Hadoop之计算框架Tez的基本使用
Tez概述
官网:
https://tez.apache.org/
Tez是支持DAG作业的开源计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升DAG 作业的性能。
Tez源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,这样,这些分解后的元操作可以灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。
两个组成部分:
1.数据处理管道引擎,其中一个引擎可以插入输入,处理和输出实现以执行任意数据处理
2.数据处理应用程序的主机,通过它可以将上述任意数据处理“任务”组合到任务 DAG 中,以根据需要处理数据。
Tez运行过程:
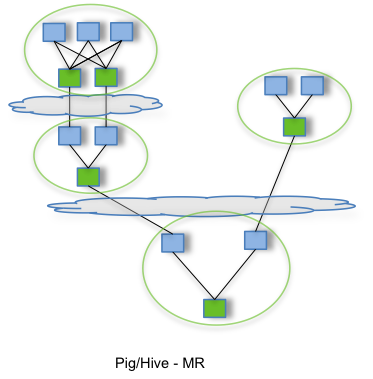
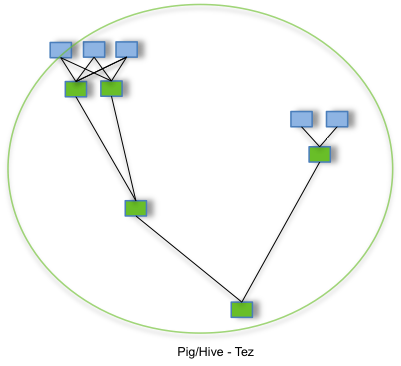
通过允许诸如Apache Hive和Apache Pig之类的项目运行复杂的 DAG(运行计算的有向无环图)任务,Tez 可以用于处理数据,该数据以前需要执行多个MR作业,而现在在单个Tez作业中
第一个图表展示的流程包含多个MR任务,每个任务都将中间结果存储到HDFS上——前一个步骤中的reducer为下一个步骤中的mapper提供数据。第二个图表展示了使用Tez时的流程,仅在一个任务中就能完成同样的处理过程,任务之间不需要访问HDFS。
Tez编译
Tez编译是为了与Hadoop版本保持一致。
Tea各版本:
https://tez.apache.org/releases/
下载Tez源码
wget https://dlcdn.apache.org/tez/0.10.1/apache-tez-0.10.1-src.tar.gz
修改pom.xml
解压、重命名
tar -zxvf apache-tez-0.10.1-src.tar.gz
mv apache-tez-0.10.1-src tez
在pom.xml中更改
hadoop.version
属性值,以匹配所使用的hadoop版本
cd tez
<hadoop.version>3.1.3</hadoop.version>
注意pom.xml中guava的版本,使用Hadoop使用的版本
ll hadoop/share/hadoop/common/lib/guava*
-rw-r--r-- 1 root root 2747878 May 12 22:48 hadoop/share/hadoop/common/lib/guava-27.0-jre.jar
<guava.version>27.0-jre</guava.version>
注释模块
tez-ui这个模块和tez-ext-service-tests模块是耗时耗力不讨好,而且没啥用,所以我们可以直接跳过
<!--
<module>tez-ext-service-tests</module>
<module>tez-ui</module>
-->
开始编译
安装编译工具
yum -y install autoconf automake libtool cmake ncurses-devel openssl-devel lzo-devel zlib-devel gcc gcc-c++
开始编译Tez
mvn clean package -DskipTests=true -Dmaven.javadoc.skip=true
Tez与Hadoop
上传Tez到HDFS
直接使用其二进制包来安装
wget https://dlcdn.apache.org/tez/0.10.1/apache-tez-0.10.1-bin.tar.gz
将tez/share目录中的tez.tar.gz压缩包上传到HDFS的Tez目录中
hadoop fs -mkdir -p /tez
cd /usr/local/program/tez/share
hadoop fs -put tez.tar.gz /tez
hadoop fs -chmod -R 777 /tez
创建配置文件tez-site.xml
在Hadoop配置目录创建配置文件tez-site.xml:
vim hadoop/etc/hadoop/tez-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指向hdfs上的tez.tar.gz包 -->
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/tez/tez.tar.gz</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.am.resource.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>tez.am.resource.cpu.vcores</name>
<value>1</value>
</property>
<property>
<name>tez.container.max.java.heap.fraction</name>
<value>0.4</value>
</property>
<property>
<name>tez.task.resource.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>tez.task.resource.cpu.vcores</name>
<value>1</value>
</property>
</configuration>
更多配置
Tez参数配置:
https://tez.apache.org/releases/0.10.1/tez-api-javadocs/configs/TezConfiguration.html
Tez运行时参数配置:
https://tez.apache.org/releases/0.10.1/tez-runtime-library-javadocs/configs/TezRuntimeConfiguration.html
配置环境变量
把Tez中所有jar包添加到HADOOP_CLASSPATH
vim /usr/local/program/hadoop/etc/hadoop/hadoop_env.sh
TEZ_CONF_DIR=$HADOOP_HOME/etc/hadoop/tez-site.xml
TEZ_JARS=/usr/local/program/tez
export HADOOP_CLASSPATH=${HADOOP_CLASSPATH}:${TEZ_CONF_DIR}:${TEZ_JARS}/*:${TEZ_JARS}/lib/*
修改mapred-site.xml 文件
<property>
<name>mapreduce.framework.name</name>
<value>yarn-tez</value>
</property>
修改之后将mapred-site.xml和hadoop_env.sh,tez-site.xml文件同步到集群所有的节点上
Tez和Hadoop的兼容
tez的lib目录中的hadoop包的版本和实际安装的hadoop版本可能不一定一致,如果不一致则需要将其jar删除与替换
cd tez
rm -rf lib/hadoop-mapreduce-client-core-*.jar lib/hadoop-mapreduce-client-common-*.jar
cp /usr/local/program/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-common-core-*.jar ./
cp /usr/local/program/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-core-*.jar ./
作业测试
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
[root@administrator hadoop]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/program/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/program/tez/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2022-05-16 09:55:59,529 INFO client.RMProxy: Connecting to ResourceManager at administrator/172.22.4.21:8032
2022-05-16 09:56:00,674 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1652665777479_0003
2022-05-16 09:56:00,914 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-05-16 09:56:01,225 INFO input.FileInputFormat: Total input files to process : 0
2022-05-16 09:56:01,285 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-05-16 09:56:01,737 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-05-16 09:56:01,769 INFO mapreduce.JobSubmitter: number of splits:0
2022-05-16 09:56:01,975 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-05-16 09:56:02,054 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1652665777479_0003
2022-05-16 09:56:02,054 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-05-16 09:56:02,451 INFO client.YARNRunner: Number of stages: 2
2022-05-16 09:56:02,530 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-05-16 09:56:02,621 INFO conf.Configuration: resource-types.xml not found
2022-05-16 09:56:02,622 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-05-16 09:56:02,992 INFO counters.Limits: Counter limits initialized with parameters: GROUP_NAME_MAX=256, MAX_GROUPS=500, COUNTER_NAME_MAX=64, MAX_COUNTERS=1200
2022-05-16 09:56:02,992 INFO counters.Limits: Counter limits initialized with parameters: GROUP_NAME_MAX=256, MAX_GROUPS=500, COUNTER_NAME_MAX=64, MAX_COUNTERS=120
2022-05-16 09:56:02,992 INFO client.TezClient: Tez Client Version: [ component=tez-api, version=0.10.1, revision=067af9f02ac8d2e9ec777f6098c861bdd5e52da0, SCM-URL=scm:git:https://gitbox.apache.org/repos/asf/tez.git, buildTime=2021-06-17T14:22:56Z, buildUser=lbodor, buildJavaVersion=1.8.0_151 ]
2022-05-16 09:56:03,012 INFO client.RMProxy: Connecting to ResourceManager at administrator/172.22.4.21:8032
2022-05-16 09:56:03,015 INFO client.TezClient: Submitting DAG application with id: application_1652665777479_0003
2022-05-16 09:56:03,018 INFO client.TezClientUtils: Using tez.lib.uris value from configuration: hdfs://administrator:9000/tez/tez.tar.gz
2022-05-16 09:56:03,018 INFO client.TezClientUtils: Using tez.lib.uris.classpath value from configuration: null
2022-05-16 09:56:03,070 INFO client.TezClient: Tez system stage directory hdfs://administrator:9000/tmp/hadoop-yarn/staging/root/.staging/job_1652665777479_0003/.tez/application_1652665777479_0003 doesn't exist and is created
2022-05-16 09:56:03,117 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-05-16 09:56:03,648 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-05-16 09:56:04,192 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-05-16 09:56:04,235 INFO client.TezClient: Submitting DAG to YARN, applicationId=application_1652665777479_0003, dagName=word count
2022-05-16 09:56:04,907 INFO impl.YarnClientImpl: Submitted application application_1652665777479_0003
2022-05-16 09:56:04,921 INFO client.TezClient: The url to track the Tez AM: http://administrator:8088/proxy/application_1652665777479_0003/
2022-05-16 09:56:16,796 INFO client.RMProxy: Connecting to ResourceManager at administrator/172.22.4.21:8032
2022-05-16 09:56:17,060 INFO mapreduce.Job: The url to track the job: http://administrator:8088/proxy/application_1652665777479_0003/
