目录
8、多线程情况下HashMap1.7在扩容时为什么会出现线程不安全?
11、HashMap为什么会出现ConcurrentModificationException?
14、ConcurrentHashMap的put方法实现流程
1、为什么HashMap要用数组加链表来实现?
为了将Entry(key-value键值对)放入数组中,首先会对Entry中的key进行一个hashCode的计算,计算出来的hashCode值与数组大小会进行一个indexFor方法的计算,得到在数组中的索引。如果数组在该索引位置为空,就将该Entry的引用地址放入数组索引位置。当需要将另一个Entry放入数组时,如果该索引位置已有内容,则将该Entry以链表形式与前一个Entry联系起来。在1.7中以头插法,即将新插入的Entry引用地址放入数组索引位置,同时产生一个新的指针next指向之前的Entry。1.8中使用尾插法,即将当前数组中存放的链表中最后一个Entry的指针next指向该新的Entry,该法需要遍历该数组索引位置的链表,以找到最后一个Entry。
2、HashMap的put方法的大致实现流程?
① 先判断该数组是否是空数组,如果是则初始化该数组;
② 判断key值是否为null,如果为null,则;如果不为null,则
③ 通过key可以的到一个hashCode,利用hashCode和数组长度,可以通过indexOf()得到在数组中的索引i;
④ 如果该索引位置有对象,则会遍历该位置上的链表,如果链表中有Entry对象的key相同,则视为更新value,并且会返回被更新的value,如果没有,则将该Entry添加到这个数组位置(七上八下);
⑤ 如果元素添加进了数组,则modcount++,且会判断是否需要进行数组扩容(初始为16个,最多可以到2^30个)。
3、HashMap1.7的头插法是如何实现的?
将新插入的Entry引用地址放入数组索引位置,同时产生一个新的指针next指向之前的Entry。(保证当前链表的头节点一定要是数组该位置的元素)
例外题:1.8及之后的尾插法如何实现?(七上八下)
将当前数组中存放的链表中最后一个Node的指针next指向该新的Node,该法需要遍历该数组索引位置的链表,以找到最后一个Node。
4、HashMap中数组的大小有什么特点?
默认大小为2^4,扩容以0当前大小的0.75倍为阈值,超过当前阈值就会进行扩容。数组大小一定是2的幂次方数。
5、HashMap中数组的大小为什么要是2的幂次方?
为了保证在计算数组索引时,不会导致数组中有部分的位置浪费,而另一部分数据过多,链表过长。
例如:若默认数组大小为17,按照当前的数组索引计算方式,假设hashCode值为0100 1111,16的二进制为0001 0000,那么通过与运算的结果为0000 0000,即0,确实没有越界,但是如果hashCode值为1110 1111、1110 0101等等数时,结果均为0,同样的也会有很多hashCode得到的结果为16,导致大部分的数据都以链表的形式保存在数组的头尾处,而其他地方被浪费。只有当数组大小为2的幂次方数时,才能让数组大小减1的结果的二进制的低四位全为1。
6、HashMap中是如何计算数组下标的?
在源码中,return hashCode & (length-1);
是通过一个位运算来确定当前的数组下标的。
假设当前的hashCode为0101 0101,15的二进制为0000 1111,那么与运算后结果为0000 0101,转为十进制为5。
可以发现结果的第四位与hashCode值的低四位相同,那么可以推论:得到的地址的大小在0000-1111的范围内,即0-15,绝对在数组大小的范围内,不会越界。
不用取余运算用位运算的原因是,位运算的运算速度更快,性能更好。
7、HashMap1.7是如何进行扩容的?
默认的扩容因子为0.75,即以当前数组大小的0.75为阈值。当当前数组内已经存了阈值个数的元素,且新加入的元素放入的位置已经有元素的时候,就要进行扩容。如果当前数组内已经存了阈值个数的元素,但是新加入的元素放入的位置为空,也不会扩容。
在将老数组内的数转移到新数组的过程中,数组索引的变化也有规律。规律为:新数组的索引 = 老数组的索引 +老数组的大小或者与老数组索引一样
例外题:HashMap在1.8与1.7的区别?
