加感受野边缘区域的权重,虽然边缘区域的权重还是略低于中心区域。这个就像我们参与考试的时候一样,作弊的同学通过一次次血的教训习得用余光判断老师位置和目光的能力,而乖乖仔们则因为较少训练而不具备这个能力。可见学习的重要性!

二、感受野的计算
2.1 简单介绍和相关其他的计算方式
这里主要是针对理论感受野的计算,通过上面的讲述,我们知道有效感受野是无法事先计算得到的,但是有效感受野的上界是理论感受野。
感受野的计算方式我接触到的有两种,其中一种是知乎上的700+赞回答
卷积神经网络的感受野
,老久老久以前我也是这么计算的,从输入层开始按照公式一层层得到输出层的感受野。但是这种方式计算得到的感受野会偏大一点,因为没有考虑到层间重合的问题。

下面重点讲一下谷歌研究并且开源了相应计算库的感受野计算方式。
Computing Receptive Fields of Convolutional Neural Networks
,非常建议大家一定要去看看这篇文章,里面各种示例都结合的特别好,数学推导也很赞。我这边只会将一些我自己认为很有用的内容,并不如原文全面和理论。
其对应的开源计算方式地址:
Tensorflow:
https://github.com/google-research/receptive_field
Pytorch:
https://github.com/Fangyh09/pytorch-receptive-field
这种方式和上面知乎方式的计算顺序不同,是从最后一层开始逆推得到输入层的感受野范围的。
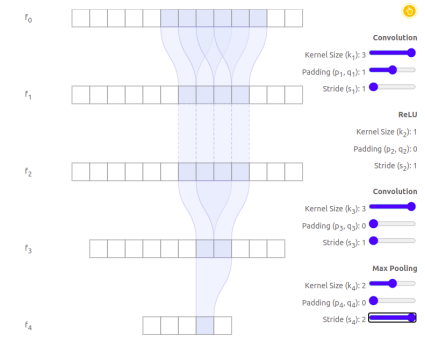
先来看一个一维上的例子(二维乃至多维的也是类似的),如下图所示。这是一个四层网络,经历了卷积层、激活层、卷积层和最大池化层。按照上面那种知乎的方式,输入层
r
=
1
r=1
r
=
1
,经历
3
×
3
,
s
=
1
3\times 3 ,s=1
3
×
3
,
s
=
1
卷积层之后,
r
=
1
+
2
=
3
r=1+2=3
r
=
1
+
2
=
3
;经过激活层,感受野不改变;经过
3
×
3
,
s
=
1
3\times 3,s=1
3
×
3
,
s
=
1
卷积层,
r
=
3
+
2
=
5
r = 3+2 = 5
r
=
3
+
2
=
5
;经过
s
=
2
s=2
s
=
2
的池化层之后,
r
=
5
×
2
=
10
r= 5\times 2=10
r
=
5
×
2
=
10
.
但是通过下面这张图可以明显看到,对于输出层的一个point来说,对应于感受野应该是6.
这是因为在maxpooling层采用的2个points,他们的底层感受野是有很大重合的。因此不能这么计算。
谷歌提出的方式是从输出层开始计算,逆推到输入层。首先定义一下符号:

务必理解上面这段定义,
r
l
r_l
r
l
表示的是对于输出层而言,
l
l
l
层的感受野范围。比如上面这个例子中,
r
4
=
1
r_4=1
r
4
=
1
因为第四层是输出层;
r
3
=
2
r_3=2
r
3
=
2
这是第三层相对于输出层的感受野区域,从图上的紫色部分可以直接看出来。
2.3 单路网络感受野
