概述:
本文将现有的单变量时间序列分类模型即长短时记忆全卷积网络(LSTM-FCN)和注意力LSTM-FCN(ALSTM-FCN)转换为多变量时间序列分类模型,通过在全卷积块上增加一个 Squeeze-and-Excitation Block来进一步提高分类精度。
下面是文档阅读和程序运行时积累的相关笔记。
1.何为多变量序列 (Multivariate Time Series):
在时间序列数据集中,根据特征的多少可以分为:
-
单变量时间序列(Univariate Time Series):这些数据集每次只观察到一个变量(特征),例如降雨量预测问题中,只通过湿度来预测。上节中的示例是单变量时间序列数据集。
-
多变量时间序列(Multivariate Time Series):这些数据集每次观测两个或多个变量(feature)。例如通过温度、湿度、光照度、风速、风向、气压等特征来预测降雨量。
大多数时间序列分析方法,都关注单变量数据,因为它是最容易理解和使用的。多变量数据通常更难处理,因为它很难建模,而且许多经典方法往往表现不好。
2.何为多步长预测
预测的时间步长是很重要的。同样,根据预测所需的时间步数不同,可以将问题划分为:
- 单步预测(One-step Forecast):预测下一个时间步(t + 1)的值。
- 多步预测(Multi-step Forecast):预测两个或两个以上时间步的值。
3.滑动窗口
时间序列数据可以转化为监督学习问题。给定时间序列数据集的一系列数字,通过重构数据,使其看起来像一个监督学习问题。可以使用前面的时间步(time steps)作为输入变量,下一个时间步作为输出变量。假设有一个时间序列,如下所示:
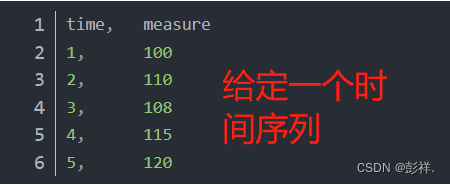
可以利用前一时间点的值来预测下一时间点的值,将这个时间序列数据集重构为一个监督学习问题。重构时间序列数据如下所示:
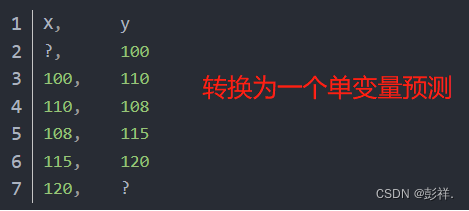
转换的数据集与原始时间序列有如下不同:
- 在监督学习问题中,上一个时间步是输入(X),下一个时间步是输出(y);
- 观测值之间的顺序是保持不变的,并且在使用该数据集训练监督学习模型时也必须继续保持不变;
-
观察第一行,因为没有可以预测序列中第一个值的前一个值,所以将删除这一行,在
训练
时并不使用; -
观察最后一行,因为原时间序列中最后一个值的下一个值不知道,所以也将删除这一行,在
训练
时不使用。
使用之前的时间点的值来预测下一个时间点的值骤称为
滑动窗口方法
(sliding window method),在一些文献中,也称为窗口方法(window method)。在统计学和时间序列分析中,称为滞后或滞后方法(lag method)。包含
时间点的个数
称为窗口宽度(window width)或延迟大小(size of the lag)。滑动窗口是将时间序列数据转换成监督学习问题的基础。对于上例,要注意:
- 一旦以这种方式重构好了时间序列数据集,只要保留行的顺序,就可以应用任何标准的线性和非线性机器学习算法;
- 针对不同的问题,可以尝试增加滑动窗口的宽度,以包括更多时间点的值;
-
滑动窗口方法也可以用于具有多个变量(对于上例,可以理解为有多列不同特征Xi)的时间序列,即多
变量时间序列预测
问题;
4. 多变量滑动窗口
前面提到了滑动窗口和多变量的概念,这里是将两者的结合
假设有多元时间序列数据集,每个时间步有2个观测值:mesure1、mesure2;假设只关心measure2:
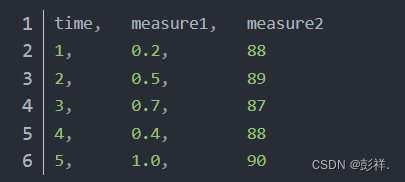
可以将这个时间序列数据集重构为一个
窗口宽度为1
的有监督学习问题,这意味着要使用measure1和measure2的上一个时间点的值,还有measure1的下一个时间点的值,然后预测measure2的下一个时间点的值,因此也就转化成了有
3个输入特征和1个预测输出
的监督学习问题:
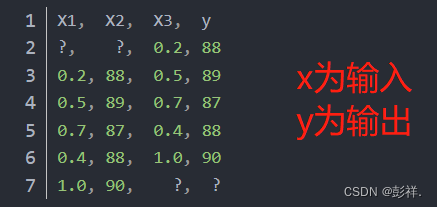
像上面的单变量时间序列示例一样,在训练时,需要删除第一行和最后一行。那如果要预测下一个时间点的measure1和measure2呢?在这种情况下,也可以使用滑动窗口方法。使用上面相同的时间序列数据集,在该问题中,以相同的窗口宽度预测measure1和measure2,如下所示:
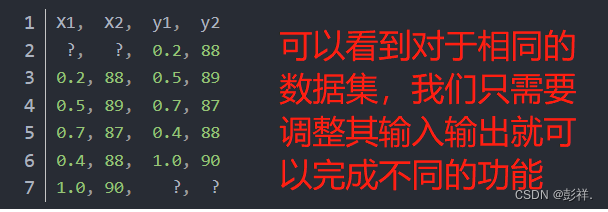
并不是所有的监督学习方法都能在不修改的情况下处理多个输出值的预测,但是一些方法,比如人工神经网络,却没有什么问题。我们可以把预测一个以上的值看作是预测一个序列。在本例中,我们预测了两个不同的输出变量,
但是我们可能希望在一个输出变量之前预测多个时间步长。这称为多步预测
。
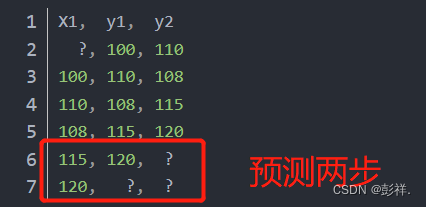
5.具有多个步骤的滑动窗口
即能够完成多步预测
6.动态时间规整DTW
动态时间规整出现的目的也比较单纯,是一种衡量两个
长度不同
的时间序列的相似度的方法。应用也比较广,主要是在模板匹配中,比如说用在孤立词语音识别(识别两段语音是否表示同一个单词),手势识别,数据挖掘和信息检索等中
在大部分的学科中,时间序列是数据的一种常见表示形式。对于时间序列处理来说,一个普遍的任务就是比较两个序列的相似性。比如在语音识别时,我们看两者的发音是否相同,即我们需要对应点,因为语速的原因我们需要将其调整到相同长度去比较
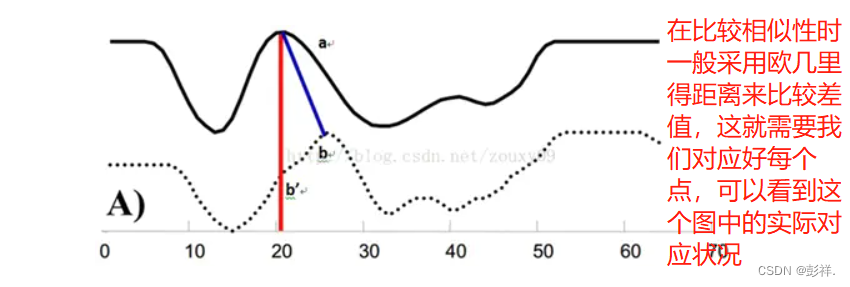
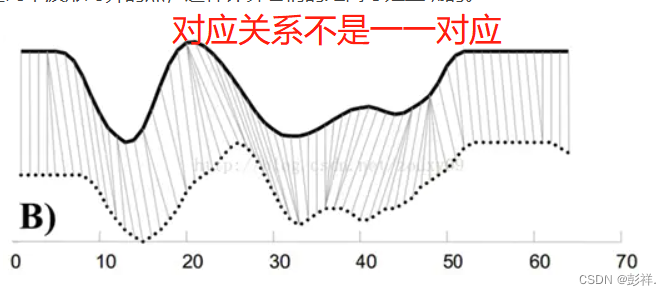
首先,我们依然采用两个序列中每一对“点”之间的距离来计算形似度,即使两个序列中的点的个数可能不一样。不过,因为可以warping规整时间轴,所以,我们并不是在两个序列中依次取一对点来计算距离,而是每个点有可能对应于另一个序列中的多个点。从上面图B可以看到这种一对多的情况。
为了对齐这两个序列,我们需要构造一个n x m的矩阵网格,矩阵元素(i, j)表示qi和cj两个点的距离d(qi, cj)(也就是序列Q的每一个点和C的每一个点之间的相似度,距离越小则相似度越高。这里先不管顺序),一般采用欧式距离,d(qi, cj)= (qi-cj)2(也可以理解为失真度)。每一个矩阵元素(i, j)表示点qi和cj的对齐。DP算法可以归结为寻找一条通过此网格中若干格点的路径,路径通过的格点即为两个序列进行计算的对齐的点。
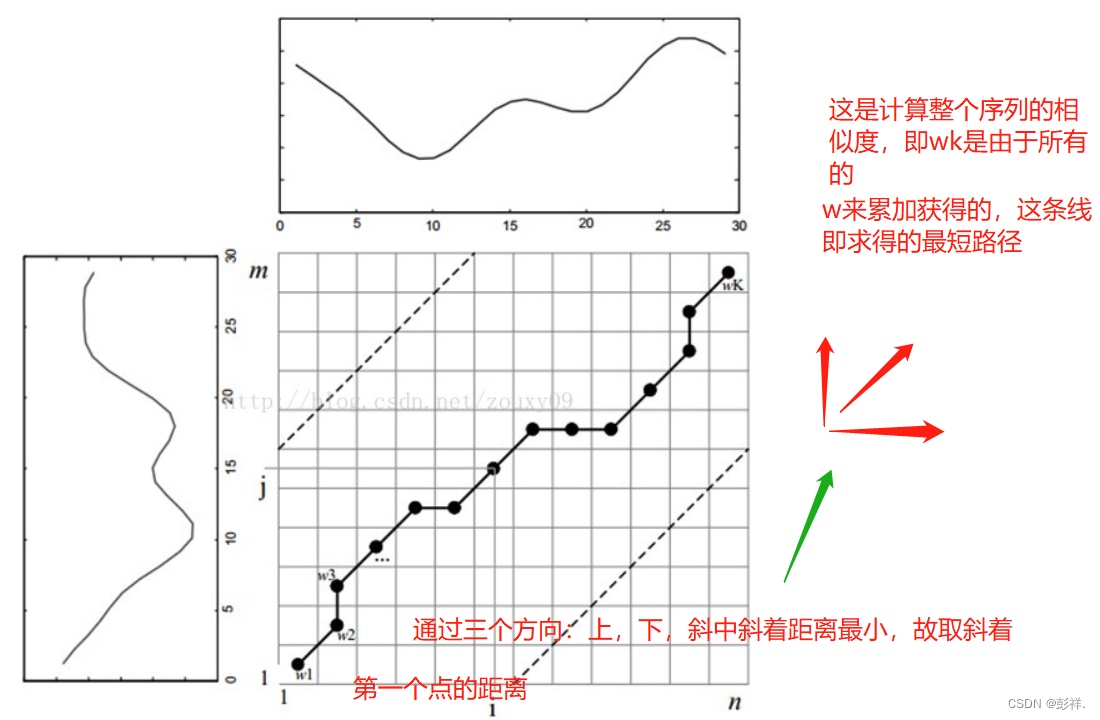
满足条件:
1)边界条件:w1=(1, 1)和wK=(m, n)。任何一种语音的发音快慢都有可能变化,但是其各部分的先后次序不可能改变,因此所选的路径必定是从左下角出发,在右上角结束。
2)连续性:如果wk-1= (a’, b’),那么对于路径的下一个点wk=(a, b)需要满足 (a-a’) <=1和 (b-b’) <=1。也就是不可能跨过某个点去匹配,只能和自己相邻的点对齐。这样可以保证Q和C中的每个坐标都在W中出现。
3)单调性:如果wk-1= (a’, b’),那么对于路径的下一个点wk=(a, b)需要满足0<=(a-a’)和0<= (b-b’)。这限制W上面的点必须是随着时间单调进行的。以保证图B中的虚线不会相交。
-
结合连续性和单调性约束,每一个格点的路径就只有三个方向了。例如如果路径已经通过了格点(i,
j),那么下一个通过的格点只可能是下列三种情况之一:(i+1, j),(i, j+1)或者(i+1, j+1)。
参考:
动态规划参考笔记
7.Squeeze-and-Excitation Networks
SENet的核心思想在于通过网络根据loss去学习特征权重,使得有效的feature map权重大,无效或效果小的feature map权重小的方式训练模型达到更好的结果。
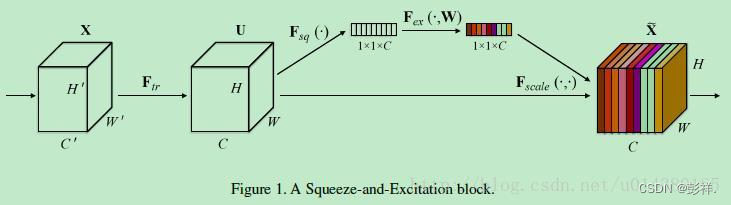
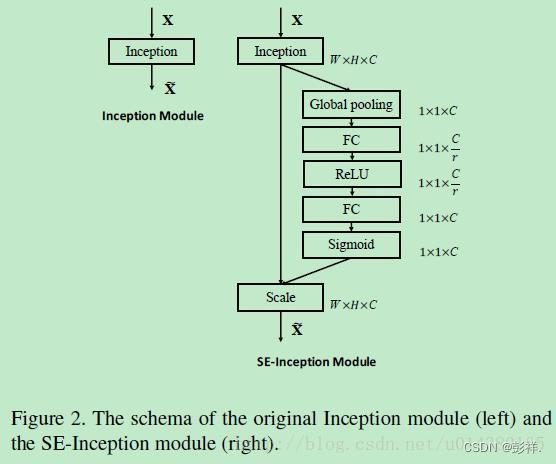
首先Ftr这一步是转换操作(严格讲并不属于SENet,而是属于原网络,可以看后面SENet和Inception及ResNet网络的结合),在文中就是一个标准的卷积操作而已,输入输出的定义如下表示。
