代码主要分四个部分
一
- 数据读取与处理
- 网络代码
- loss计算
-
预测解码
以下主要对上面4个部分的关键代码进行详解,同时记录自己当前的一些疑问
1. 数据读取与处理
后面再补
2. 网络代码
后面再补
3. loss计算
本文代码主要简介pytorch版本的yolov3,和源码及ultralytics版本都有所出入,主要去思考其中的细节。
本节主要从三个函数进行讲解-
loss主函数 forward:loss计算过程
先贴一张loss公式图
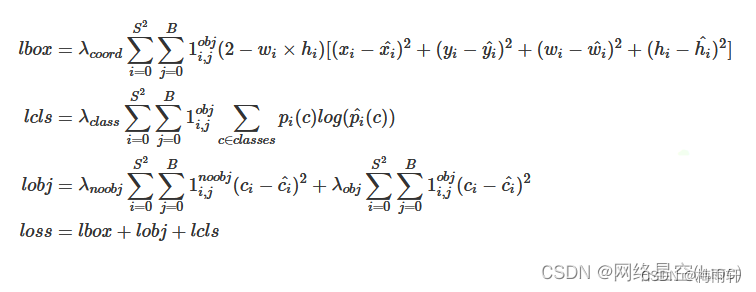
yolov3的loss分为三个组要部分:定位损失,置信度损失,类别损失。
由图中可知边框损失使用mse loss, (2-w * h) 是为了平衡大框和小框带来的影响,yolov1使用宽高的开方进行平衡,类别损失使用二分类交叉熵损失,解除了类别之间的互斥性。置信度仍然使用mse loss计算
# l代表特征尺度的索引 -
loss主函数 forward:loss计算过程
bs = input.size(0)
in_h = input.size(2)
in_w = input.size(3)
#计算当前特征层的步长
stride_h = self.input_shape[0] / in_h
stride_w = self.input_shape[1] / in_w
#将anchor缩放到当前特征图尺寸
scales_anchors = [(a_w / stride_w, a_h / stride_h) for a_w, a_h in self.anchors]
prediction = input.view(bs,len(self.anchors_mask[l]), self.bbox_attrs, in_h, in_w).premute(0,1,3,4,2).contiguous()
#获取预测结果,其中x,y,conf,class_conf需要归一化
x = torch.sigmoid(prediction[...,0])
y = torch.sigmoid(prediction[...,1])
w = prediction[...,2]
h = prediction[...,3]
conf = torch.sigmoid(prediction[...,4])
pred_cls = torch.sigmoid(prediction[...,5:])
#样本匹配获取mask
y_true, noobj_mask, box_loss_scale = self.get_target(l, targets, scales_anchors, in_h, in_w)
#yolov3中存在忽略样本,忽略样本不计算loss,获得其相应mask
noobj_mask,pred_boxes = self.get_ignore(l, x, y, h, w, targets, scales_anchors, in_h, in_w, noobj_mask)
if self.cuda:
y_true = y_true.type_as(x)
noobj_mask = noobj_mask.type_as(x)
box_loss_scale = box_loss_scale.type_as(x)
#yolov3解决大小样本对loss贡献不一致问题的方式,不理解为什么用2- 不用1-
box_loss_scale = 2 - box_loss_scale
loss = 0
obj_mask = y_true[...,4] ==1
n = torch.sum(obj_mask)
if n != 0:
#pytorch版本中加入了giou进行样本匹配,同时在部分代码中使用anchor和ground truth的
高宽比进行正负样本选择,应该是借鉴的yolov5.
if self.giou:
giou = self.box_giou(pred_boxes, y_true[...,:4]).type_as(x)
loss_loc = torch.mean(1-giou)[obj_mask]
else:
#代码实现中x,y的loss使用的交叉熵进行计算
loss_x = torch.mean(self.BCELoss(x[obj_mask], y_true[..., 0][obj_mask]) * box_loss_scale[obj_mask])
loss_y = torch.mean(self.BCELoss(y[obj_mask], y_true[..., 1][obj_mask]) * box_loss_scale[obj_mask])
loss_w = torch.mean(self.MSELoss(w[obj_mask], y_true[..., 2][obj_mask]) * box_loss_scale[obj_mask])
loss_h = torch.mean(self.MSELoss(h[obj_mask], y_true[..., 3][obj_mask]) * box_loss_scale[obj_mask])
# box损失权重乘上0.1 暂时不清楚为什么使用0.1
loss_loc = (loss_x + loss_y + loss_h + loss_w) * 0.1
loss_cls = torch.mean(self.BCELoss(pred_cls[obj_mask], y_true[..., 5:][obj_mask]))
#定位需要经过两次权重?