首先1.8中,创建数组的时间与1.7版本不同,1.7是在new HashMap()时就已经创建数组,而1.8是在第一次添加元素,即put()时创建数组;其次1.8的底层数组是Node,而不是Entry;再有就是1.7的底层结构为数组加链表,而1.8的底层结构为数组加链表加红黑树。当数组某一索引位置上的元素以链表存在的数据个数大于2^3个且当前数组大小大于2^8时,该索引位置上的所有数据由链表改为红黑树存储。
8、多线程情况下HashMap1.7在扩容时为什么会出现线程不安全?
主要在转移元素时会产生线程不安全的问题,会出现循环链表的问题。
即在扩容时,如果有两个线程同时对一个数组扩容,可能会发生一个线程暂停运行,另一个线程继续执行直至程序结束,而先前暂停的线程此时重新运行时,就会导致两个问题,第一个是链表数据的缺失,第二个是产生循环链表。其实就是暂停的线程已经不从原数组取元素,而是向先走完的线程中已经扩容完的数组取元素。
而在1.8中,由于对HashMap进行了优化,采取了尾插法,因此不会出现环形链表的情况,但是依旧是线程不安全。
9、HashMap1.7的rehash底层如何实现?
rehash为重新计算key所对应的hashCode的大小。
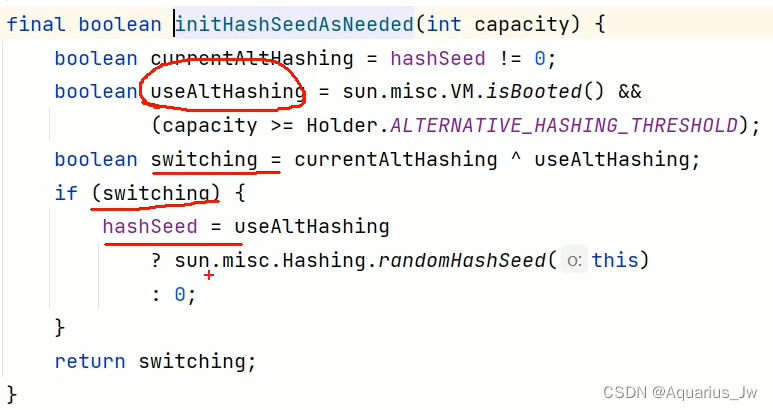
在底层源码中,初始的hashSeed=0,因此currentAltHashing为false。由于该方法返回的switching决定了是否要使用rehash方法,即switching为true时重新计算,而switching是由异或运算得到的,因此useAltHashing必须为true,这种情况下hashSeed才会重新赋值,而后才会进入rehash方法,重新计算hashCode。
那么useAltHashing何时为true呢?可以看到与传入的数组容量有关,当数组容量大于等于后面的这个值时,useAltHashing就为true。后面这个值的大小可以自行更改,默认为Integer.Max_VALUE。
10、HashMap中的modCount表示什么意思?
表示修改次数的意思。
对HashMap进行增删改的操作时,modCount都会自加,记录修改次数。
11、HashMap为什么会出现ConcurrentModificationException?
该异常为并发修改异常。
HashMap本身就不是线程安全的。
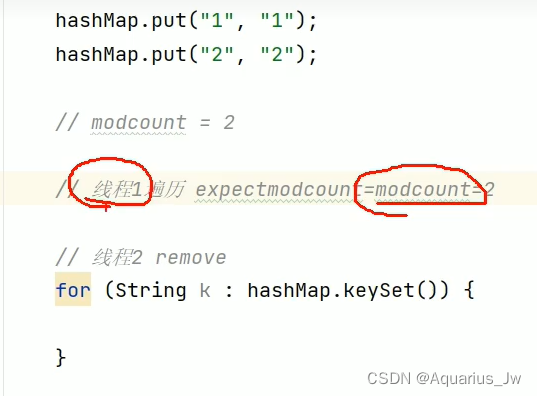
底层源码中设置当expectModCount != modCount时,就会报ConcurrentModificationException。上面例子中,在遍历开始前modCount = 2,而在下方的循环中产生了两个线程,当循环内部出现对于HashMap的修改时(线程2),modCount就会加1,与另一遍历的线程1中保存的expectModCount发生了冲突,因此会产生错误。
12、HashMap线程不安全体现在哪?