2022-05-16 09:56:17,068 INFO mapreduce.Job: Running job: job_1652665777479_0003
2022-05-16 09:56:18,107 INFO mapreduce.Job: Job job_1652665777479_0003 running in uber mode : false
2022-05-16 09:56:18,110 INFO mapreduce.Job: map 0% reduce 0%
2022-05-16 09:56:30,276 INFO mapreduce.Job: map 0% reduce 100%
2022-05-16 09:56:30,283 INFO mapreduce.Job: Job job_1652665777479_0003 completed successfully
2022-05-16 09:56:30,303 INFO mapreduce.Job: Counters: 0

Tez与Hive整合
hive有三种引擎:mapreduce、spark、tez,默认引擎为MapReduce,但MapReduce的计算效率非常低,而Spark和Tez引擎效率高,公司一般会使用Spark或Tez作为hive的引擎。
拷贝Jar
将Tez目录下的所有jar包拷贝至{HIVE_HOME}/lib目录下
cd /usr/local/program/tez
scp -r *.jar /usr/local/program/hive/lib/
scp -r lib/*.jar /usr/local/program/hive/lib/
ll /usr/local/program/hive/lib/tez-*
注意:如果是集群配置Hive,需要将Tez的依赖包需要拷贝至HiveServer2和HiveMetastore服务所在节点的相应目录下
修改hive-site.xml配置文件
指定hive使用tez计算框架
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
<property>
<name>hive.tez.container.size</name>
<value>1024</value>
</property>
临时使用,在进入hive shell交互时使用
# 设置hive执行引擎为tez
set hive.execution.engine=tez;
# 设置tez使用内存
set hive.tez.container.size=2048;
重启Hive
nohup hive --service metastore > /dev/null 2>&1 &
nohup hiveserver2 > /dev/null 2>&1 &
netstat -apn |grep 10000
netstat -apn |grep 9083
hive
create table tb_user(id int,name string);
insert into tb_user values (1,"hive1");
insert into tb_user values (2,"hive2");
insert into tb_user values (3,"hive3");
insert into tb_user values (4,"hive4");
insert into tb_user values (5,"hive5");
SELECT * FROM tb_user;
Tez参数设置
hive使用tez执行引擎
set hive.execution.engine=tez;
Map任务分组分片的最大和最小值,最大最小都会影响性能;
//默认5010241024
set tez.grouping.min-size=256000000;
//默认 102410241024
set tez.grouping.max-size=3221225472;
在yarn集群中的队列名称
set tez.queue.name=root.odms;
tez引擎设置任务名称
set tez.job.name=job_dm_icsm_ts_area_manage_bdp;
mapReduce引擎设置任务名称
set mapred.job.name=job_dm_icsm_ts_area_manage_bdp;
打开Tez的 auto reducer 并行特性。启用后,配置单元仍将估计数据大小并设置并行度估计。Tez将采样源顶点的输出大小,并在运行时根据需要调整估计值。
//默认为false
set hive.tez.auto.reducer.parallelism=true;
设置reduce的个数
set mapred.reduce.tasks =1000;
Tez优化
内存大小设置
1.设置tez AM容器内存
tez.am.resource.memory.mb
修改配置文件:tez-site.xml
默认值:1024
建议:不小于或者等于yarn.scheduler.minimum-allocation-mb值
2.设置tez container内存
hive.tez.container.size
修改配置文件:hive-site-xml
默认值:-1;默认情况下,Tez将生成一个mapper大小的容器
建议:不小于或者是yarn.scheduler.minimum-allocation-mb的倍数
JVM参数设置
1.设置 AM jvm,启动TEZ任务进程期间提供的命令行选项
tez.am.launch.cmd-opts
修改配置文件:tez-site.xml
默认大小:80%*tez.am.resource.memory.mb
建议:不要在这些启动选项中设置任何xmx或xms,以便tez可以自动确定它们
2.设置 container jvm
hive.tez.java.ops
修改配置文件:hive-site.xml
默认大小:80%hive.tez.container.size
说明:在hive 2.x的官方文档中没有找到这个参数
3.设置task/AM占用jvm内存大小的比例
tez.container.max.java.heap.fraction
修改配置文件:tez-site.xml
默认值:0.8
说明:这个值按具体需要调整,当内存不足时,一般都要调小
Hive内存Map Join参数设置
1.设置输出排序内存大小
tez.runtime.io.sort.mb
配置文件:tez-site.xml
默认值:100
建议:40%hive.tez.container.size,一般不超过2G
2.是否将多个mapjoin合并为一个
hive.auto.convert.join.noconditionaltask
配置文件:hive-site.xml
默认值:true
建议:使用默认值
3.限制输入的表文件的大小
hive.auto.convert.join.noconditionaltask.size
配置文件:hive-site.xml
默认值:10000000 (10M)
参数使用前提是hive.auto.convert.join.noconditionaltask值为true,
多个mapjoin转换为1个时,所有小表的文件大小总和小于这个值,这个值只是限制输入的表文件的大小,
并不代表实际mapjoin时hashtable的大小
建议值:1/3* hive.tez.container.size
4.使用的缓冲区大小
tez.runtime.unordered.output.buffer.size-mb
配置文件:tez-site.xml
如果不直接写入磁盘,使用的缓冲区大小
默认值:100M
建议:10%* hive.tez.container.size
5.容器重用
tez.am.container.reuse.enabled
配置文件:tez-ste.xml
默认值:true