loss += loss_loc * self.box_ratio + loss_cls * self.cls_ratio
#这里就有一个问题了,忽略样本怎么控制
loss_conf = torch.mean(self.BCELoss(conf, obj_mask.type_as(conf)[noobj_mask.bool() |obj_mask]))
#使用balance控制三个特征层对置信度loss的权重,[0.4,1,4]为超参数搜索得到,实际项目中可自行调整
loss += loss_conf * self.balance[l] * self.obj_ratio
从代码中可以看出,中心点x,y使用bce loss,宽高使用MSE loss,同时计算loss时使用了obj_mask,(含义参考get_target()) 即挑选的正样本产生边框损失,分类损失使用BCE loss,仍然使用obj_mask。置信度损失使用BCE loss,这里使用obj_mask作为target,表明正样本的置信度为1, 负样本的置信度为0,同时将noobj_mask和obj_mask做或运算,因为在noobj_mask,负样本的mask为1,忽略样本的mask为0,因此进行或运算后,负样本和正样本的mask均为1,忽略样本的mask为0,正好符合了忽略样本不参与loss计算的原则。
3. get_target():正负样本匹配
batch_target = torch.zeros_like(targets[b])
#x,y的坐标相对于对特征图的大小
batch_target[:, [0, 2]] = targets[b][:, [0, 2]] * in_w
batch_target[:, [1, 3]] = targets[b][:, [1, 3]] * in_h
batch_target[:, 4] = targets[b][:, 4]
batch_target = batch_target.cpu()
# gt_box (num_true_box, 4)
gt_box = torch.FloatTensor(torch.cat((torch.zeros((batch_target.size(0),2)), batch_target[:, 2:4]), 1 ))
# anchor_shape (9,4)
anchor_shapes = torch.FloatTensor(torch.cat((torch.zeros(len(anchors), 2), torch.FloatTensor(anchors)) ,1 ))
# 计算每个真实框和9个anchor之间的iou,并获得最大iou的索引
#(num_true_box, 9)--> (num_true_box, 1)
best_ns = torch.argmax(self.calculate_iou(gt_box, anchor_shapes), dim=-1)
首先将ground_truth的坐标映射成特征图大小,然后计算anchor和ground_truth的iou,这里由于anchor只有宽高,因此在gt_box和anchor_shape前面将x,y用0进行初始化。因此大家在很多博客都可以看到 “计算iou时,不考虑坐标只考虑宽高”的说法,因为此时计算iou用的时ground_truth和anchor。
for t, best_n in enumerate(best_ns):
if best_n not in self.anchors_mask[l]:
continue
#判断由哪一个anchor预测当前的ground_true
k = self.anchors_mask[l].index(best_n)
i = torch.floor(batch_target[t, 0]).long()
j = torch.floor(batch_target[t, 1]).long()
c = batch_target[t, 4].long()
noobj_mask[b, k, j, i] = 0
if not self.giou:
y_true[b, k, j, i, 0] = batch_target[t, 0] - i.float()
y_true[b, k, j, i, 1] = batch_target[t, 1] - j.float()
y_true[b, k, j, i, 2] = torch.log(batch_target[t, 2] / anchors[best_n][0])
y_true[b, k, j, i, 3] = torch.log(batch_target[t, 3] / anchors[best_n][1])
y_true[b, k, j, i, 4] = 1
y_true[b, k, j, i, c + 5] = 1
else:
#giou为什么不一样
y_true[b, k, j, i, 0] = batch_target[t, 0]
y_true[b, k, j, i, 1] = batch_target[t, 1]
y_true[b, k, j, i, 2] = batch_target[t, 2]
y_true[b, k, j, i, 3] = batch_target[t, 3]
y_true[b, k, j, i, 4] = 1
y_true[b, k, j, i, c + 5] = 1
box_loss_scale[b, k, j, i] = batch_target[t, 2] * batch_target[t, 3] / in_h / in_w
获得与ground_truth最大iou的anchor之后,这里获得了anchor的索引k,将对应noobj_mask设置为0,同时真实框减去grid的坐标,宽高进行反解码,映射到特征层大小,置信度置为1,对应的class_id置为1,当使用giou loss进行计算时,是直接计算预测框和ground_truth的iou 因此不需要映射到特征层,直接保存对应结果就行,同时将计算box_loss_scale并归一化。
5. get_ignore():忽略样本计算
-
预测解码
后面再补“