Abstract
我们将车道检测过程视为一个使用全局特征的锚定驱动的有序分类问题。
首先,我们在一系列混合(行和列)锚点上用稀疏坐标表示车道。在锚驱动表示的帮助下,我们将车道检测任务重新表述为一个有序分类问题,以得到车道的坐标。我们的方法可以显著降低锚点驱动表示的计算成本。
I
NTRODUCTION

一个车道可以用一系列预定义的行锚点上的坐标来表示
其次,我们建议使用一种基于分类的方式来学习具有锚定驱动表示的车道坐标

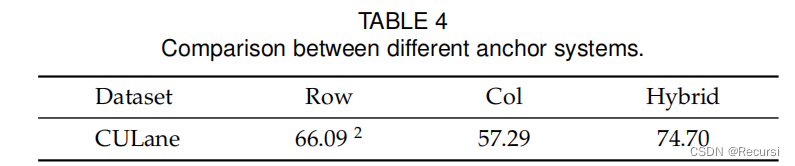
行锚难以定位水平车道(侧车道),同样也使列锚难以定位垂直车道,根据上述观察结果,我们建议使用混合(行和列)锚点来分别表示不同的车道。具体来说,我们对中间车道使用行锚,对侧车道使用列锚。这样就可以缓解放大的定位误差问题,提高性能。
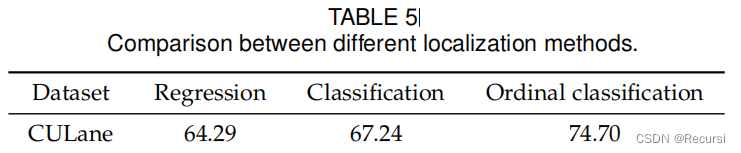
在这项工作中,我们进一步扩展了原始的分类到顺序分类。在有序分类中,相邻的类具有密切的有序关系,这与原始分类不同。在我们的工作中,类是有序的(例如,第8类的车道坐标总是在空间上在第7类的车道坐标的右边)。有序分类的另一个性质是类的空间是连续的。例如,像第7.5类这样的非整数类是有意义的,它可以被看作是介于第7类和第8类之间的中间类。
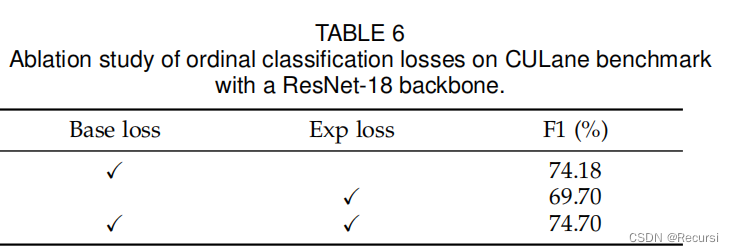