这一节讲解单路网络的感受野推导,下一节将类似Inception-net这类的多路网络。这一节是下一节的基础。
下面从三个推论给出最终的公式:
####推论1:对于最后倒数第二层而言,
r
L
−
1
=
k
L
r_{L-1}=k_L
r
L
−
1
=
k
L
这意味着倒数第二层的感受野只和kernel_size相关,而不和stride相关。这是因为这一层直接和输出层相连,因此输出层的一个感受野直接感受到的points就是其感受野。放两个例子大家自己感受一下。

推论2:对于k=1的中间层,前一层的感受野公式
r
l
−
1
=
s
l
×
r
l
−
(
s
l
−
1
)
r_{l-1}=s_l \times r_l-(s_l-1)
r
l
−
1
=
s
l
×
r
l
−
(
s
l
−
1
)
。
结合例子来看,已知
r
l
=
2
r_l=2
r
l
=
2
,那么通过下面这个图可以知道
f
l
=
4
f_l=4
f
l
=
4
(
f
l
−
1
f_{l-1}
f
l
−
1
层的第一个紫色区块到第二个紫色区块的长度),这个长度就等于
s
l
×
r
l
−
(
s
l
−
1
)
=
6
−
2
=
4
s_l\times r_l-(s_l-1)=6-2=4
s
l
×
r
l
−
(
s
l
−
1
)
=
6
−
2
=
4
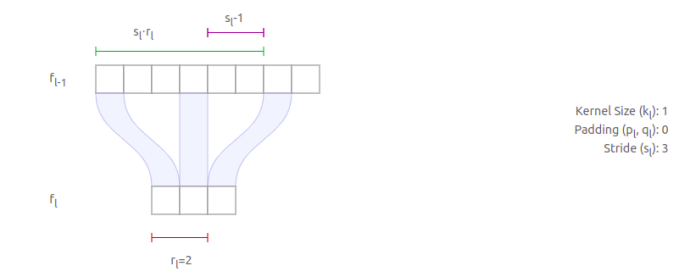
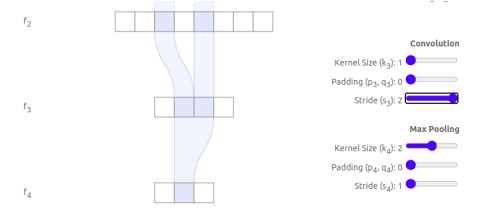
类似的,读者可以计算一下下面这个
f
2
f_2
f
2
层的感受野。
推论3:对于k>1的中间层,前一层的感受野公式
r
l
−
1
=
s
l
×
r
l
+
(
k
l
−
s
l
)
r_{l-1} = s_l \times r_l+(k_l-s_l)
r
l
−
1
=
s
l
×
r
l
+
(
k
l
−
s
l
)
.
推论3是推论2的衍生,对于
k
l
>
1
k_l>1
k
l
>
1
的情况,
k
l
=
1
k_l=1
k
l
=
1
对应的point相当于卷积对应的中心点。那么
k
l
>
1
k_l>1
k
l
>
1
所对应的感受野就是在
k
l
=
1
k_l=1
k
l
=
1
的感受野外部左右延伸
(
k
l
−
1
)
/
2
(k_l-1)/2
(
k
l
−
1
)
/2
。如下图所示:
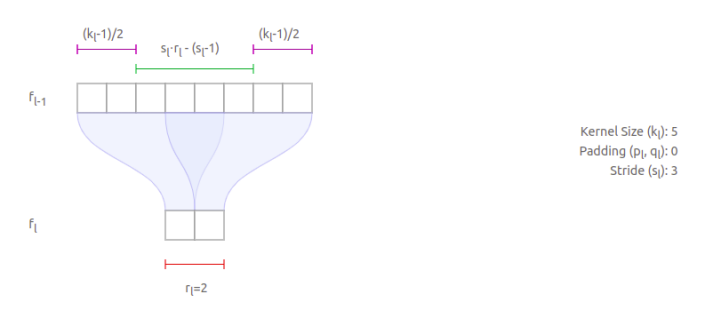
推论2其实是推论3的一个个例而已,方便读者理解推论3.因此可以只需要记住推论1和推论3即可。根据上面的推论,我们尝试推理VGG16网络:
推论3可知,对于一个
k
=
3
×
3
,
s
=
1
k= 3\times 3, s=1
k
=
3
×
3
,
s
=
1
的卷积,
r
l
−
1
=
r
l
+
2
r_{l-1}=r_l+2
r
l
−
1
=
r
l
+
2
,对于一个
k
=
2
,
s
=
2
k=2,s=2
k
=
2
,
s
=
2
的maxpooling层,
r
l
−
1
=
2
×
r
l
r_{l-1}=2\times r_l
r
l
−
1
=
2
×
r
l
.
