1.配置步骤
1. 安装JDK
2. 关闭防火墙
3. 修改主机名。Hadoop要求主机名中不能出现 – 或者_ 等特殊字符
vim /etc/sysconfig/network
修改HOSTNAME,例如
HOSTNAME=hadoop01
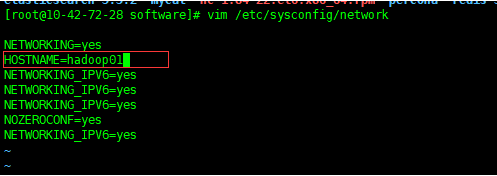
保存退出,然后重新生效
source /etc/sysconfig/network
4. 需要将主机名和IP进行映射
vim /etc/hosts
将之前的内容全部删除

添加IP 主机名映射,例如
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.9.162.133 hadoop01

保存退出
5. 重启
reboot
重启后之前的是ip为名称的主机名已经被修改,因为hadoop的主机名称不能有下划线,横线等,此时登录可以看到已经修改的主机名称
![]()
6. 配置免密互通
在上面第五步骤重启后在默认的路径下执行下面语句
ssh-keygen —然后一路回车

上面回车完成后 执行下面语句 @后面跟的是主机名称,表示将对hadoop01免密,将公钥拷给hadoop01
ssh-copy-id root@hadoop01
然后输入密码


***** 如果出现Name or Service not known,检查hosts文件是否正确
设置免密完成后输入如下命令,查看是否需要密码,如果不需要,则说明免密成功
ssh hadoop01

7. 进入software目录
cd /home/software/
8. 下载Hadoop安装包
wget http://bj-yzjd.ufile.cn-north-02.ucloud.cn/hadoop-2.7.1_64bit.tar.gz
9. 解压
tar -xvf hadoop-2.7.1_64bit.tar.gz
10. 进入子目录
hadoop-2.7.1/etc/hadoop

11. 编辑
vim hadoop-env.sh
修改
export JAVA_HOME=/home/presoftware/jdk1.8 export HADOOP_CONF_DIR=/home/software/hadoop-2.7.1/etc/hadoop
分别为JDK和Hadoop的安装目录

保存退出,然后重新生效
source hadoop-env.sh
12. 编辑
vim core-site.xml
添加
<property> <name>fs.defaultFS</name> <value>hdfs://hadoop01:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/software/hadoop-2.7.1/tmp</value> </property>

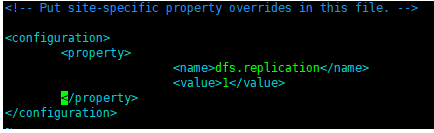
13. 编辑
vim hdfs-site.xml
添加
<property> <name>dfs.replication</name> <value>1</value> </property>
14. 复制
cp mapred-site.xml.template mapred-site.xml

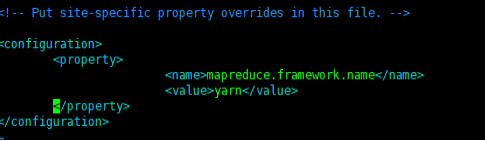
编辑
vim mapred-site.xml
添加
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
15. 编辑
vim yarn-site.xml
添加
<property> <name>yarn.resourcemanager.hostname</name> <value>hadoop01</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>

16. 编辑
vim slaves
添加第一台云主机的主机名
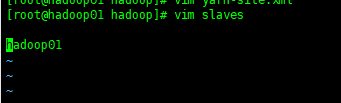
17. 配置环境变量
vim /etc/profile
在文件末尾添加
export HADOOP_HOME=/home/software/hadoop-2.7.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

保存退出,然后重新生效
source /etc/profile
18. 在第一次启动Hadoop之前需要格式化
hadoop namenode -format
如果出现Storage directory /home/software/hadoop-2.7.1/tmp/dfs/name has been successfully formatted.表示格式化成功
*** 如果格式化失败,修改完错误之后,删除/home/software/hadoop-2.7.1/tmp目录,修改错误之后再重新格式化

19. 启动Hadoop
start-all.sh
注:如果设置有密码,那么需要输入密码多次逐个登录
20. 通过jps查看
Jps
NameNode
DataNode
SecondaryNameNode
ResourceManager
NodeManager
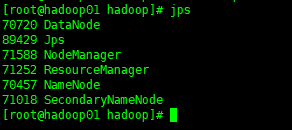
启动成功,输入对应的ip+端口可以通过前端访问不同节点
nameDode

DataNode

SecondaryNameNode

ResourceManager
![]()