快看 esmm 模型理论与实践
文章源码下载地址:
点我下载
http://inf.zhihang.info/resources/pay/7692.html
近两年,
多目标学习 (Multi-Task Learning,MTL)
甚嚣尘上。除了因为国内外大量互联网公司业务与算法优化步入深水区,需要更复杂的网络来应对复杂的业务之外,很多MTL 深度学习模型结合业务场景进行不断突破的设计思想让人惊艳不已,更是不由得让人敬佩算法工程师( 我的同行们~ ) 的创新能力,而算法 的 魅力 也正在此处。在众多的MTL模型中, 阿里巴巴在2018年发表的论文《Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate》提出的ESMM网络绝对是具有极大借鉴意义的。
通常理解,MTL任务可以分为两种,
串行与并行
。多个任务之间有比较强关联的, 例如点击率与转化率,这一种通常我们可以使用
esmm这种串行的任务进行关系递进性与相关性建模
。而对于多个任务之间相对比较独立的,例如点击率与用户是否给出评论的评论率,通常可以选择
mmoe这种并行的任务进行相关性与冲突性的建模
。本文主要围绕esmm网络模型展开阐述。

一般来说,我们使用机器学习模型构建推荐系统(包括推荐广告及自然量) 给用户推荐商品,会考虑很多的
排序因子
。结合用户行为漏斗来看,用户进入某场景会经历:
看到商品(曝光 view)-> 点击 (click) -> 购买 (conversion) -> 好评 (good_comment )
直到后面更深层次的次日留存,一周留存等。
我们知道,
点击率
( CTR , 表示view->click, 为view/click )代表用户对接触到某个item并表现出对它的初步的兴趣,想点进去看看更详细的内容,这反映的是
用户参与度指标
。 而
转化率
(CVR,表示click-> conversions,为conversion/click)则表示用户对推荐的内容很满意,并且愿意为之付出更重的行为,好比是收藏转发或则付费购买,这反映的是
用户满意度指标
。
从上面我们可以知道,转化率与点击率有一定关系,但是他们之间又没有绝对的关系。但是对这个问题,很多人有一个先入为主的认知即:
点击率高的item转化率也高,这是不正确的
。我们可以想象一个场景,假如百度的feed中,一个推荐的条目展示头图很丑或标题相对不具有吸引力,它被某个用户点击的概率很低,但此条目内容本身质量很高且完美符合该用户偏好,如果用户点进去,那么它被用户转化的概率就极高。这是一个被完全低估了的item,其内在往往远高于外在。
书接上文,通常如果我们在排序的时候,想要提高这些真正优秀的item的排名,就需要考虑点击率CTR, CVR(click-> conversions)等因素, 甚至在有些场景会更进一步的考虑好评率、次留率、周留率等更多因素。
因此,我们的排序策略公式的基础格式可以长这样:
` Rank_Score = CTR CVR * other_Rank_info `
我们根据公式最后得到的 Rank_Score 进行排序即可。
注意: 我们想要在推荐排序的时候考虑什么因素,就把该因素建模成一个排序因子融入到排序公式里就可以了。
当然,我们可以使用多个模型来分别建模CTR、CVR等,每个目标打出一个分数。虽然这种方式具有很强的灵活性,但是也有很多的局限性。例如离线算法优化与迭代上的人力维护成本、线上多模型预估路径太长带来的时间成本、数据不能通用以及预估场景带来的偏差等诸多问题。
此时,就需要本文所要介绍的ESMM模型出场了。

(1) esmm 模型基础理解
从论文中可以看出,esmm 网络的最初提出,是为了解决电商购物场景中给用户推荐商品时 CVR 模型预估估不准的问题。当然我们没有说绝对的什么模型就能估计的准确,但是算法的逐渐优化,不就是让模型越来越接近事情的本质的过程吗。
(1.1) CVR相对CTR任务的不同
不同于CTR预估,CVR预估面临的问题要更加复杂。这其中主要的包括:
(1)
Data Sparsity (DS) 数据稀疏
。cvr训练样本不足,转化的样本远远少于点击样本,导致模型的embeding训练不充分。(通常CTR为1~3%左右,而CVR则随不同场景差异非常大,购物下载场景一般也为1~10%左右) 。
(2)
Sample Selection Bias (SSB) 样本选择偏差
。我们以前很多时候训练cvr模型,用点击转化的作为正样本,点击未转化的作为负样本,训练好模型去线上预估打分参与排序公式的计算,胜出的item才能获得新一轮的曝光机会。但这中间涉及到一个重要问题: 我们使用的是点击转化数据来作为样本,而在参与排序的时候,那个时候更在曝光之前,并且需要打分的item和要用的特征数量级甚至可以达到全体item候选集。
这就违背了我们使用机器学习模型的一个根本原则:
IID原则
。 我们训练模型的数据和预估的数据不是独立同分布的,训练集是预估集的一个子集,并且是非常少的一个子集。
并且中间涉及着一个问题就是:原始的CVR表示用户点击了某个item,他被转化的概率,而对于那些没有被点击的item,假设他们被用户点击了,它们是否会被转化? 如果直接使用0作为它们的label,会很大程度上
误导CVR模型的学习
。

曾经作者在国内某互联网头部大厂工作的时候,就曾遇到这个问题,当时这个问题
换了个马甲就把我坑惨了,整整花了2个星期才解决!!!
。记得当时,这个问题的表现形式是:离线实验的时候auc/gauc/logloss均是正常,但是线上的时候预估打分均为0。经过拆分打印网络各个部分输出,最终发现是离线训练的模型里,保存了30多G的embeding文件,但是到线上的时候,依然有大量的sparse Id 找不到,embeding lookup不到。深究其根本原因,不就是因为样本选择偏差导致的离线模型没见过线上模型的大量特征吗。
可见样本选择偏差不光会导致预估估计偏差的问题,甚至也会以由于没见过特征而导致打分完全不可用的形式出现。从这个问题,我们也可以收获到一个经验:当我们理论上论证到一个问题的时候,可以更进一步的想想这个理论问题在实践中会有什么样的表现形式出现。正着推很容易的问题,逆反过来就要了我的小命了。遇到理论问题在实践上多思考一步,不然就会像我一叶障目不见泰山,换了马甲就不认识了,此处只想大书三个字,
坑坑坑!!!
(3)
反馈延迟
。 这个问题算是cvr和ctr相比最众所周知的一个不同了。
一般点击反馈到曝光,也就1s以内,而转化到点击的反馈,随场景不同甚至可以达到1~10天不等。
在淘宝京东等购物场景还好,转化数据是闭环内部可达的,用户购买数据是内部可以拿到的; 而在像是小米华为的应用商店里App的激活率预估,激活数据则依赖于第三方厂家或广告主的回传,这种数据延迟都非常严重,2~5天是常态,这就给我们预估转化率带来了很大的困难。
对于反馈延迟这个问题,问题是客观存在的,并且并不能从根本上让他不产生,但是缓解的方法有很多。其中就包括:
(1) 设计模型对反馈延迟进行建模。
(2) 构建滚动式数据pipline回跑全量回传数据模型 + 2天延迟并且去掉依然未回传数据训练的模型。
(3) 对CVR进行分时间段加权校准。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oFhThtRX-1672976021430)(https://img.soogif.com/m2l9mcyLerWsBAT3uAinFGEeqxof5aOs.gif?scope=mdnice)]
(1.2) esmm 如何解决问题?
