
模块的概念
•模块是一个保存了Python代码的文件,其中可以包含变量、函数或类的定义,也可以包含其他各种Python语句。使用模块有以下3方面的优势。
•(1)模块提高了代码的可维护性。在程序开发过程中,随着程序功能的增多,在一个文件中的代码会越来越长,从而造成程序不易维护,此时可以把相关功能的代码分配到一个模块里,从而使代码更易懂、更易维护。
•(2)模块提高了代码的可重用性。在应用程序开发中,经常需要处理时间,此时不必在每个程序中写入时间的处理函数,只需导入time模块即可。
•(3)模块避免了函数名和变量名冲突。由于相同名字的函数和变量可以分别存在于不同模块中,在编写模块时,不必考虑名字会与其他模块冲突(此处不考虑导包情况)。
•在Python中,模块可以分为3类,具体如下所示:
•内置标准模块(标准库)——Python自带的模块,如sys、os等。
•自定义模块——用户为了实现某个功能自己编写的模块。
•第三方模块——其他人已经编写好的模块。
一个Python程序可由若干模块构成,一个模块中可以使用其他模块的变量、函数和类等,如图所示
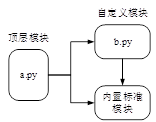
•在图中, a.py是一个顶层模块(又称主模块),其中使用了自定义模块b.py和内置标准模块,b.py也使用了内置标准模块。
2.如何使用模块?
想要使用模块,必须先要将模块加载进来,可以通过关键字 import 或 from进行加载;需要注意的是模块和当前文件在不同的命名空间中。
1)模块的构成:
模块可以包含可执行的语句和函数的定义,这些语句的目的是初始化模块,它们只在模块名第一次遇到导入import语句时才执行(import语句是可以在程序中的任意位置使用的,且针对同一个模块很import多次,为了防止你重复导入,python的优化手段是:
第一次导入后就将模块名加载到内存了,后续的import语句仅是对已经加载大内存中的模块对象增加了一次引用,不会重新执行模块内的语句
)
我们先自定义一个模块 名为mod.py;
print("hello world")
name = "zjk"
def func1():
print("zjk1")
def func2():
prpint("zjk2")
func1()
def func3():
print("zjk3")
func2()
#然后我们使用里一个py文件进行导入这个模块;
import mod
import mod
import mod
import mod
import mod
-----------------------------打印输出------------------------------------------
hello world
#可以发现只打印了一次,是因为每次导入模块时,解释器都回去检查一下这个模块有没有之前被导过。
2)模块导入的过程:
A.找到这个需导入的模块;
B.判断这个模块是否被导入过;
如果没有被导入过:
创建一个属于这个模块的命名空间;如果用户没有定义变量来引用这个模块的内存地址的话,那么就使用模块的名称来引用这个模块的内存地址;如果用户使用as来指定变量接受这个内存地址的话,那么就将内存地址赋值给这个变量;且下文在调用时只能使用这个变量进行调用不能再使用模块名进行调用了。然后执行这个模块中的代码;
如果该模块已经被导入过:
那么解释器不会重新执行模块内的语句,后续的import语句仅仅是对已经加载到内存中的模块的对象增加一次引用;
3)关于导入的模块与当前空间的关系
带入的模块会重新开辟一块独立的名称空间,定义在这个模块中的函数把这个模块的命名空间当做全局命名空间,这样的话当前的空间就和模块运行的空间分隔了,谁也不影响谁;
4)为模块起别名
模块在导入的时候开辟了新空间内存,默认是使用模块的名称来引用这个内存地址的,有时候模块的名称很长再加上执行调用里面的功能的时候,就显的很不方便,为了更好的使用模块,我们可以给模块起别名;
也就是在导入模块的时候我们不让它使用默认的名字来引用内存地址,而是由我们自己定义的变量来引用这个模块的内存地址;
方法:import my_module as mk
这样的话就表示使用变量mk来引用这个内存地址,然后我们在文中再使用这个模块的时候,只要使用mk来调用这个模块里的功能即可。
还有一种好处是当有两个模块需要根据用户的输入来选择使用的话,那么,用自定义变量来引用内存地址就再好不过了,例如:
复制代码
#例如:join和pickle都有dump和dumps方法,根据用户的输入进行选择使用哪一种
#第一种,不使用别名方式,使用默认的以模块名引用的方式;
def func(dic,t = 'json'):
if t == 'json':
import json
return json.dumps(dic)
elif t == 'pickle':
import pickle
return pickle.dumps(dic)
#第二种,使用别名方式引用的内存地址;
def func(dic, t='json'):
if t == 'json':
import json as aaa
elif t == 'pickle':
import pickle as aaa
return aaa.dumps(dic)
#可以看出使用别名的方式还是更好一些;
别名的好处
5)导入多个模块
方法一:import os,time,sys,re 等等,每个模块之间用逗号隔开;
方法二:import os
import time
import sys
方法二的好处就是当我们暂时不用某个模块时直接注释了就行,而方法一就得把那个模块删除;
多个模块导入时的顺序:
规范建议:模块应该一个一个的导入,先后顺序为:内置模块—->扩展(第三方)模块——>自定义模块;
顺序说明:我们知道导入模块其实就是在执行这个模块,我们不确定扩展模块或自定义模块里有没有某个功能调用了内置模块,所以,我们在导入模块时,应先导入解释器内置的模块,然后在导入扩展模块,最后导入自定义模块。
小结:
第一次导入后就将模块名加载到内存了,后续的import语句仅是对已经加载大内存中的模块对象增加了一次引用,不会重新执行模块内的语句;导入模块其实就是在执行py文件;开辟一块新内容,将内容加载到内存中;
3. from…..import
我们在使用一个模块时可能只想使用其中的某些功能,比如只想使用sys模块中的modules时,那么import就不好用了,这时我们可以使用from…..import这样的格式来进行模块的某个功能的导入。
