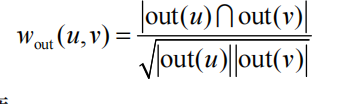推荐系统实战(四)——利用社交网络数据
学习自《推荐系统实战》项亮
利用社交网络数据
社交网络数据简介

此外,对图G中的用户顶点u,定义out(u)为顶点u指向的顶点集合(如果套用微博中的术语,
out(u)就是用户u关注的用户集合),定义in(u)为指向顶点u的顶点集合(也就是关注用户u的用户
集合)。那么,在Facebook这种无向社交网络中显然有out(u)=in(u)。
一般来说,有3种不同的社交网络数据。
-
双向确认的社交网络数据
在以Facebook和人人网为代表的社交网络中,用户A和B之间形成好友关系需要通过双方的确认。因此,这种社交网络一般可以通过无向图表示。 -
单向关注的社交网络数据
在以Twitter和新浪微博为代表的社交网络中,用户A可以关注用户B而不需要得到用户B的允许,因此这种社交网络中的用户关系是单向的,可以通过有向图表示。 -
基于社区的社交网络数据
还有一种社交网络数据,用户之间并没有明确的关系,但是这种数据包含了用户属于不同社区的数据。比如豆瓣小组,属于同一个小组可能代表了用户兴趣的相似性。或者在论文数据集中,同一篇文章的不同作者也存在着一定的社交关系。或者是在同一家公司工作的人,或是同一个学校毕业的人等
基于社交网络的推荐
社会化推荐之所以受到很多网站的重视,是缘于如下优点。
- 好友推荐可以增加推荐的信任度 好友往往是用户最信任的。用户往往不一定信任计算机的智能,但会信任好朋友的推荐。同样是给用户推荐《天龙八部》,前面提到的基于物品的协同过滤算法会说是因为用户之前看过《射雕英雄传》,而好友推荐会说是因为用户有8个好友都非常喜欢《天龙八部》。对比这两种解释,第二种解释一般能让用户更加心动,从而购买或者观看《天龙八部》。
-
社交网络可以解决冷启动问题 当一个新用户通过微博或者Facebook账号登录网站时,我们可以从社交网站中获取用户的好友列表,然后给用户推荐好友在网站上喜欢的物品。从而我们可以在没有用户行为记录时就给用户提供较高质量的推荐结果,部分解决了推荐系统的冷启动问题。
当然,社会化推荐也有一些缺点,其中最主要的就是很多时候并不一定能提高推荐算法的离线精度(准确率和召回率)。特别是在基于社交图谱数据的推荐系统中,因为用户的好友关系不是基于共同兴趣产生的,所以用户好友的兴趣往往和用户的兴趣并不一致。比如,我们和自己父母的兴趣往往就差别很大。不过,因为社会化推荐算法不一定能提供离线精度,而且包含社交网络数据和用户行为数据的数据集不太多,因此本章不准备通过离线实验证明社会化推荐的优势
基于邻域的社会化推荐算法
如果给定一个社交网络和一份用户行为数据集。其中社交网络定义了用户之间的好友关系,而用
户行为数据集定义了不同用户的历史行为和兴趣数据。那么我们想到的最简单算法是给用户推荐
好友喜欢的物品集合。即用户u对物品i的兴趣pui可以通过如下公式计算。
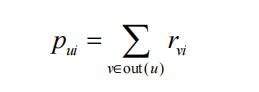
其中out(u)是用户u的好友集合,如果用户v喜欢物品i,则rvi=1,否则rvi=0。不过,即使都是
用户u的好友,不同的好友和用户u的熟悉程度和兴趣相似度也是不同的。因此,我们应该在推荐
算法中考虑好友和用户的熟悉程度以及兴趣相似度:
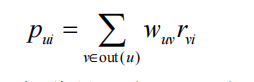
这里,wuv 由两部分相似度构成,一部分是用户u和用户v的熟悉程度,另一部分是用户u和用
户v的兴趣相似度。用户u和用户v的熟悉程度(familiarity)描述了用户u和用户v在现实社会中的