书接上文,针对上文提到三点困难中的前两点,esmm从模型从模型结构设计与损失函数设计上就分别做出了很优秀的解答。
首先是数据稀疏,既然你因为稀疏数据导致embeding训练不好,那我就让你和数据不那么稀疏的模型共享embeing查找表, 这个从模型结构的设计来解决。
而对于样本选择偏差,既然常规训练点击转化率cvr的方式有偏差,那就引入曝光下点击且转化率来解决,这个从模型的损失函数loss设计来解决 。在论文中,曝光下点击且转化率也叫CTCVR。
抱歉,这里我自己造了一个词叫曝光下点击且转化率 , 对应的CTR就是曝光下点击CTR。因为CTR本就是曝光到点击的概率,所以曝光CTR就是CTR。但是原始的CVR 是点击到转化的概率,而曝光下点击且转化率 是曝光到点击且转化的概率,这就显示出其中的区别了。 更准确的说,CVR预估模型的本质,不是预测” item被点击,然后被转化”的概率(CTCVR),而是“假设item已经被点击,那么它被转化”的概率(CVR)。
基于此,我们来看下论文里对点击率(CTR)、转化率(CVR)、点击然后转化(CTCVR)三者关联的建模:

其中: z,y 分别表示 conversion 和 click 。
我们可以看到: pCVR和pCTCVR这里均是条件概率。 不同的是: pCVR 是曝光且点击的条件下,转化的概率,注意这里点击是已经确定的,作为条件概率的条件存在; 而pCTCVR 是 曝光的情况下,点击并且转化的条件概率, 预估的是点击和转化同时发生的概率。注意区别两者的不同。
注意到,在全部样本空间中,CTR对应的label为click,而CTCVR对应的label为click & conversion,他们均是在已知曝光的情况下进行预估的,分别是曝光下点击率和曝光下点击且转化率,所以 这两个任务均是可以使用全部样本的,因此也就不在存在样本选择偏差的问题了。
我们应该可以看到 , esmm 的整体逻辑结构是基于 “乘法” 的关系设计的: pCTCVR=pCVR * pCTR 。同样我们是不是也可以从公司反推出 pCVR = pCTCVR / pCTR 这个结果呢 ?例如分别独自的去训练 CTCVR任务模型和CTR任务模型,然后两者相除得到pCVR的分数? 当然这样做也可以,但它就有个明显的缺点: 真实场景预测出来的pCTR、pCTCVR值都非常小,“除”的方式容易造成数值上的不稳定,而且有可能是的pCVR的值大于1,这是明显不符合实际情况的。
(2) esmm 模型详解
上文我们已经说明了esmm从理论上解决了CVR模型存在的数据稀疏和样本选择偏差的问题,下面我们看下该网络的结构:
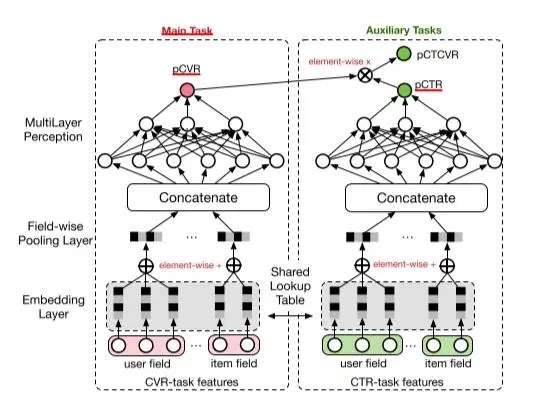
从上面 esmm 模型的结构图中,我们可以看到,esmm 模型以pCVR为主任务,并且引入了CTR和CTCVR两个辅助任务。
CVR网络和CTR网络
,两个子网络可以具有相同的网络结构,当然也可以不同。甚至两者用的特征可以有部分相同,也可以有部分不同。相同的那部分可以共享embeding起到
知识迁移
的作用。
其中,pCVR 和 pCTR
共享embeding查找表
, 这样 pCVR 任务就可以共享pCTR任务的样本数据来训练embeding ,可以解决
数据稀疏
的问题。如果两个模型用的特征有部分不同的话,每个子网络依然输入全部,只是取值的时候各取所需的独有的字段特征即可。不同任务即有公共共享的特征,也有各自任务所专享的独有的特征。
一种不错的实践