注意:这时模块是已经全部加载了,但只是为这个功能进行了引用,其他的功能并没有引用,所以在使用模块的时候,就只能使用这个模块的这个功能,其他的功能不能使用,如果想再使用这个模块的另一个功能时,可以在进行一次模块的要使用的功能的导入,这时模块不会再进行加载了,而是只对该功能进行引用,这样我们就可以使用这个功能了。
注意:导入某个功能时也可以为其进行变量引用。
#先看一下import能不能只导入模块的某功能;
import sys.module
--------------------------打印输出-----------------------------------------------
Traceback (most recent call last):
File "E:/python/zjk/模块和包/模块和包.py", line 1, in <module>
import sys.module
ModuleNotFoundError: No module named 'sys.module'; 'sys' is not a package
#报错告诉我们,没有这个模块,sys不是一个包,啥意思??这个问题我们稍后会在文中说明,为什么这样不支持,包又是个啥。
#看一下from.....import 的使用
from sys import modules
print(modules)
-----------------------------打印输出--------------------------------------------
{'builtins': <module 'builtins' (built-in)>, 'sys': <module 'sys' (built-in)>,
#可以看出成功输出,没有报错。
#再看一下使用as引用这个模块的某个功能;
from sys import modules as m
print(m)
------------------------------打印输出---------------------------------------
{'builtins': <module 'builtins' (built-in)>, 'sys': <module 'sys' (built-in)>, '_frozen_importlib': <module '_froze
#这样也是可以的强调一下python中的变量赋值都是对内存地址的引用,是一种绑定关系,因为我们操作的时候不可能直接拿内存地址来进行操作,所以就将内存地址和变量进行绑定,执行这个变量就相当于执行了这个内存地址中的内存;
from…..import 也支持as模式,
这个我们在上个例子里也说过了,这里就不再重复了;
from…..import 也支持导入某个模块的多个功能
;如:
from os import (listdir,getcwd)
#后面的扩号可加可不加,需要注意的是,这是向要导入下一个模块就得另起一行了,不能在当前行导入;
from…..import *
* 表示导入模块中所有的不是以下划线(_)开头的名字都导入到当前位置,大部分情况下我们的python程序不应该使用这种导入方式,因为*你不知道你导入什么名字,很有可能会覆盖掉你之前已经定义的名字。而且可读性极其的差,在交互式环境中导入时没有问题。
还有一点要说的是,如果使用* 的方式进行了导入,这时只想使用里面的某个或某些功能时,可以使用__all__来进行约束;
注意:__all__只是用来约束*方式的,其他方式导入的话,不会生效;具体使用见例子:
#首先我们看一下不约束时使用*的方式进行模块导入;
#准备了一个自定义模块 mod.py
print("hello world")
name = "zjk"
def func1():
print("zjk1")
def func2():
print("zjk2")
func1()
def func3():
print("zjk3")
func2()
#在当前py中导入mod模块;
from mod import *
print(name)
func1()
func2()
func3()
#调用mod模块里的功能;
------------------------------------------------打印输出---------------------
hello world
zjk
zjk1
zjk2
zjk1
zjk3
zjk2
zjk1
#可以看到,所有的功能和名字都可以被调用;
#那么我们现在对其进行约束一下,要求只能使用fun3()功能;
#我们在mod模块开头加入一下
__all__ = ["func3"]
print("hello world")
name = "zjk"
def func1():
print("zjk1")
def func2():
print("zjk2")
func1()
def func3():
print("zjk3")
func2()
#我们再次在当前py中进行调用;
from mod import *
func3()
print(name)
func1()
func2()
-----------------输出结果---------------------------------------------------
hello world
zjk3
zjk2
zjk1
Traceback (most recent call last):
File "E:/python/zjk/模块和包/模块和包.py", line 3, in <module>
print(name)
NameError: name 'name' is not defined
#可以看到只有func3执行成功了;为什么我要将func3放在最开头呢?你知道了吗?
from import * 例子
小案例
•大家在使用手机QQ进行群聊时,经常会有小伙伴发红包,如图所示。
•发红包模块需具备以下3点要求:
•设定红包金额与数量。
•金额数最大的为运气王。
•随机分配金额。
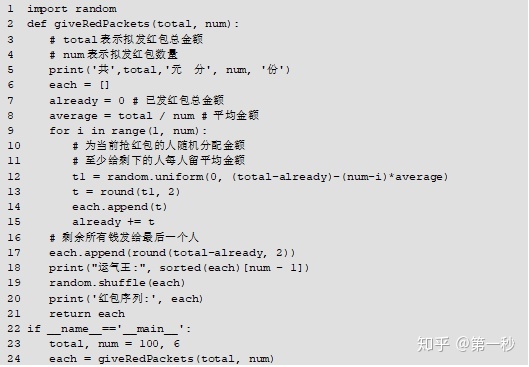
接下来按照上述要求编写发红包功能模块,具体实现如例所示
本章小结
•本章主要介绍了Python程序中的模块与包,包括模块的概念、模块的导入、内置标准模块、自定义模块、包的概念、包的发布及安装。在开发应用时可以将程序组织成模块架构,这样不仅可以提高代码的重用性,而且便于将复杂任务分解并进行分块调试。