提出了两个损失函数来建模类之间的序数关系,包括基分类损失和数学期望损失
contributions
1)我们提出了一种新的、简单的、有效的车道检测公式。与以往的方法相比,我们的方法将车道表示为基于锚定
的坐标,并以基于分类的方式学习坐标。该公式在解决无视觉线索问题时非常快速和有效。
2)在此基础的基础上,提出了一种混合锚系统,进一步扩展了之前的行锚系统,有效地减少了定位误差。此外,基于分类的学习进一步扩展到有序分类问题,利用基于分类定位中的自然顺序关系。
3)所提出的方法达到了最先进的速度和性能。
Compare
1)通过对放大误差问题的观察,我们提出了一种新的混合锚定系统,与之前相比,可以有效地减少定位误差。
2)我们提出了一种新的损失函数,它将车道定位视为一个序数分类问题,从而进一步提高了其性能。
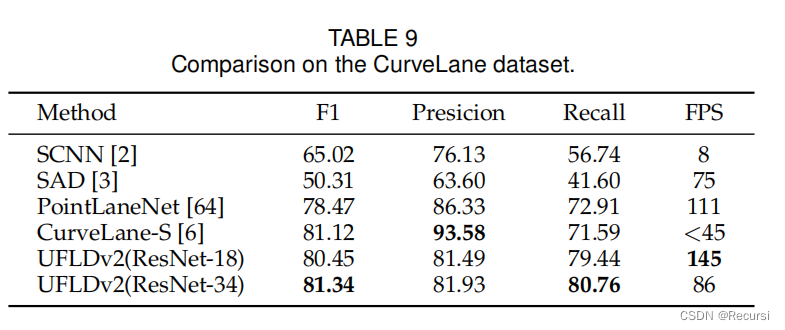
3)演示和实验论文的大部分内容都被重写,以提供更清晰的演示和插图。我们提供了更多的分析、可视化和结果,以更好地覆盖我们的工作空间。在这个版本中也提供了在相同速度下性能提高6.3点的更强的结果。
3 U
LTRA
F
AST
L
ANE
D
ETECTION
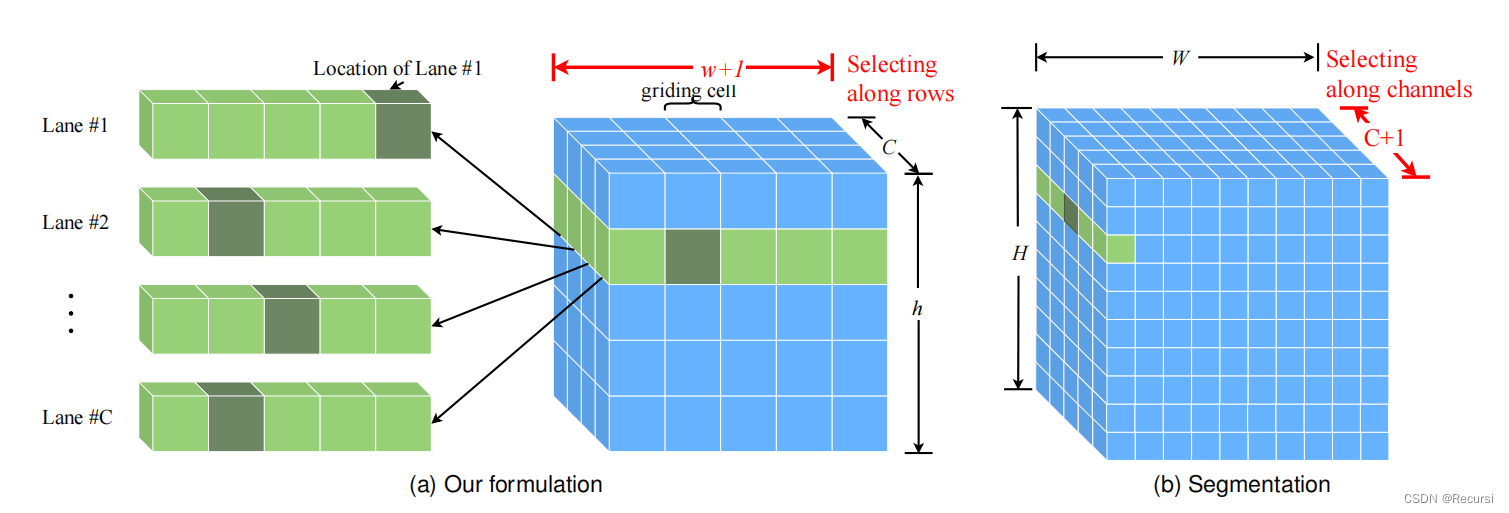
3.1 Lane Representation with Anchors