是将用户行为序列(用户历史以及实时行为序列)进行共享,对pCTR和pCVR任务均是有帮助的。当然我们也可以灵活调整自己各个子任务所需要的特征数据与结构。
在线上进行打分的时候,我们可以通过模型同时得到pCTR、pCVR这两个子网络的输出以及pCTCVR。

而训练esmm模型,我们输入的样本数据除了训练pCTR和pCTCVR任务的特征之外,
每行样本是带有2列标签的,分别是 click与conversion
。
这里我们选择曝光了有点击的作为
pCTR任务
的正样本,曝光了没点击的作为PCTR任务的负样本; 而选择曝光了有点击的并且有转化的作为PCTCVR任务的正样本,其余的作为
pCTCVR任务
的负样本。
注意:这里对于pCTCVR任务的
样本构造
在多啰嗦两句。
(1) 没有点击的,自然没有转化,在实际业务数据中会发现部分没有点击而有转化的数据,可以直接丢弃( 这里包括click 为 0, 而 conversion为0和1,conversion=1直接丢弃,conversion=0为负样本)。(2) 有点击的,如果没有转化的样本,自然是负样本(这里包括click 为 0, 而 conversion为0 为负样本)。(3) 而有点击并且有转化的,为正样本(这里包括click 为 1, 而 conversion为1 为正样本)。
因此两列 label 四个去值中,对于pCTCVR任务来说,一种情况丢弃,2种情况为负,
唯有一种情况为为正
。
从上图中也可以看出: pCVR只是一个中间变量,没有显式的监督标签,所以我们也称是
隐式训练CVR
。而 pCTR 任务和 pCTCVR 任务则是esmm 在整个样本空间要估计的。
所以 esmm 的 loss 函数包括两部分:
CTR损失函数和CTCVR损失
,但不包括CVR任务的损失函数。因此 ,整个训练任务的损失函数为:
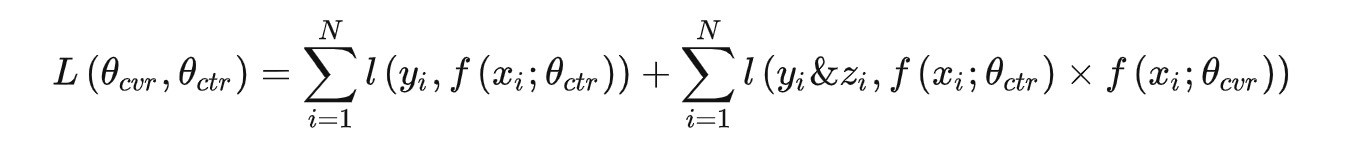
其中, θctr和θcvr分别是CTR网络和CVR网络的参数,L(∗)是交叉熵损失函数。在下文,会介绍一种修改该损失以求得转化率和点击率相互靠拢,效果双双提升的自定义损失函数的方法。
(3) esmm 模型实践与思考
记得以前看抖音上一段字节跳动张一鸣的采访,他曾经说:
我们对一个事物的认知,才是我们真正的竞争力
。对事物认知越深刻,你就越有竞争力。
书接上文,esmm 模型用模型结构设计和损失函数设计解决了实际业务中模型优化的痛点问题,这对于我们在运用机器学习模型到自身的业务的过程中,是不是也可以受到很多启发呢?
首先我们需要对自身业务进行深入思考,很重要的一点就是:
我们训练模型的目的主要是为了学习的什么,什么是模型中比较重要的点,各个部分起的作用是什么,现有模型中间还遗留有什么问题,我们突出什么点可以带来什么收益,我们可以选择什么方式进行设计(比如模型结构和损失函数)可以达到我们突出这个特性的目的?
只有真正的的结合业务深入思考了,才能逐渐驱动我们去不断挖掘埋藏在其中的“金子”,最终创新出令人惊艳的设计。
我们可以发觉一点就是:很多优秀的模型设计都是在为了更好的学习用户的某一特性,而引入一个新的辅助模块,构建一个辅助任务,并添加辅助损失到最后的任务损失中以突出该模块的训练。无论是当前介绍的 esmm还是阿里巴巴的另一篇讲 dien 的论文,又或则是 将EGES的图用于冷启动任务的模型设计均是如此。
当一个模块没办法在原始结构中的loss回传过程中得到很好训练的时候,我们是否可以构建新的辅助损失专门针对当前模块进行训练呢?