熟悉程度。一般来说,用户更加相信自己熟悉的好友的推荐,因此我们需要考虑用户之间的熟悉
度。熟悉度可以用用户之间的共同好友比例来度量。也就是说如果用户u和用户v很熟悉,那么一
般来说他们应该有很多共同的好友。
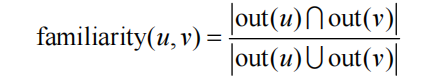
除了熟悉程度,还需要考虑用户之间的兴趣相似度。我们都和父母很熟悉,但很多时候我们
和父母的兴趣却不相似,因此也不会喜欢他们喜欢的物品。因此,在度量用户相似度时还需要考
虑兴趣相似度(similarity),而兴趣相似度可以通过和UserCF类似的方法度量,即如果两个用户
喜欢的物品集合重合度很高,两个用户的兴趣相似度很高。
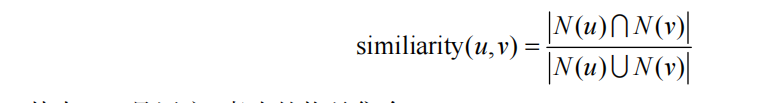
其中N(u)是用户u喜欢的物品集合。
基于图的社会化推荐算法
用户的社交网络可以表示为社交网络图,用户对物品的行为可以表示为用户物品二分图,而
这两种图可以结合成一个图。图6-7是一个结合了社交网络图和用户物品二分图的例子。该图上
有用户顶点(圆圈)和物品顶点(方块)两种顶点。如果用户u对物品i产生过行为,那么两个节
点之间就有边相连。比如该图中用户A对物品a、e产生过行为。如果用户u和用户v是好友,那么
也会有一条边连接这两个用户,比如该图中用户A就和用户B、D是好友。


在定义完图中的顶点、边和边的权重后,我们就可以利用前面几章提到的PersonalRank图排
序算法给每个用户生成推荐结果。
信息流推荐
给用户推荐好友
基于内容的匹配
我们可以给用户推荐和他们有相似内容属性的用户作为好友(如图6-15所示)。下面给出了
常用的内容属性。
用户人口统计学属性,包括年龄、性别、职业、毕业学校和工作单位等。
用户的兴趣,包括用户喜欢的物品和发布过的言论等。
用户的位置信息,包括用户的住址、IP地址和邮编等。
利用内容信息计算用户的相似度和我们前面讨论的利用内容信息计算物品的相似度类似。
基于共同兴趣的好友推荐
在Twitter和微博为代表的以兴趣图谱为主的社交网络中,用户往往不关心对于一个人是否在
现实社会中认识,而只关心是否和他们有共同的兴趣爱好。因此,在这种网站中需要给用户推荐
和他有共同兴趣的其他用户作为好友。
我们在第3章介绍基于用户的协同过滤算法(UserCF)时已经详细介绍了如何计算用户之间
的兴趣相似度,其主要思想就是如果用户喜欢相同的物品,则说明他们具有相似的兴趣。在新浪
微博中,可以将微博看做物品,如果两个用户曾经评论或者转发同样的微博,说明他们具有相似
的兴趣。在Facebook中,因为有大量用户Like(喜欢)的数据,所以更容易用UserCF算法计算用
户的兴趣相似度。关于这方面的算法可以参考第3章。
此外,也可以根据用户在社交网络中的发言提取用户的兴趣标签,来计算用户的兴趣相似度。
关于如何分析用户发言的内容、提取文本的关键词、计算文本的相似度,可以参考第4章。
基于社交网络图的好友推荐
在社交网站中,我们会获得用户之间现有的社交网络图,然后可以基于现有的社交网络给用户推荐新的好友,比如可以给用户推荐好友的好友。
最简单的好友推荐算法是给用户推荐好友的好友。在人人网,我们经常可以通过这个功能找到很多自己的老同学。在刚开始用人人网时,我们只能加入有限的好友,因为我们记住的好友有限。虽然我们只能记住几个同学,但那些同学又能记住几个不同的同学,在这种情况下,我们可以通过朋友的朋友找到更多我们认识的人。
基于好友的好友推荐算法可以用来给用户推荐他们在现实社会中互相熟悉,而在当前社交网络中没有联系的其他用户。下面将介绍3种基于社交网络的好友推荐算法。
对于用户u和用户v,我们可以用共同好友比例计算他们的相似度: