文章目录
ShardingSphere介绍和实战
ShardingSphere介绍
ShardingSphere是一款起源于当当网内部的应用框架。在2017年开始开源。并逐渐由原本只关注于关系型数据库增强工具的ShardingJDBC升级成为一整套以数据分片为基础的数据生态圈,更名为ShardingSphere。到2020年4月,已经成为了Apache软件基金会的顶级项目。
ShardingSphere包含三个重要的产品,ShardingJDBC、ShardingProxy和ShardingSidecar。其中sidecar是针对service mesh定位的一个分库分表插件,目前在规划中。其中,ShardingJDBC是用来做客户端分库分表的产品,而ShardingProxy是用来做服务端分库分表的产品。这两者定位有什么区别呢?我们看下官方资料中给出的两个重要的图:
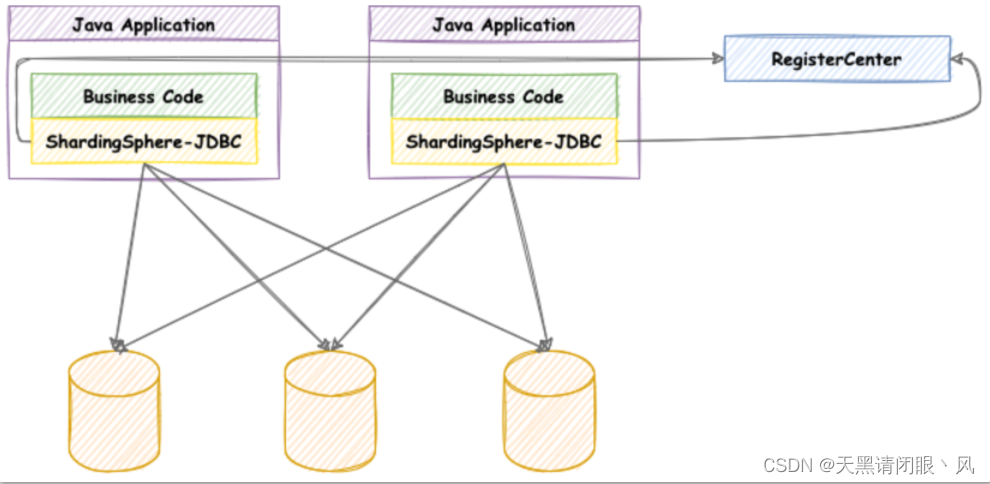
shardingJDBC定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。它使⽤客户端直连数据库,以 jar 包形式提供服务,⽆需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
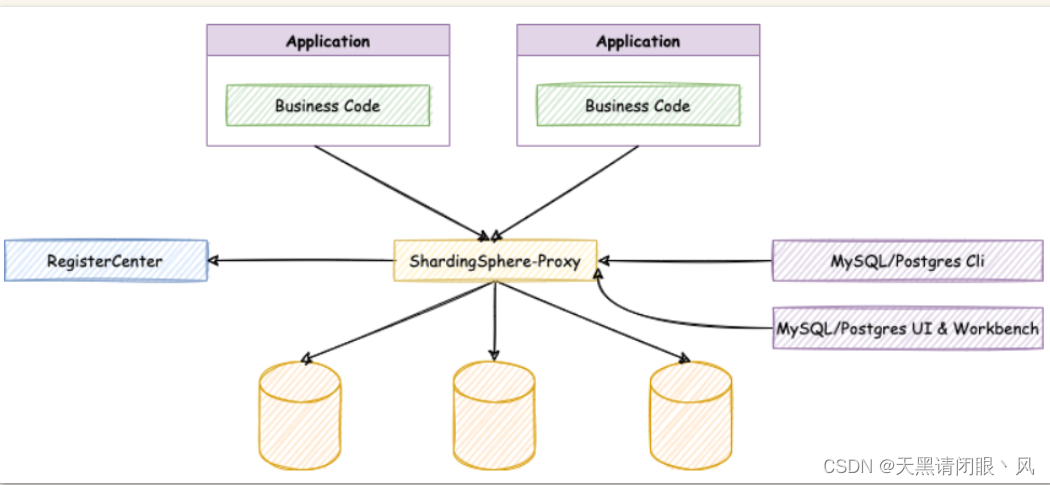
ShardingProxy定位为透明化的数据库代理端,提供封装了数据库⼆进制协议的服务端版本,⽤于完成对异构语⾔的⽀持。⽬前提供 MySQL 和 PostgreSQL 版本,它可以使⽤任何兼容 MySQL/PostgreSQL 协议的访问客⼾端。
很显然,ShardingJDBC只是客户端的一个工具包,可以理解为一个特殊的JDBC驱动包,所有分库分表逻辑均由业务方自己控制,所以他的功能相对灵活,支持的数据库也非常多,但是对业务侵入大,需要业务方自己定制所有的分库分表逻辑。而ShardingProxy是一个独立部署的服务,对业务方无侵入,业务方可以像用一个普通的MySQL服务一样进行数据交互,基本上感觉不到后端分库分表逻辑的存在,但是这也意味着功能会比较固定,能够支持的数据库也比较少。这两者各有优劣。
ShardingJDBC介绍
核心概念
逻辑表:水平拆分的数据库的相同逻辑和数据结构表的总称
真实表:在分片的数据库中真实存在的物理表。
数据节点:数据分片的最小单元。由数据源名称和数据表组成
绑定表:分片规则一致的主表和子表。
广播表:也叫公共表,指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中都完全一致。例如字典表。
分片键:用于分片的数据库字段,是将数据库(表)进行水平拆分的关键字段。SQL中若没有分片字段,将会执行全路由,性能会很差。
分片算法:通过分片算法将数据进行分片,支持通过=、BETWEEN和IN分片。分片算法需要由应用开发者自行实现,可实现的灵活度非常高。
分片策略:真正用于进行分片操作的是分片键+分片算法,也就是分片策略。在ShardingJDBC中一般采用基于Groovy表达式的inline分片策略,通过一个包含分片键的算法表达式来制定分片策略,如t_user_$->{u_id%8}标识根据u_id模8,分成8张表,表名称为t_user_0到t_user_7。
ShardingJDBC实战
环境搭建和踩坑
基础环境
数据库创建逻辑表 user和对应的真实表 user1、user2
# 真实表sql和逻辑表一致
CREATE TABLE `sharding_user` (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`user_name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`source` varchar(255) DEFAULT 'test',
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=latin1;

实体类和controller
@Data
@TableName("sharding_user")
public class ShardingUser implements Serializable {
@TableId(type = IdType.NONE)
private Long id;
private String userName;
private Integer age;
private String source;
private Date createTime;
private Date updateTime;
}
@GetMapping("/shardingTest")
public R shardingTest(String name,Integer age){
ShardingUser user = new ShardingUser();
user.setUserName(name);
user.setAge(age);
shardingUserService.save(user);
return R.success("成功");
}
其他的service mapper impl 按照mybatis-plus模式来创建。保证能够实现基础的增删改查
sharding-jdbc环境
依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
springboot2.x整合ShardingJDBC 4.1.1 坑很多,配置好依赖后启动看有没有问题。
启动报错:
Property 'sqlSessionFactory' or 'sqlSessionTemplate' are required
启动类添加
exclude={DruidDataSourceAutoConfigure.class}
我这里用的是Druid的数据源 所以要排除掉。如果是其他数据源,同理排除掉对应数据源的自动配置类
application.yml添加sharding-jdbc配置
# 顶层是 spring: 开头 因为spring:下面还有其他不相关的配置 ,所以后续一律以shardingsphere:开头展示
shardingsphere:
props:
sql:
show: true
datasource:
# 配置逻辑库名
names: m1
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/sharding_test?useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&tinyInt1isBit=false&allowMultiQueries=true&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=true
username: root
password: root
sharding:
tables:
# 配置逻辑表名
sharding_user:
actual-data-nodes:
# 逻辑表和真实表的对应关系
m1.sharding_user$->{1..2}
# 配置主键生成策略 采用雪花算法
key-generator:
column: id
type: SNOWFLAKE
props:
worker:
id: 1
# 分表策略
table-strategy:
inline:
# 分片键
sharding-column: id
# 分片算法
algorithm-expression: sharding_user$->{id%2+1}
访问controller的shardingTest方法。
如果报错
java.lang.NoClassDefFoundError: org/antlr/v4/runtime/CharStreams
添加依赖
<dependency>
<groupId>org.antlr</groupId>
<artifactId>antlr4-runtime</artifactId>
<version>4.9.2</version>
</dependency>
再次访问


可以看到逻辑sql和实际sql都打印出来。数据库也有了数据 到此环境搭建结束,这个也相当于入门案例

案例一:分库分表
该案例将数据根据id分配到不同的数据库和不同的表里面,以两库两表为案例。在入门案例中在本地创建了一个数据库,现在在其他服务器创建另一个数据库,分表还是按照user1、user2来分。
shardingsphere:
props:
# 开启sql打印
sql:
show: true
datasource:
# 配置逻辑库名
names: m1,m2
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/sharding_test?useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&tinyInt1isBit=false&allowMultiQueries=true&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=true
username: root
password: root
m2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://xxx/xmkf_zt?useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&tinyInt1isBit=false&allowMultiQueries=true&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=true&rewriteBatchedStatements=true
username: xxx
password: xxx
sharding:
tables:
# 配置逻辑表名
sharding_user:
actual-data-nodes:
# 逻辑库逻辑表对应真实库、表的关系
m$->{1..2}.sharding_user$->{1..2}
# 配置主键生成策略
key-generator:
column: id
type: SNOWFLAKE
props:
worker:
id: 1
# 分库策略
database-strategy:
inline:
# 分片键
sharding-column: id
# 分片算法
algorithm-expression: m$->{id%2+1}
# 分表策略
table-strategy:
inline:
# 分片键
sharding-column: id
# 分片算法
algorithm-expression: sharding_user$->{(id%4).intdiv(2)+1}
测试代码
@GetMapping("/shardingTest")
@ApiOperation(value = "测试分库分表")
@ApiOperationSupport(order = 9, author = "lsx")
public R shardingTest(String name,Integer age){
List<ShardingUser> list = new ArrayList<>();
for (int i = 0;i<100;i++){
ShardingUser user = new ShardingUser();
user.setUserName(name+i);
user.setAge(i);
list.add(user);
}
shardingUserService.saveBatch(list);
return R.success("成功");
}
说一下算法吧,首先是分库
id%2+1
通过id 取模2 得到 0和1 然后+1 得到 1和2就对应了 m1和m2所在的库
然后分表
(id%4).intdiv(2)+1
。首先通过id取模4 得到 0、1、2、3 这几种可能,然后整除2(默认向下取整)得到 0和1。然后再加上1得到1和2 就对应了表1和表2。
看下查询
@GetMapping("/shardingQuery")
@ApiOperation(value = "测试分库分表查询")
@ApiOperationSupport(order = 10, author = "lsx")
public R shardingQuery(String id){
ShardingUser byId = shardingUserService.getById(Long.valueOf(id));
return R.data(byId);
}
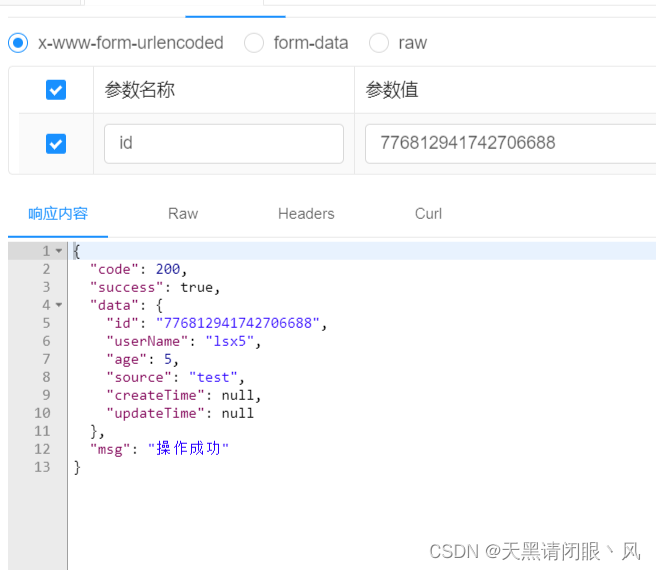

成功查询到数据
要是范围查询呢,
@GetMapping("/shardingQuery")
@ApiOperation(value = "测试分库分表查询")
@ApiOperationSupport(order = 10, author = "lsx")
public R shardingQuery(String id){
QueryWrapper<ShardingUser> query = new QueryWrapper<>();
query.between("id",776812941189058560L,776812941952421888L);
List<ShardingUser> list = shardingUserService.list(query);
return R.data(list);
}
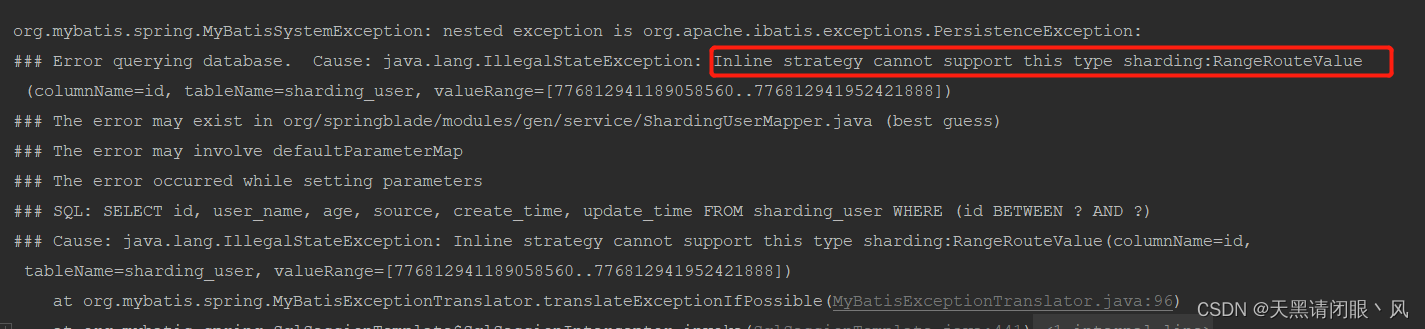
直接报错了,因为配置文件中使用的是
行表达式分片策略
不支持 范围查询,具体来看看官网

所以如果像满足范围查询需要更换分片策略
分片策略介绍
官网分片策略介绍:
https://shardingsphere.apache.org/document/4.1.1/cn/features/sharding/concept/sharding/
以下截取官网


案例二:使用标准分片策略实现范围查询
自定义分库算法
// 精确算法 用于 =和in
public class MyDBPreciseSharding implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
Long id = shardingValue.getValue();
Long db = id % 2 + 1;
String dbIndex = "m"+db;
if(availableTargetNames.contains(dbIndex)){
return dbIndex;
}
throw new UnsupportedOperationException(" route "+dbIndex+" is not supported. please check your config");
}
}
//范围算法 用于 范围查询
public class MyDBRangeSharding implements RangeShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Long> shardingValue) {
Long lower = shardingValue.getValueRange().lowerEndpoint();
Long upper = shardingValue.getValueRange().upperEndpoint();
List<String> dbNames = new ArrayList<>();
availableTargetNames.forEach(s->{
if (s.startsWith("m")) dbNames.add(s);
});
//对于奇偶分离的场景 大概率两个数据库都是要查
return dbNames;
}
}
自定义分表算法
//精确
public class MyTablePreciseSharding implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
Long id = shardingValue.getValue();
Long inddex = (id % 4)/2+1;
String logicTableName = shardingValue.getLogicTableName();
String tabesName = logicTableName + inddex;
if (availableTargetNames.contains(tabesName)) return tabesName;
throw new UnsupportedOperationException(" route "+tabesName+" is not supported. please check your config");
}
}
//范围
public class MyTableRangeSharding implements RangeShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Long> shardingValue) {
Long lower = shardingValue.getValueRange().lowerEndpoint();
Long upper = shardingValue.getValueRange().upperEndpoint();
List<String> tableNames = new ArrayList<>();
availableTargetNames.forEach(s->{
if (s.startsWith(shardingValue.getLogicTableName())) tableNames.add(s);
});
//对于奇偶分离的场景 大概率两个表都要查
return tableNames;
}
}
yml配置
shardingsphere:
props:
# 开启sql打印
sql:
show: true
datasource:
# 配置逻辑库名
names: m1,m2
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/sharding_test?useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&tinyInt1isBit=false&allowMultiQueries=true&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=true
username: root
password: root
m2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://xxx/xmkf_zt?useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&tinyInt1isBit=false&allowMultiQueries=true&serverTimezone=GMT%2B8&allowPublicKeyRetrieval=true&rewriteBatchedStatements=true
username: xxx
password: xxx
sharding:
tables:
# 配置逻辑表名
sharding_user:
actual-data-nodes:
# 逻辑库逻辑表对应真实库、表的关系
m$->{1..2}.sharding_user$->{1..2}
# 配置主键生成策略
key-generator:
column: id
type: SNOWFLAKE
props:
worker:
id: 1
# 分库策略
database-strategy:
standard:
# 分片键
sharding-column: id
# 分片算法
precise-algorithm-class-name: org.spring.common.shardingJDBC.MyDBPreciseSharding
range-algorithm-class-name: org.spring.common.shardingJDBC.MyDBRangeSharding
# 分表策略
table-strategy:
standard:
# 分片键
sharding-column: id
# 分片算法
precise-algorithm-class-name: org.spring.common.shardingJDBC.MyTablePreciseSharding
range-algorithm-class-name: org.spring.common.shardingJDBC.MyTableRangeSharding
执行之前的范围查询


然后把查到的数据汇总返回。

到此分库分表入门案例结束了,下一篇继续实战剩下的分片策略和进阶用法