我们在
企业级机器学习 Pipline – 排序模型
这篇文章里曾经说过数据和模型是“一体两面“的,这里要再次强调一下:首先就是样本设计与网络结构需要相契合,随着思考的深入,我们需要不断的去调整网络结构以及灵活构建输入模型的数据,我们需要知道什么形式的特征可以用什么方式去建模学习以及哪种方式可以得到好的效果。如果在某个场景没有足够的先验知识,那就开始疯狂实验吧~

俗话说的好啊~ “工欲善其事,必先利其器“,写代码调模型也是如此。随心所欲的调整模型,这不光要求我们对DNN模型内部各个部分的数据形式以及如何流动这些场景是非常清晰的,更要求我们对一些模型构建工具,例如:
tensorflow
或
pytorch
以及如何进行自定义损失要真的进行深刻的理解与应用,最终达到如臂使指的
“无矩“
的大成境界。代码是最能表达一个程序员思想的东西,有问题多看源码哈,会受益匪浅的~
闲话就说到这里吧 ~
因为esmm模型其实是在平滑CTR与CVR模型之间的很多差异,进行知识迁移与优劣势互补。在上文提到的以前的文章
企业级机器学习 Pipline – 排序模型
中效果评估模块,我们也曾经提到要监控线上模型打出的CTR和CVR打分等情况。 在我们的实际业务中,我们可以仔细分析下我们要推荐的item,根据线上用户反馈数据圈出来一些分类。例如:在item中,ctr与cvr均很高的真正优质item, ctr高而cvr低的华而不实的item,ctr低而cvr高的有外表平庸内涵丰富的item,以及ctr与cvr双低的劣质item。
我们可以仔细分析下,针对各个分类的item,设计符合各自特点的模型,在模型优化迭代已经进入深水区的时候,应该是一个不错的优化点。
在上文我们已经说过,线上esmm我们可以同时得到pCTR、pCVR两个子网络的输出以及pCTCVR的值,当然pCVR也可以取pCTCVR除以pCTR得到,但是因为数据过小出发产生波动太过于剧烈。记得以前有一篇讲蘑菇街esm实践的文章中,说他们有设计了一种
CVR的值域控制
的公式,感兴趣的可以去详细了解一下。
如果直接用pCTCVR替换CTR打分,会普遍遇到 CVR 效果有提升而CTR效果下降的问题。其实不光ctr跌和cvr涨,ctr和cvr 各自均有上升和下跌两种趋势,组合起来就有四种情况。这种上线之后,一个任务变好一个任务变差的情况,就涉及到多目标任务中多个目标的融合情况,俗称为多目标学习中的
“跷跷板“
问题。
对于
多任务融合
问题,我们可以在损失函数中
设定pCTR任务和pCVR任务的Loss所占的比重
,例如:
model.compile(
optimizer=opt,
loss=['binary_crossentropy', 'binary_crossentropy'],
loss_weights=[1.0, 1.0],
metrics=[
tf.keras.metrics.AUC(),
tf.keras.metrics.BinaryAccuracy()
)
这种方式是将该比重比例固定的写法,这个值可能需要根据各自的业务数据进行适当的调整,选择出最合适的值。
Google2016年在youtube 视频推荐场景提出的 “Deep Neural Network for YouTube Recommendation” 论文中,有提出一种
基于视频观看时长进行Loss 加权
的损失函数也给我们带来了很大的启发,那我们是否可以根据某个item的历史某一段时间内的CTR和CVR对pCTR以及pCTCVR任务进行加权呢? 当然这里只是提出一种可能,可以选择别的合适的指标个性化的对两个任务进行Loss调整。
当然,我们也可以使用一个
可学习的权重参数
,让模型自己去动态的学习如何适配二者任务的权重。这样也是有利有弊吧,利就是过度平滑,没有自己设定值的那么生硬,而弊就是过于灵活,当我们想限制性调整的时候就需要换一种方式了。
另一种方式就是在两个任务之间,添加
gate 门网络
,不从损失函数入手,而从底层embedign之后的某些layer入手,这样就和
MMOE网络
有互通的地方了,感兴趣的可以自己下去尝试哈。
最值得称道
的是另一种方式:假设我们上线了esmm模型之后,点击下降而转化上升,那我们是不是可以
构建一条曝光到转化的通路呢,在损失函数中加上一项: Loss(y, F(xi,Pcvr)),强制 要求模型的转化和点击相互靠拢,以求达到两个任务均有正向收益的双赢局面
。
我不知道这些点我说清楚了没有,感兴趣的可以在公众号留言加群交流哦~

(4)代码时光
开篇先吼一嗓子:
talk is cheap , show me the code !!!
哎, 终于再次写到代码时光了,写一篇小作文比上班一整天还累啊!!!
对于esmm模型,网上找了一圈,均是基于tensorflow 的estimator接口和别的一些方法实现的,而作者非常推崇的一种做法是使用 tensorflow 的featureColumn接口来处理特征,而使用 tf keras 的中阶API来进行网络结构的定制,这样
兼顾了特征处理的便利性与网络结构灵活的可定制性
。
但是这种组合的代码作者搜遍的网络居然没有找到适合自己的,于是狠下心肝了两天,自己手写了一套算法代码,在这里分享给大家,有问题欢迎留言讨论 ~
# 欢迎关注微信公众号: 算法全栈之路
# -*- coding: utf-8 -*-
import numpy as np
import os
import argparse
import tensorflow as tf
import log_util
import params_conf
from date_helper import DateHelper
import data_consumer
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
def init_args():
parser = argparse.ArgumentParser(description='dnn_demo')
parser.add_argument("--mode", default="train")
parser.add_argument("--train_data_dir")
parser.add_argument("--model_output_dir")
parser.add_argument("--cur_date")
parser.add_argument("--log", default="../log/tensorboard")
parser.add_argument('--use_gpu', default=False, type=bool)
args = parser.parse_args()
return args
def get_feature_column_map():
key_hash_size_map = {
"adid": 10000,
"site_id": 10000,
"site_domain": 10000,
"site_category": 10000,
"app_id": 10000,
"app_domain": 10000,
"app_category": 1000,
"device_id": 1000,
"device_ip": 10000,
"device_type": 10,
"device_conn_type": 10,
}
feature_column_map = dict()
for key, value in key_hash_size_map.items():
feature_column_map.update({key: tf.feature_column.categorical_column_with_hash_bucket(
key, hash_bucket_size=value, dtype=tf.string)})
return feature_column_map
def build_embeding():
feature_map = get_feature_column_map()
feature_inputs_list = []
def get_field_emb(categorical_col_key, emb_size=16, input_shape=(1,)):
# print(categorical_col_key)
embed_col = tf.feature_column.embedding_column(feature_map[categorical_col_key], emb_size)
# 层名字不可以相同,不然会报错
dense_feature_layer = tf.keras.layers.DenseFeatures(embed_col, name=categorical_col_key + "_emb2dense")
feature_layer_inputs = dict()
# input和DenseFeatures必须要用dict来存和联合使用,深坑啊!!
feature_layer_inputs[categorical_col_key] = tf.keras.Input(shape=(1,), dtype=tf.dtypes.string,
name=categorical_col_key)
# 保存供 model input 使用.
feature_inputs_list.append(feature_layer_inputs[categorical_col_key])
return dense_feature_layer(feature_layer_inputs)
embeding_map = {}
for key, value in feature_map.items():
# print("key:" + key)
embeding_map.update({key: get_field_emb(key)})
return embeding_map, feature_inputs_list
def build_dnn_net(net, params_conf, name="ctr"):
# 可以在下面接入残差网络
for i, dnn_hidden_size in enumerate(params_conf.DNN_HIDDEN_SIZES): # DNN_HIDDEN_SIZES = [512, 128, 64]
net = tf.keras.layers.Dense(dnn_hidden_size, activation="relu", name="overall_dense_%s_%s" % (i, name))(net)
return net
def build_model(emb_map, inputs_list):
# 需要特殊处理和交叉的特征,以及需要短接残差的特征,可以单独拿出来
define_list = []
adid_emb = emb_map["adid"]
device_id_emd = emb_map["device_id"]
ad_x_device = tf.multiply(adid_emb, device_id_emd)
define_list.append(ad_x_device)
# 直接可以拼接的特征
common_list = []
for key, value in emb_map.items():
common_list.append(value)
# embeding contact
net = tf.keras.layers.concatenate(define_list + common_list)
# 构建 ctr 和 cvr 各自的 网络
ctr_output = build_dnn_net(net, params_conf, "ctr")
cvr_output = build_dnn_net(net, params_conf, "cvr")
ctr_pred = tf.keras.layers.Dense(1, activation="sigmoid", name="ctr_sigmoid")(ctr_output)
cvr_pred = tf.keras.layers.Dense(1, activation="sigmoid", name="cvr_sigmoid")(cvr_output)
# CTCVR = CTR * CVR
ctcvr_pred = tf.keras.layers.Multiply(name="ctcvr_pred")([ctr_pred, cvr_pred])
# 注意: 这里定义了网络结构的骨架,设定了网络的输入输出,而在model.fit那里输入的参数个数,必须和这里的输入输出相对应,否则会报维度对不上的错误。
# 因为esmm 的模型结构限定了每条样本有两个标签,对应了这里的[ctr_pred, ctcvr_pred] 两个输出,可以求的损失。
model = tf.keras.models.Model(inputs=inputs_list, outputs=[ctr_pred, ctcvr_pred])
return model, ctr_pred, ctcvr_pred
def train():
output_root_dir = "{}/{}/{}".format(params_conf.BASE_DIR, args.model_output_dir, args.cur_date)
os.mkdir(output_root_dir)
model_full_output_dir = os.path.join(output_root_dir, "model_savedmodel")
# print info log
log_util.info("model_output_dir: %s" % model_full_output_dir)
# 重置keras的状态
tf.keras.backend.clear_session()
log_util.info("start train...")