如图3所示。车道用行锚点上的点表示。然而,行锚定系统可能会导致一个放大的定位错误问题

假设没有任何锚定系统的理想最小定位误差是ε,这可能是由网络偏差、注释错误等引起的
当车道与锚点之间的夹角θ很小时,放大因子将趋于无穷大
例如,当车道严格水平时,不可能用行锚系统来表示车道。这个问题使得行锚很难定位更水平的车道(通常是侧
车道),同样,列锚很难定位更垂直的车道。
相反,当车道和锚点是垂直的时,锚点系统引入的误差最小的,它等于理想的定位误差ε。
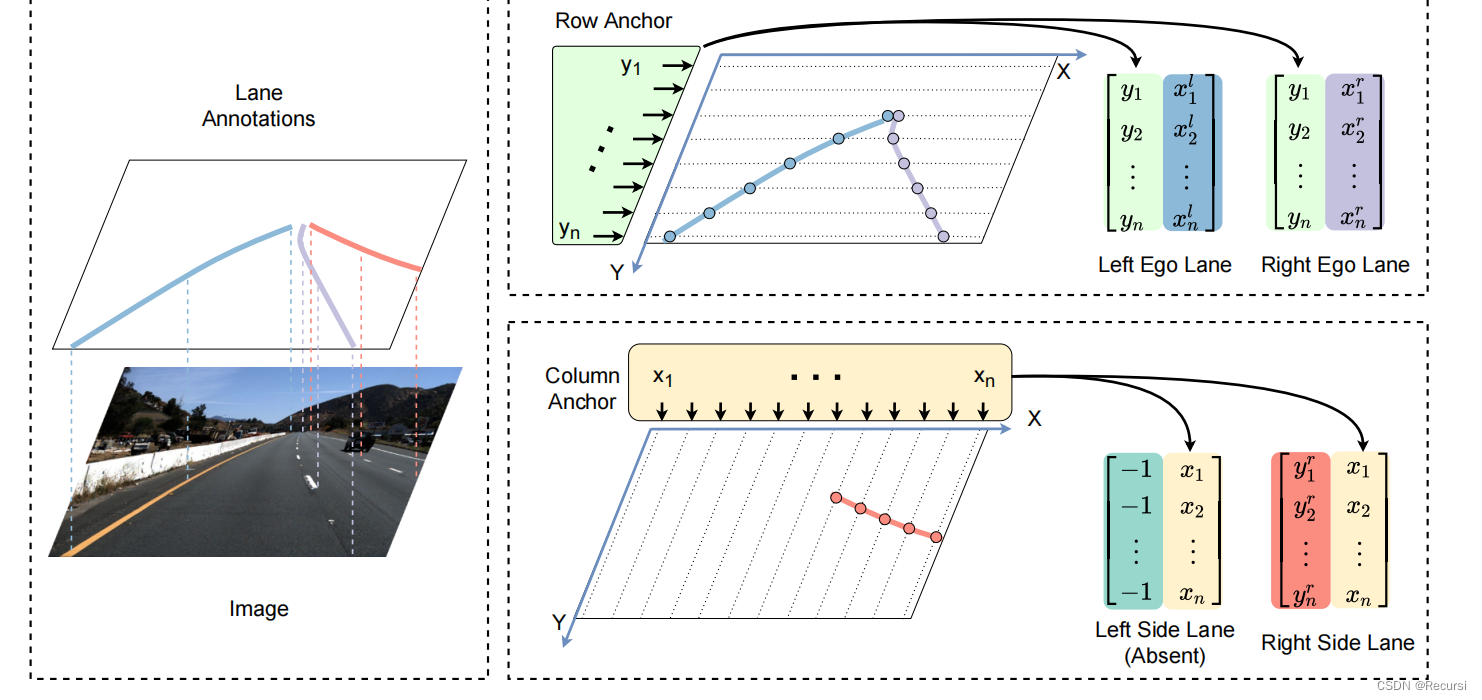
用Nrow表示行锚的数量,用Ncol表示列锚的数量。对于每个车道,我们首先分配相应的锚定系统,该系统的定位
误差最小。
记下交点坐标。如果车道在某些锚点之间没有交点,则坐标将被设置为-1
3.2 Anchor-driven Network Design
假设Tr和Tc是归一化的(Tr和Tc的元素范围从0到1或等于-1,即“无车道”的情况)
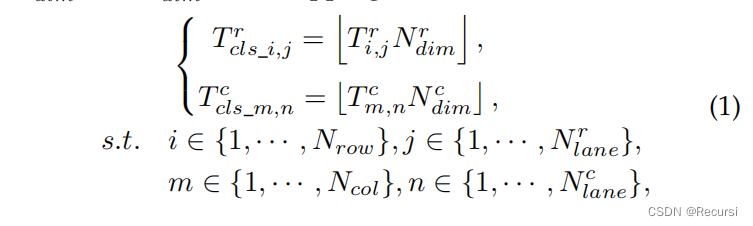

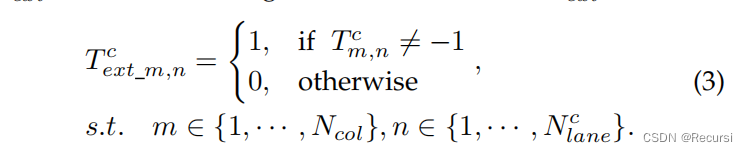
整个网络将学习具有两个分支的Tr cls、Tc cls、Tr ext和Tc ext,它们分别是定位分支和存在分支。假设一个输入图像的深度特征为X,则该网络可以写为:
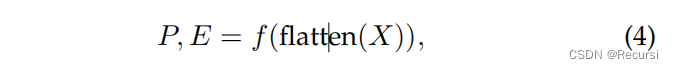
3.3 Ordinal Classifification Losses
基础分类损失



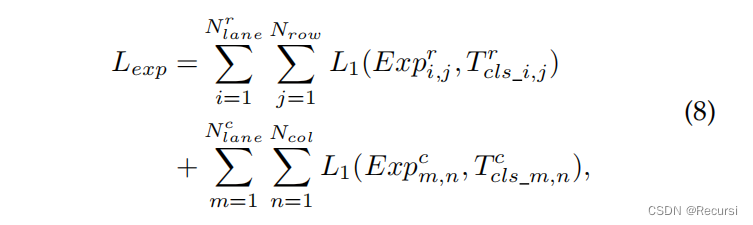

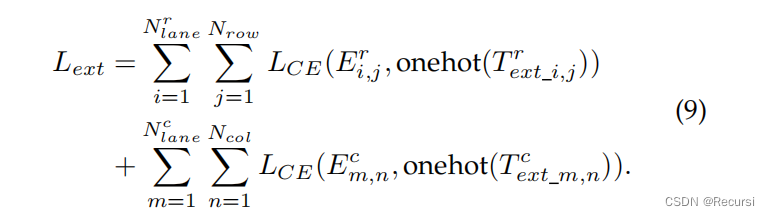
3.4 Network Inference
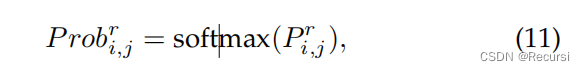
根据存在分支的预测,过滤掉缺失车道的预测:

3.5 Analysis and Discussion
4 E
XPERIMENTS
4.2 Ablation Study
4.2.1 Effectiveness of the Hybrid Anchor System
4.2.2 Effectiveness of the Ordinal Classifification
对于回归方法,我们用一个类似的回归头替换我们的管道中的分类器头。训练的损失被平滑的L1的损失所取代。
分类设置只使用交叉熵损失,而顺序分类设置使用所有的三个损失,如在等式中10
4.2.3 Ablation of the Ordinal Classifification Losses
4.2.4 Effects of the Classifification Dimensions