1.8在多线程环境下会发生数据覆盖的情况。
if ((p = tab[i = (n – 1) & hash]) == null)如果没有hash碰撞则会直接插入元素。
如果线程A和线程B同时进行put操作,刚好这两条不同的数据hash值一样,并且该位置数据为null,所以这线程A、B都会进入上面的代码。若线程A进入后还未进行数据插入时挂起,而线程B正常执行,从而正常插入数据,然后线程A获取CPU时间片,此时线程A不用再进行hash判断了,线程A会把线程B插入的数据给覆盖,发生线程不安全。
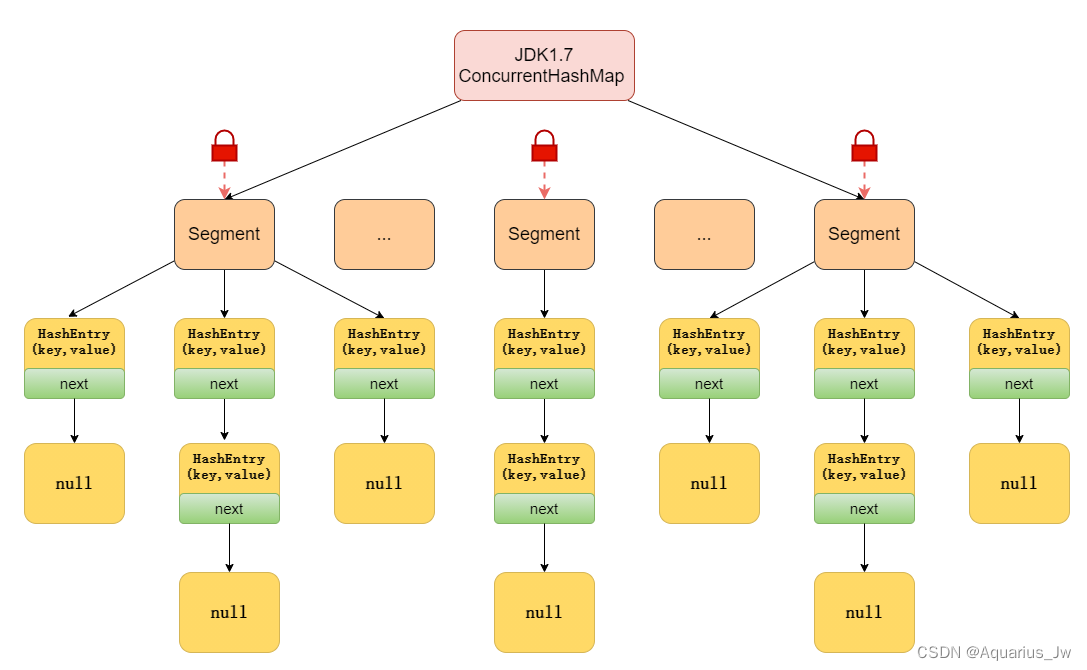
13、ConcurrentHashMap的底层原理实现
ConcurrentHashMap的底层实现在1.7和1.8中是不同的。
1.7:
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成,即把数组分为多个Segment,每个Segment里面是有多个Entry组成,每个Segment都有一把锁(因为Segment继承了ReentrantLock)。Segment默认为16,即并发度为16。
1.8:
ConcurrentHashMap选择了与HashMap相同的Node数组+链表+红黑树结构;使用了CAS+synchronized实现更加细粒度的锁。
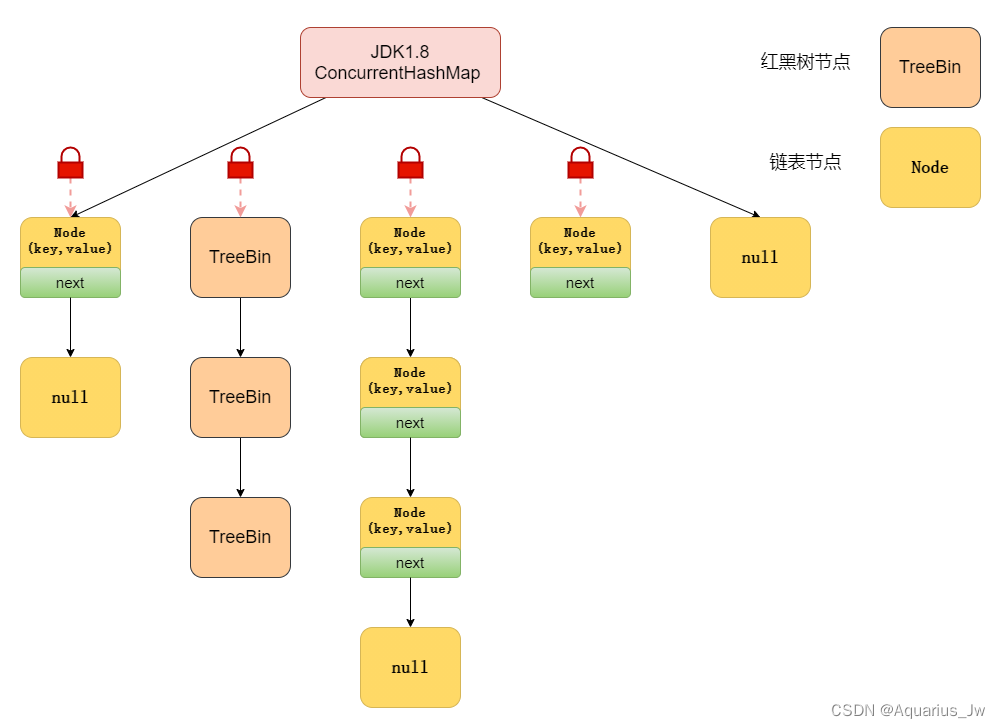
为什么要使用synchronized替换ReentrantLock?