train_date_list = DateHelper.get_date_range(DateHelper.get_date(-1, args.cur_date),
DateHelper.get_date(0, args.cur_date))
train_date_list.reverse()
print("train_date_list:" + ",".join(train_date_list))
# load data from tf.data,兼容csv 和 tf_record
train_set, test_set = data_consumer.get_dataset(args.train_data_dir, train_date_list,
get_feature_column_map().values())
# train_x, train_y = train_set
log_util.info("get train data finish ...")
emb_map, feature_inputs_list = build_embeding()
log_util.info("build embeding finish...")
# 构建模型
model, ctr_pred, ctcvr_pred = build_model(emb_map, feature_inputs_list)
log_util.info("build model finish...")
def my_sparse_categorical_crossentropy(y_true, y_pred):
return tf.keras.sparse_categorical_crossentropy(y_true, y_pred, from_logits=True)
opt = tf.keras.optimizers.Adam(params_conf.LEARNING_RATE)
# 注意这里设定了2个损失分别对应[ctr_pred, ctcvr_pred] 这两个任务
# loss_weights=[1.0, 1.0]这种方式可以固定的调整2个任务的loss权重。
model.compile(
optimizer=opt,
loss=['binary_crossentropy', 'binary_crossentropy'],
loss_weights=[1.0, 1.0],
metrics=[
tf.keras.metrics.AUC(),
tf.keras.metrics.BinaryAccuracy(),
tf.keras.metrics.Recall(),
tf.keras.metrics.Precision()]
)
model.summary()
# tf.keras.utils.plot_model(model, 'multi_input_and_output_model.png', show_shapes=True, dpi=150)
print("start training")
# 需要设置profile_batch=0,tensorboard页面才会一直保持更新
tensorboard_callback = tf.keras.callbacks.TensorBoard(
log_dir=args.log,
histogram_freq=1,
write_graph=True,
update_freq=params_conf.BATCH_SIZE * 200,
embeddings_freq=1,
profile_batch=0)
# 定义衰减式学习率
class LearningRateExponentialDecay:
def __init__(self, initial_learning_rate, decay_epochs, decay_rate):
self.initial_learning_rate = initial_learning_rate
self.decay_epochs = decay_epochs
self.decay_rate = decay_rate
def __call__(self, epoch):
dtype = type(self.initial_learning_rate)
decay_epochs = np.array(self.decay_epochs).astype(dtype)
decay_rate = np.array(self.decay_rate).astype(dtype)
epoch = np.array(epoch).astype(dtype)
p = epoch / decay_epochs
lr = self.initial_learning_rate * np.power(decay_rate, p)
return lr
lr_schedule = LearningRateExponentialDecay(
params_conf.INIT_LR, params_conf.LR_DECAY_EPOCHS, params_conf.LR_DECAY_RATE)
# 该回调函数是学习率调度器
lr_schedule_callback = tf.keras.callbacks.LearningRateScheduler(lr_schedule, verbose=1)
# 训练
# 注意这里的train_set 可以使用for循环迭代,tf 2.0默认支持eager模式
# 这里的train_set 包含两部分,第一部分是feature,第二部分是label ( click, click & conversion)
# 注意这里是 feature,(click, click & conversion),第二项是tuple,不能是数组或列表[],不然报数据维度不对,坑死爹了。
model.fit(
train_set,
# train_set["labels"],
# validation_data=test_set,
epochs=params_conf.NUM_EPOCHS, # NUM_EPOCHS = 10
steps_per_epoch=params_conf.STEPS_PER_EPHCH,
# validation_steps=params_conf.VALIDATION_STEPS,
#
# callbacks=[tensorboard_callback, lr_schedule_callback]
)
# 模型保存
tf.keras.models.save_model(model, model_full_output_dir)
# tf.saved_model.save(model, model_full_output_dir)
print("save saved_model success")
if __name__ == "__main__":
print(tf.__version__)
tf.compat.v1.disable_eager_execution()
# run tensorboard:
# tensorboard --port=8008 --host=localhost --logdir=../log
args = init_args()
if args.mode == "train":
train()
到这里,快看esmm模型理论与实践就写完成了,欢迎留言交流 ~
码字不易,觉得有收获就点赞、分享、再看三连吧~
算法全栈之路