参考文章
:
深入浅出Yolo系列之Yolov5核心基础知识完整讲解 – 江大白*
参考视频教程
:
目标检测基础——YOLO系列模型(理论和代码复现)– PULSE_
0.V4 & V5
yolo v5和v4前后推出只有两个月,其实V5和V4都是V3推出后,根据V3的改进。因此严格来说算是两个版本的V4,两者的大体思路都比较相似,不同的地方主要是细节地方对于前沿技术的使用,各有其优点。V4的优点在于准确性更高。V5的优点是有四种深度宽度的模型,可以根据要检测的物体大小,项目量级来选择不同的模型,灵活性更高。
V4学习笔记
YOLO V5主要改进(对比V3)

(1) 输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放
(2) Backbone : Focus结构、CPS结构
(3) Neck : FPN + PAN结构
(4) Prediction : GIOU_LOSS
1.输入端改进
(1) 自适应锚框计算
YOLO V3和V4中的锚点框大小都是预先通过聚类算法计算的,在单独的程序中运行。
V5的创新在于,将锚框的计算嵌入到训练中:在训练中,在初试设定好的锚框的基础上输出预测框,然后和Ground-truth进行对比计算Loss,再进行更新,从而不断更新锚点框大小。通过这种方法,V5可以在不同训练集中通过自适应的计算出最佳的锚框值。
(2) 自适应图片缩放
YOLO以前版本使用的图片长宽比通常都是1:1,而在实际检测项目中,很多图片的长宽比不同。如果强行填充为1:1,那么像以下的长方形图片,上下方都要填充比较多的黑边。这样会存在信息冗余问题,从而影响推理速度。

V5针对该问题进行了改进。具体操作如下:
计算缩放比例

获得长宽不同的缩放比例后,选取比较小的缩放系数(上图的0.52),然后将原图的长宽都乘以该系数。

填充黑边
为了保证长宽边都是32的倍数(YOLO 5次下采样,32倍缩小),因此要对较短的边进行填充,具体操作如下所示:

通过这种思路,可以大大减少图片缩放后要填充的黑边。在推理时,计算量大大减少、即目标检测速度会得到提升。(缩减黑边通常用在
测试即模型推理
的时候,因为其作用也是提升推理速度。在训练时还是采用传统填充的方式)
2.Backbone改进
(1) Focus结构

看结构有点像YOLO V2中提到的 passthrough 操作。假设输入图片为608x608x3,则通过切片操作,可以变成304x304x12的特征图。Foucus结构中,还在最后加了一个卷积核,以5S(上图)为例,最后会变成304x304x32的特征图。
通过这种切片结构,可以保留更多的细粒度特征
(2) CSP结构
YOLO V5的CSP结构和V4有所不同,V4的CSP结构只应用于backbone区域。V5则是设计了两种CSP结构,如下图所示。

CSP1_x主要应用于Backbone主干网络,结构和V4类似。CSP2_X则应用于Neck模块中,没有残差组件。
3.Neck改进
YOLO V5学习了V4的思路,也是使用了将强语义特征和强定位特征融合的FPN+PAN结构。

主要的不同是,采用了上篇提到的CSP_2X代替了V4的普通卷积结构,加强了网络特征融合的能力。

4.输出端
(1) GIOU_LOSS损失函数
YOLO V5使用了之前V4中提到的GIOU_LOSS,主要解决了预测框和目标框无法判断相交方向和是否相交的问题

但是与V4相比不足的就是,包裹问题和长宽比问题无法解决
其次就是V5对于框重合度的筛选还是使用了之前的nms方式,相比于V4的DIOU_LOSS,对于实际测试框重合度的筛选能力稍弱。

因此,可以在V5的基础上吸收V4的缺点,引入CIOU_loss+DIOU_nms的结构,可以将重叠的目标分割出来,不过也会相应的增加一些计算成本。
5.YOLO V5四种结构

(depth_multiple控制网络的深度,width_multiple控制网络的宽度)

如上图所示,四种不同结构的BackBone和Neck深度和宽度都各有不同,其中以5S最浅(窄)到5X最深(宽)。YOLO V5中,网络不断加深,网络特征提取和特征融合的能力也原来越强,因此计算量也越来越大(可以按需选择不同型号)
(1)深度控制
以上图为例,第一个CSP1中,5S使用了1个残差组件(CSP1_1),5m则使用了两个残差组件(CSP1_2),往后以此类推。
第一个CSP2结构中,5时使用了2×1(X)=2组卷积(CSP2_1),5m则使用了2×2=4组卷积(CSP2_2)。
如何控制深度?
控制深度结构的核心代码在yolo.py中,通过n和gd(height_multiple)两个参数控制网络的变化
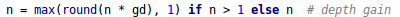

以CSP1为例,yolov5s的height_multiole=0.33,即gd=0.33,n则是由上面的红色框中获得。在上述代码中,n为框中的第二个数值3。
代入上述代码,可以算出max(0.33×3,1) = 1,因此就可以算出只有一个残差组件,即CSP1_1。
第二个CSP1结构也是同理,n=9,max(0.33×9,1)=3,因此V5S的第二个CSP1组件中由3个残差组件(CSP1_3)
yolov5l原理也是一样,其height_multiple=1,gd=1。因此第一个CSP1结构中,n=3,max(3×1,1) = 3,所以第一个CSP结构为CSP1_3。
(2)宽度控制

宽度其实就是每一层中卷积核的数量(厚度)–特征图的第三维度(13x13x
32
)

以Yolov5s为例,第一个Focus结构中,最后卷积时,卷积核数量为32个,因此经过Focus结构后,特征图的大小变成304x304x32.V5m的Focus结构中用了48个卷积核,最后特征图变成了304x304x48,其他也是同理。
第二个卷积操作也是同理,卷积核中用了不同数量的卷积核(不同的宽度),所以特征图数量也不一样。
卷积核的数量越多,特征图的宽度越宽,网络提取特征的学习能力也越强,当然计算量也越来越大。
如何控制宽度
?
控制宽度的代码同样在yolo.py中
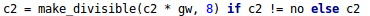

其中gw就等于上面设置的width_multiple参数

以yolov5s为例,width_multipl = gw = 0.5,C2就是上图框出的数字
在Focus结构中,标准的c2=64,gw=0.5,代入公式计算,最后的结果=32,所以在V5s的Focus结构中,卷积下采样操作的卷积核为32个。
第二个卷积层也是一样,128×0.5=64,结果正确。
其他层的计算原理以此类推。
总结
YOLO V5是在V3基础上的一次改进,和YOLO V4相比,在灵活性上有很大优势,对于不同项目选择不同的模型,有利于资源的合理利用。V4的优势则在于准确性。