是因为synchronized已经被优化过了,并且synchronized有多种锁状态,除此之外,还能够减少内存开销。
14、ConcurrentHashMap的put方法实现流程
1.7:
首先调用put方法时,会对要放入的Entry对象的key进行hashCode的计算,得到结果后在对应的要放入的Segment的位置生成Segment对象;而后并不是直接放入Segment中,而是再次调用Segment对象的put方法,在该过程中就已经加了一层的锁,而后将该对象放入Segment对象中对应的Entry里。在多线程的情况下,使用Segment对象的put方法时,会先尝试获取锁,如果获取失败表明有其他线程存在竞争,那么就需要利用scanAndLockForPut()自旋获取锁。第一步:尝试自旋获取锁。第二步:如果重试的次数达到了MAX_SCAN_RETRIES则改为阻塞锁获取,保证能获取成功。
1.8:
首先是根据要放入的Node对象的可以进行hashCode的计算,而后找到对应的Node的位置,拿到首节点f,判断首节点f:如果首节点f为null,则通过CAS的方式进行添加;如果f.hash = MOVED = -1,说明有另一线程在扩容;如果都不满足,则synchronized锁住f节点,判断是链表还是红黑树,利用尾插法遍历插入。当Node中的链表长度达到8时,数组扩容或转为红黑树(与HashMap类似)。
需要注意的是
ConcurrentHashMap
是不支持
key
或
value
为
null
的。