Consider the vector
x
⃗
=
(
1
,
ε
)
∈
R
2
where
ε
>
0
is small. The
l
1
and
l
2
norms of
x
⃗
, respectively, are given by
|
|
x
⃗
|
|
1
=
1
+
ε
,
|
|
x
⃗
|
|
2
2
=
1
+
ε
2
Now say that, as part of some regularization procedure, we are going to reduce the magnitude of one of the elements of
x
⃗
by
δ
≤
ε
. If we change
x
1
to
1
−
δ
, the resulting norms are
|
|
x
⃗
−
(
δ
,
0
)
|
|
1
=
1
−
δ
+
ε
,
|
|
x
⃗
−
(
δ
,
0
)
|
|
2
2
=
1
−
2
δ
+
δ
2
+
ε
2
On the other hand, reducing
x
2
by
δ
gives norms
|
|
x
⃗
−
(
0
,
δ
)
|
|
1
=
1
−
δ
+
ε
,
|
|
x
⃗
−
(
0
,
δ
)
|
|
2
2
=
1
−
2
ε
δ
+
δ
2
+
ε
2
The thing to notice here is that, for an
l
2
penalty, regularizing the larger term
x
1
results in a much greater reduction in norm than doing so to the smaller term
x
2
≈
0
. For the
l
1
penalty, however, the reduction is the same. Thus, when penalizing a model using the
l
2
norm, it is highly unlikely that anything will ever be set to zero, since the reduction in norm going from
ε
to
0
is almost nonexistent when
ε
is small. On the other hand, the reduction in
l
1
norm is always equal to
δ
, regardless of the quantity being penalized.
Another way to think of it: it’s not so much that
l
1
penalties encourage sparsity, but that
l
2
penalties in some sense discourage sparsity by yielding diminishing returns as elements are moved closer to zero.
an
l
α
penalty for any
α
≤
1
will also induce sparsity, but you see those less often in practice (probably because they’re non-convex). If you really just want sparsity then an
l
0
penalty (proportional to the number of non-zero entries) is the way to go, it just so happens that it’s a bit of a nightmare to work with.
Yes – that’s correct. There are many norms that lead to sparsity (e.g., as you mentioned, any Lp norm with p <= 1). In general, any norm with a sharp corner at zero induces sparsity. So, going back to the original question – the L1 norm induces sparsity by having a discontinuous gradient at zero (and any other penalty with this property will do so too)
Have a look on figure 3.11 (page 71) of The elements of statistical learning. It shows the position of a unconstrained
β
^
that minimizes the squared error function, the ellipses showing the levels of the square error function, and where are the
β
^
subject to constraints
ℓ
1
(
β
^
)
<
t
and
ℓ
2
(
β
^
)
<
t
.
This will allow you to understand very geometrically that subject to the
ℓ
1
constraint, you get some null components. This is basically because the
ℓ
1
ball
{
x
:
ℓ
1
(
x
)
≤
1
}
has “edges” on the axes.
More generally, this book is a good reference on this subject: both rigorous and well illustrated, great explanations.
I think your second paragraph is a key… at least for my intuition: an l1 “ball” is more like a diamond that’s spikey along the axes, which means that a hyperplane constrained to hit it is more likely to have a zero on the axes.
Yes, I use to imagine the optimization process as the movement of a point submitted to two forces : attraction towards the unconstrained
β
^
thanks to the squared error function, attraction towards 0 thaks to the
ℓ
1
or
ℓ
2
norm. Here, the “geometry” of this attraction force changes the behavior of the point. If you fix a small
ℓ
1
or
ℓ
2
ball in which it can freely move, it will slide on the border of the ball, in order to go near to
β
^
. The result is shown on the illustration in the aforementionned book.
With a sparse model, we think of a model where many of the weights are 0. Let us therefore reason about how L1-regularization is more likely to create 0-weights.
Consider a model consisting of the weights
(
w
1
,
w
2
,
…
,
w
m
)
.
With L1 regularization, you penalize the model by a loss function
L
1
(
w
)
=
Σ
i
|
w
i
|
.
With L2-regularization, you penalize the model by a loss function
L
2
(
w
)
=
1
2
Σ
i
w
2
i
If using gradient descent, you will iteratively make the weights change in the opposite direction of the gradient with a step size
η
. Let us look at the gradients:
d
L
1
(
w
)
d
w
=
s
i
g
n
(
w
)
, where
s
i
g
n
(
w
)
=
(
w
1
|
w
1
|
,
w
1
|
w
1
|
,
…
,
w
1
|
w
m
|
)
d
L
2
(
w
)
d
w
=
w
If we plot the loss function and it’s derivative for a model consisting of just a single parameter, it looks like this for L1:

Notice that for
L
1
, the gradient is either 1 or -1, except for when
w
1
=
0
. That means that L1-regularization will move any weight towards 0 with the same step size, regardless the weight’s value. In contrast, you can see that the
L
2
gradient is linearly decreasing towards 0 as the weight goes towards 0. Therefore, L2-regularization will also move any weight towards 0, but it will take smaller and smaller steps as a weight approaches 0.
Try to imagine that you start with a model with
w
1
=
5
and using
η
=
1
2
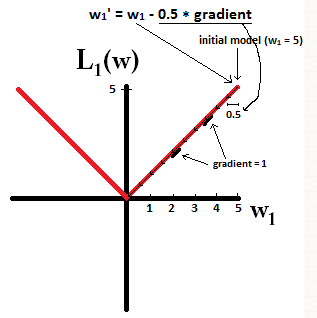
. In the following picture, you can see how gradient descent using L1-regularization makes 10 of the updates
w
1
:
=
w
1
−
η
⋅
d
L
1
(
w
)
d
w
=
w
1
−
0.5
⋅
1
, until reaching a model with
w
1
=
0
:
In constrast, with L2-regularization where
η
=
1
2
, the gradient is
w
1
, causing every step to be only halfway towards 0. That is we make the update
w
1
:
=
w
1
−
η
⋅
d
L
1
(
w
)
d
w
=
w
1
−
0.5
⋅
w
1
Therefore, the model never reaches a weight of 0, regardless of how many steps we take:
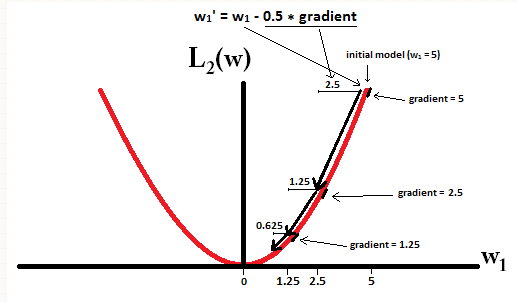
Note that L2-regularization can make a weight reach zero if the step size
η
is so high that it reaches zero or beyond in a single step. However, the loss function will also consist of a term measuring the error of the model with the respect to the given weights, and that term will also affect the gradient and hence the change in weights. However, what is shown in this example is just how the two types of regularization contribute to a change in weights.