因此从输出层开始逆推得到如下感受野
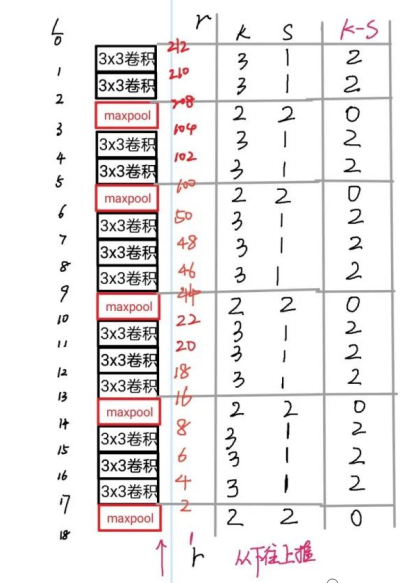
也就是说,输出层的一个
1
×
1
1\times 1
1
×
1
区域感受野为输入层的
212
×
212
212\times212
212
×
212
区域;等效的步长为过程中步长累积
s
=
2
5
=
32
s = 2^5=32
s
=
2
5
=
32
;等效padding可以通过
f
i
n
,
f
o
u
t
,
s
,
r
f_{in},f_{out},s,r
f
in
,
f
o
u
t
,
s
,
r
得到:
p
a
d
d
i
n
g
=
(
f
o
u
t
−
1
)
×
s
−
f
i
n
+
r
2
padding=\frac{(f_{out}-1)\times s-f_{in}+r}{2}
p
a
dd
in
g
=
2
(
f
o
u
t
−
1
)
×
s
−
f
in
+
r
,这里padding=90.
除了常见的卷积和池化操作,还有空洞卷积、上采样等操作。他们的计算方式如下:

2.4 多路网络感受野
多路网络是指类似resnet、Inception_net这类的某层输入来源于多个不同操作的网络。对于多路网络来说,需要明确的一点概念是
感受野是不具有平移不变性
,这意味这设计不优良的网络有可能:
- 不同分支的感受野中心点会发生改变
- 因为多分支的缘故,同一层feature_map中不同point的感受野区域不同
下面这个例子就是感受野中心发生变化的例子:
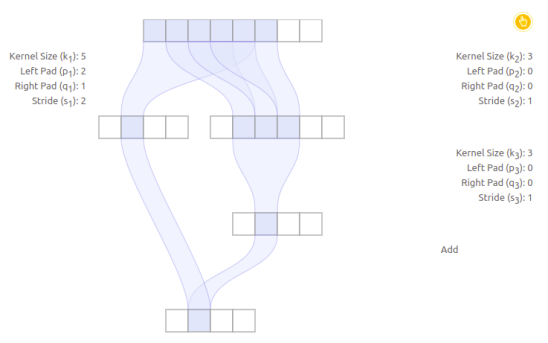
在这个例子中,可以看到输出的第二个节点来自于左右两个分支,其中左边一个分支的感受野是范围是[0,4],感受野中心点是index=2(从0开始进行索引),而右边的感受野分支范围是[1,5],感受野的中心index=3.这种差异会随着层级的增加而严重,对于目标检测、语义分割网络等等网络来说,隐含要求感受野的对齐:任何路径的产生的feature map图,其每个点感受野的中心都是重合的。
幸而这个问题也是可以解决的,在我们设计网络的时候不同路径必须具有相同的步长stride,以及相应的padding策略:
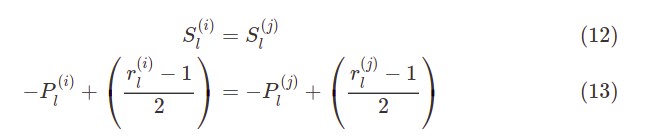
优良设计或者说经过实验认证效果更加的网络,都奇异的满足了这个要求。可见虽然对感受野的研究,时间上落后于各种广经考验的网络之后,但是实验已经将这些网络推给了大众,只待我们去探索背后的原理,发出果然如此的感慨。
3.感受野和性能的关系
3.1感受野和分类网络
对于分类网络来说,无论是二分类还是多分类,最终都是通过感知全局来判断这张图属于哪个类别,考虑到感受野范围越大,输出节点的就更能获得全局的信息,那么感受野应该是越大越好的。
这种直觉也得到了一定的应证:一是实际每年的sota网络,随着网络的逐渐的加深,网络的感受野也对来越深。可以看到resnet_v1_50的感受野就已经基本和输入(480*480)接近,后面的网络感受野范围更加是一路飙升。
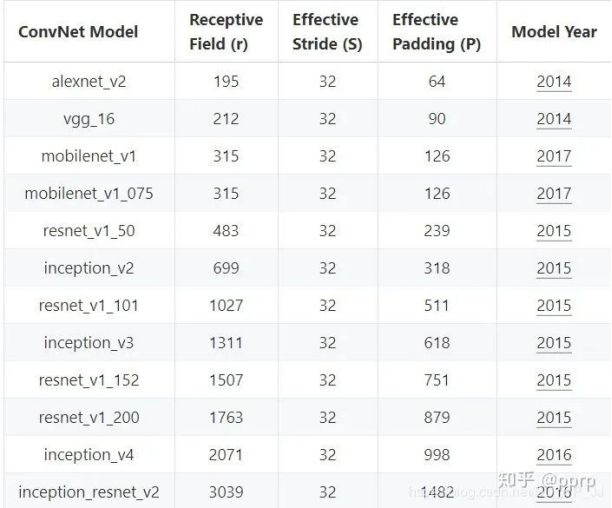
