C++简单词法分析器
注:需在txt文件中以’#’键结尾。代码已在vs2019中运行成功。
#include <iostream>
#include <fstream>
#include <cstring>
using namespace std;
#define max 1000
char ch;//用于取单个字符
char token[max][100];//存放字符
int ptoken = 0;
//关键字
const char* pkeyword[] = { "if", "else", "while", "int", "main", "switch", "case", "return",
"break","char","const","default","do","double","for","float",
"static","struct","switch","void" };
//识别字母
int letter()
{
if (ch >= 'a' && ch <= 'z' || ch >= 'A' && ch <= 'Z')
return 1;
else
return 0;
}
//识别数字
int digit()
{
if (ch >= '0' && ch <= '9')
return 1;
else
return 0;
}
//识别关键字
int reserve()
{
for (int i = 0; i < 20; i++)
{
if (strcmp(token[ptoken], pkeyword[i]) == 0)
return i;
}
return 20;
}
void scanning(ifstream* pfile)
{
pfile->get(ch);
while (1)
{
//识别关键字和标识符
if (letter())
{
int i = 0;
token[ptoken][i] = ch;
while (pfile->get(ch) && (letter() || digit()))//识别字母和数字
{
i++;
token[ptoken][i] = ch;
}
int check = reserve();//识别关键字
if (check < 20)
cout << pkeyword[check] << "\t" << "关键字" << endl;
else
cout << token[ptoken] << "\t" << "标识符" << endl;
ptoken++;//为下一次识别准备
}
//识别数字
else if (digit())
{
int i = 0;
token[ptoken][i] = ch;
pfile->get(ch);
while (digit())
{
i++;
token[ptoken][i] = ch;
pfile->get(ch);
}
cout << token[ptoken] << "\t" << "数字" << endl;
ptoken++;
}
//过滤注释
else if (ch == '/')
{
token[ptoken][0] = ch;
pfile->get(ch);
if (ch == '/')
{
token[ptoken][1] = ch;
cout << token[ptoken] << "\t" << "注释" << endl;
while (pfile->get(ch) && ch != '\n') {}//过滤掉'//'之后一行的字符
}
/*if (ch == '*')
{
token[ptoken][1] == ch;
cout << token[ptoken] << "\t" << "注释" << endl;
pfile->get(ch);
ptoken++;
if (ch == '*')
{
token[ptoken][0] = ch;
pfile->get(ch);
if (ch == '/')
{
token[ptoken][1] = ch;
cout<<token[ptoken] << "\t" << "注释" << endl;
}
}
}*/
else
{
cout << token[ptoken] << "\t" << "运算符" << endl;
}
ptoken++;
}
//过滤空格、换行符、制表符
else if (ch == ' ' || ch == '\n' || ch == '\t')
pfile->get(ch);
//结束
else if (ch == '#')
break;
//特殊字符
else
{
switch (ch)
{
case '+':
token[ptoken][0] = ch;
cout << token[ptoken] << "\t" << "运算符" << endl;
ptoken++;
pfile->get(ch);
break;
case '-':
token[ptoken][0] = ch;
cout << token[ptoken] << "\t" << "运算符" << endl;
ptoken++;
pfile->get(ch);
break;
case '*':
token[ptoken][0] = ch;
cout << token[ptoken] << "\t" << "运算符" << endl;
ptoken++;
pfile->get(ch);
break;
case '=':
token[ptoken][0] = ch;
cout << token[ptoken] << "\t" << "运算符" << endl;
ptoken++;
pfile->get(ch);
break;
case '(':
token[ptoken][0] = ch;
cout << token[ptoken] << "\t" << "界符" << endl;
ptoken++;
pfile->get(ch);
break;
case ')':
token[ptoken][0] = ch;
cout << token[ptoken] << "\t" << "界符" << endl;
ptoken++;
pfile->get(ch);
break;
case '{':
token[ptoken][0] = ch;
cout << token[ptoken] << "\t" << "界符" << endl;
ptoken++;
pfile->get(ch);
break;
case '}':
token[ptoken][0] = ch;
cout << token[ptoken] << "\t" << "界符" << endl;
ptoken++;
pfile->get(ch);
break;
case '[':
token[ptoken][0] = ch;
cout << token[ptoken] << "\t" << "界符" << endl;
ptoken++;
pfile->get(ch);
break;
case ']':
token[ptoken][0] = ch;
cout << token[ptoken] << "\t" << "界符" << endl;
ptoken++;
pfile->get(ch);
break;
case ':':
token[ptoken][0] = ch;
cout << token[ptoken] << "\t" << "界符" << endl;
ptoken++;
pfile->get(ch);
break;
case '.':
token[ptoken][0] = ch;
cout << token[ptoken] << "\t" << "界符" << endl;
ptoken++;
pfile->get(ch);
break;
case '\\':
token[ptoken][0] = ch;
pfile->get(ch);
if (ch == '\\')
{
token[ptoken][1] = ch;
cout << token[ptoken] << "\t" << "界符" << endl;
pfile->get(ch);
}
else {
cout << token[ptoken] << "\t" << "界符" << endl;
}
ptoken++;
break;
case '"':
token[ptoken][0] = ch;
cout << token[ptoken] << "\t" << "界符" << endl;
ptoken++;
pfile->get(ch);
break;
case '\'':
token[ptoken][0] = ch;
cout << token[ptoken] << "\t" << "界符" << endl;
ptoken++;
pfile->get(ch);
break;
case ';':
token[ptoken][0] = ch;
cout << token[ptoken] << "\t" << "界符" << endl;
ptoken++;
pfile->get(ch);
break;
case '!':
token[ptoken][0] = ch;
cout << token[ptoken] << "\t" << "界符" << endl;
ptoken++;
pfile->get(ch);
break;
case ',':
token[ptoken][0] = ch;
cout << token[ptoken] << "\t" << "界符" << endl;
ptoken++;
pfile->get(ch);
break;
case '&':
token[ptoken][0] = ch;
pfile->get(ch);
if (ch == '&')
{
token[ptoken][1] = ch;
cout << token[ptoken] << "\t" << "运算符" << endl;
pfile->get(ch);
}
else
cout << token[ptoken] << "\t" << "运算符" << endl;
ptoken++;
break;
case '<':
token[ptoken][0] = ch;
pfile->get(ch);
if (ch == '=')
{
token[ptoken][1] = ch;
cout << token[ptoken] << "\t" << "运算符" << endl;
pfile->get(ch);
}
if (ch == '<')
{
token[ptoken][1] = ch;
cout << token[ptoken] << "\t" << "运算符" << endl;
pfile->get(ch);
}
else
cout << token[ptoken] << "\t" << "运算符" << endl;
ptoken++;
break;
case '>':
token[ptoken][0] = ch;
pfile->get(ch);
if (ch == '=')
{
token[ptoken][1] = ch;
cout << token[ptoken] << "\t" << "运算符" << endl;
pfile->get(ch);
}
else
cout << token[ptoken] << "\t" << "运算符" << endl;
ptoken++;
break;
default:
// cout << "暂时无法识别:" << "\t" << ch << endl;
pfile->get(ch);
break;
}
}
}
}
int main()
{
ifstream infile("F:\\test.txt", ios::in);
if (!infile)
{
cout << "file could not be open" << endl;
return 0;
}
cout<< "单词"<<'\t'<< "类别" << endl;
scanning(&infile);
infile.close();
return 1;
}
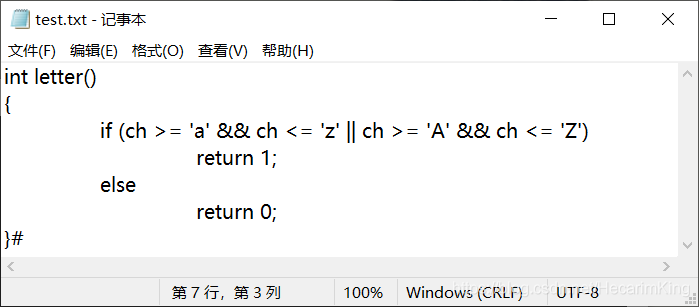
txt文件举例:
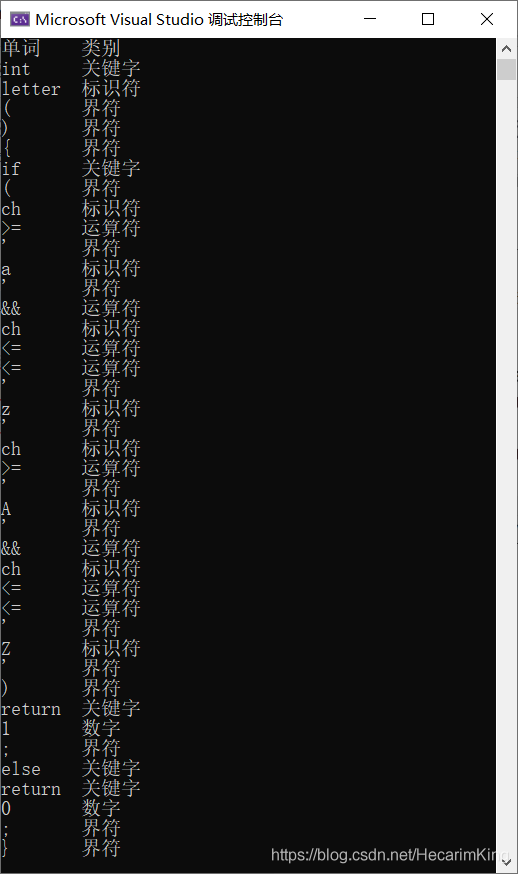
运行结果:
版权声明:本文为HecarimKing原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。