目录
一、问题处理与总结
之前遇到了1个执行异常缓慢的存储过程,在空数据的情况下执行了整整4分钟,但单独拿出来执行却很快。后来在DBA的帮助下确定了问题原因在于表与存储过程的字符集不一致导致。修改后存储过程执行时间降到了3s,问题解决。后来又深入了解了下字符集是怎么导致存储过程执行缓慢的。刚好趁着别人都去过七夕了没人打扰整理出来分享下。

先说结论,字符集不一致其实只是导火索,真正让存储过程执行缓慢的凶手是隐式类型转换所导致的索引失效。
首先介绍下2种涉及到的字符集,utf8与utf8mb4,前者是3字节unicode编码,后者是4字节unicode编码,后者是前者的超集,兼容前者。说的通俗点就是utf8mb4能编码更多的生僻字。
然后再介绍下mysql索引失效的其中1条规则,即不能出现类型转换。举个例子,我在1个字符类型上加了索引,但是查询的时候使用了column=1而不是column=‘1’,则不会使用索引。下面我用explain来具体展示下(explain是Mysql的分析工具,可以展现出这条sql经过mysql优化器处理后的效果,不熟悉的朋友只要知道它有1列叫做key,会显示是否利用到了索引)

下图我们看到命中了主键索引

而使用aaa=1则未命中
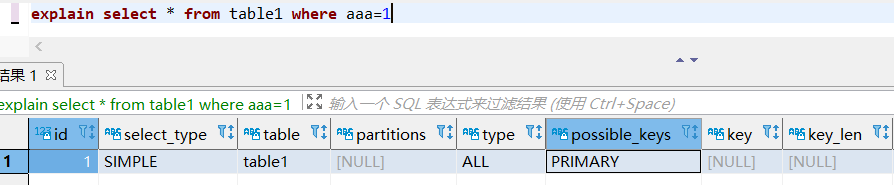
事实上第二种情况相当于select * from table1 where CAST(aaa AS signed int)=1;
介绍完了隐式类型转换和explain我们再回到字符集的问题上来,以子查询为例,如果子查询返回的列类型为utf8mb4,父查询后跟着的参数是utf8则会产生隐式类型转换,导致索引失效,反之则不会,原因在于utf8mb4是utf8的超集,兼容前者。
这里我新建了2张表并将他们的字符集设置为了不同。


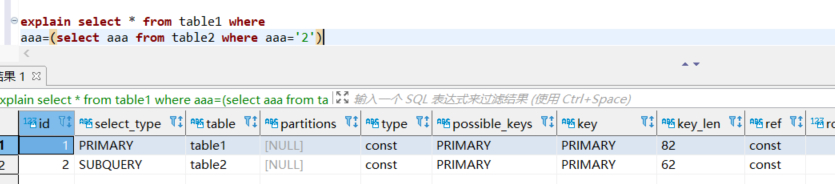
我们可以很明显的看出索引的命中情况。再回到存储过程中,开头提到的问题实际上还是因为存储过程读入参数的字符集是通过character_set_server这个全局变量控制的。而存储过程使用到的表却是utf8的,这就导致了这一问题的产生。
二、由此而拓展开来的思路
这一部分已经与开头的问题无关了,只是刚好查问题的时候碰见了,也顺道整理出来,当作拓展。当然网上的资料很多都是抄来抄去,如有错误欢迎指出。
这里主要想介绍下索引优化方案中的覆盖索引,但是要引出覆盖索引我们还得先介绍点别的。
1、 Mysql中索引是基于B+树实现的。
有兴趣了解的朋友可以看这篇文章
《B树、B+树详解》
,我的理解如下:
(1)把二叉树揉合成了m叉树,减小了树的深度(使得磁盘寻道时间减少)
(2)只有叶子节点存放数据,其余节点只存放索引。(这个索引不是指Mysql的索引)(使得1个磁盘块能存放更多的索引(此处指mysql索引),同样减少了磁盘寻道时间)
2、 聚簇索引与非聚簇索引
在InnoDB中,主键索引也叫聚簇索引,非主键索引则叫做辅助索引、非聚簇索引。聚簇索引这颗树的叶子节点存储的是主键索引+数据。而非聚簇索引这颗树的叶子节点则存储的是主键索引。因此当我们使用非聚簇索引时实际上会遍历2颗索引树。(官方把这个过程称为回表)。也因此,书上描述聚簇索引的说法是
“聚簇索引的存储顺序就是物理数据的存储顺序”
而MyISAM则不区分聚簇、非聚簇,不管哪种索引叶子节点都不存储数据,只存储指向数据的指针。

前置条件终于介绍完毕,轮到覆盖索引登场。覆盖索引的简单定义:通过二级索引查询所需数据,如果二级索引中已经覆盖了所要查询字段,就是覆盖索引。比如说,我建了1个组合索引(a,b,c),当我使用a,b去查询时,如果查询结果我只写了a,b,c则Mysql在访问完这颗非聚簇索引树后便会直接返回,不会再去访问聚簇索引树(因为组合索引的节点包含了a,b,c这3个值)。
是否利用了覆盖索引可以通过explain工具的extra列展示的值是否包括using index判断。
下面我们来复现下,在table2上新建1个组合索引,然后尝试2条查询列不同的sql。



通过第三张图我们可以看到利用到了覆盖索引。
这也提示了我们合理的建立组合索引替代单列索引,可以减少回表,实现索引优化的效果。