我们可以看到,随着分类维度的增加,性能先提高后下降。维度越小,分类本身就更容易,但每个类代表更大范围的位置,即每个类的定位能力都较差。对于一个更大的维度,每个类代表一个更窄的位置范围(每个类的定位能力更好),但分类本身比较困难。最终的性能是在分类的难度和每个类的定位能力之间的权衡。所以我们把
Nc设为100,Nr设为200。
4.2.5 Effects of the Number of Anchors
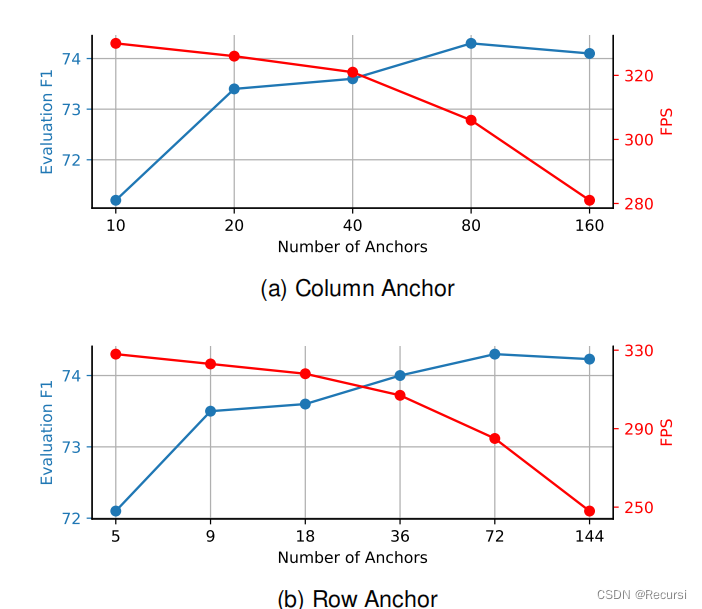
我们可以看到,随着行锚点数量的增加,性能也会普遍提高。但检测速度也会逐渐下降

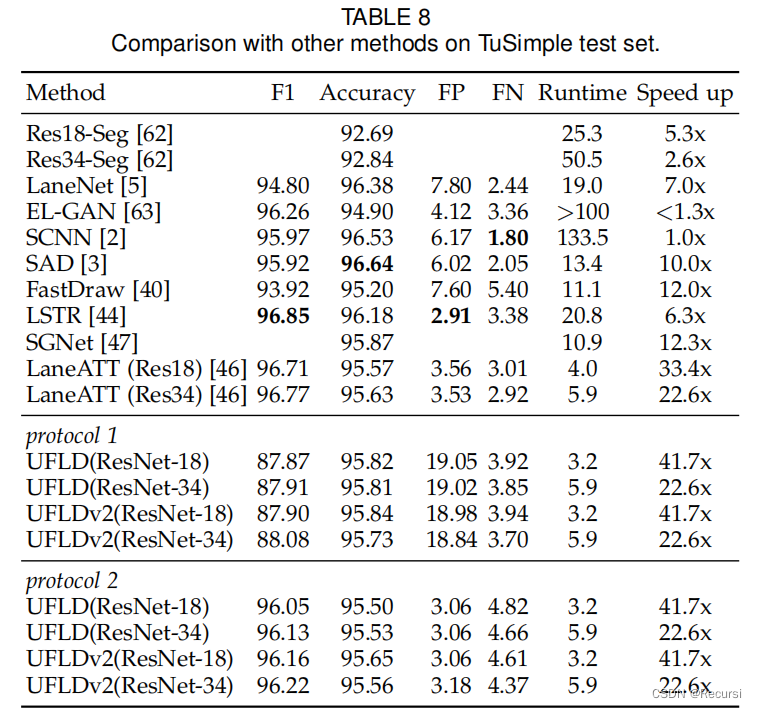
为了验证我们的方法,我们使用了两个协议。协议1输出的所有车道和缺失的车道都用充满无效的车道表示,这
与会议版本相同。协议2直接丢弃缺席的车道。结果如表8所示。