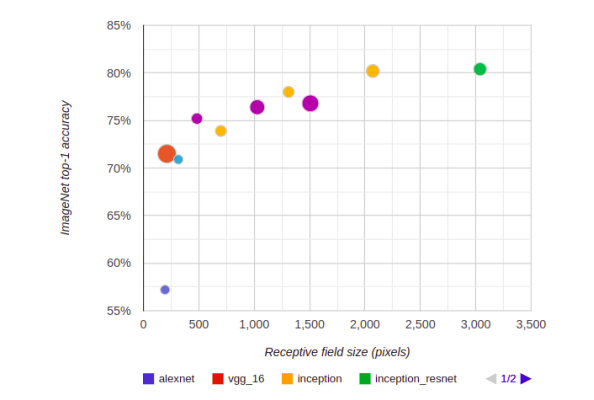
但是实际上,上述分类网络的分类的准确率和感受野大小大体程对数关系。这意味着,无止境的扩大感受野能带来的效益有限,并且感受野的加深,往往意味着计算量的提升,那么我们就应该考虑一下这笔生意是否划算了。
感受野和目标检测网络
目标分类网络分为两种类型,anchor_based和anchor_free的。
目标检测本质上是分类任务+回归任务。
- 分类任务就是对于输出feature_map上的每个点,判断这个点对应的输入图像的感受野属于哪个类别,给出类别的置信度。通过对输出feature_map上的每个点逐一判断得到类别的置信度得分,然后根据这个分数的排序来锁定正例和负例。
- 回归任务就是对于输出feature_map上的每个点,如果存在类别,那么回归目标的坐标框。
对于分类任务来说,和上面提到的分类网络一样,需要具备足够的感受野(至少要包含该物体的大部分特征,当然信息是有冗余的,对于优秀训练的网络来说,少量的特征也足够)来完成分类。如果感受野太大,实际物体所占的像素有限,那么有效信息会被无效信息淹没。
对于回归任务来说,如果是anchor_based方式,基本的设置原则是
Anchor大小<实际感受野<理论感受野
,anchor是我们事先指定的,可以是通用的尺寸或者是类似yolov3通过kmeans的方式得到的anchor。anchor的尺寸应该尽量和目标的尺寸类似,比如人脸,就应该尽量是正方形,文本尽量使长而窄的矩形。如果anchor的尺寸大于感受野,相当于需要去预测感受野区域外的信息,这个难度明显较大。只有当anchor尺寸小于感受野,且关于目标的有效信息都包含在感受野中,那么通过不断优化参数,调整权重,这样的模型效果自然会好一点。
这就要求我们在设计之初,输出层的感受野需要大于目标尺寸,目标尺寸和anchor尺寸相似。
,类似于yolov3采用多层输出feature map来适配不同anchor大小,就真的是设计的美感体现了。
感受野和分割网络
分割网络也是ocr的好朋友呀,分割网络的本质就是对输出层的每个points进行目标分类任务,得到一个全局的mask分类图.
目前主流的分割网络基本都是Unet为基础的,通过不断卷积增加感受野,提取更加抽象图像特征。然后通过不断地上采样(反卷积、或者)增加分辨率并将图像特征恢复到输出层的每个point上。这个过程中,哪个网络可以更加优秀的耦合不同感受野的信息到输出层,哪个网络的性能就会更加优秀。
结语
好久没有写了,学习果然还是要记笔记,不然好多内容都是似懂非懂。最令我头疼的是感受野的计算公式,总是记不住,后来发现也不用强行记忆,记住几个常用的操作的感受野变化数值就好了,其他的需要计算的时候再去翻笔记吧。
初学者还是不要魔改sota的backbone网络了,尤其不能删除s=2的一些层,很可能会导致感受野的减小,导致网络性能变差。
自己在设计网络的时候,需要注意一下感受野的范围够不够。如果设计anchor,则需要考虑一下anchor的尺寸,不要过度集中在一个尺寸,这样不利于模型的泛化性能。
希望大家能够通过这篇笔记对感受野的理解更加深入。感谢参考文献中的作者们,欢迎点赞留言讨论呀~
参考文献