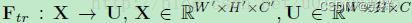
那么这个Ftr的公式就是下面的公式1(卷积操作,vc表示第c个卷积核,xs表示第s个输入)。
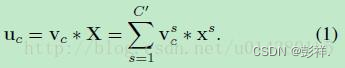
Ftr得到的U就是Figure1中的左边第二个三维矩阵,也叫tensor,或者叫C个大小为H
W的feature map。而uc表示U中第c个二维矩阵,下标c表示channel。
接下来就是Squeeze操作,公式非常简单,就是一个global average pooling:
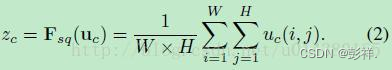
因此公式2就将HWC的输入转换成11C的输出,对应Figure1中的Fsq操作。为什么会有这一步呢?这一步的结果相当于表明该层C个feature map的数值分布情况,或者叫全局信息。
再接下来就是Excitation操作,如公式3。直接看最后一个等号,前面squeeze得到的结果是z,
这里先用W1乘以z,就是一个全连接层操作,W1的维度是C/r * C,这个r是一个缩放参数,在文中取的是16,这个参数的目的是为了减少channel个数从而降低计算量
。又因为z的维度是11C,所以W1z的结果就是11C/r;然后再经过一个ReLU层,输出的维度不变;然后再和W2相乘,和W2相乘也是一个全连接层的过程,W2的维度是C
C/r,因此输出的维度就是11C;最后再经过sigmoid函数,得到s。
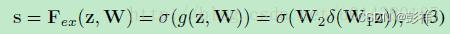
也就是说最后得到的这个s的维度是11C,C表示channel数目。
这个s其实是本文的核心,它是用来刻画tensor U中C个feature map的权重。而且这个权重是通过前面这些全连接层和非线性层学习得到的
,因此可以end-to-end训练。这两个全连接层的作用就是融合各通道的feature map信息,因为前面的squeeze都是在某个channel的feature map里面操作。
在得到s之后,就可以对原来的tensor U操作了,就是下面的公式4。也很简单,就是channel-wise multiplication,什么意思呢?uc是一个二维矩阵,sc是一个数,也就是权重,因此相当于把uc矩阵中的每个值都乘以sc。对应Figure1中的Fscale。
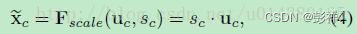
了解完上面的公式,就可以看看在实际网络中怎么添加SE block。Figure2是在Inception中加入SE block的情况,这里的Inception部分就对应Figure1中的Ftr操作。