在Reduce阶段进行Join操作,假如有两个文件要进行Join(一个非常大,一个非常小),就会出现容易出现数据倾斜。固此这篇案例使用Map进行Join操作。
(1)需求
加载小文件进入缓存

另一个文件内容
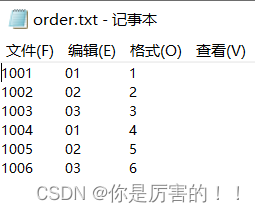
效果
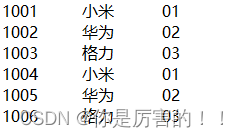
(2)需求分析
Map
端表合并案例分析(
Distributedcache
)

(3)代码实现
使用Maven工程实现
配置pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.hadoop</groupId>
<artifactId>MapReduceDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
(1)Mapper类
package com.hadoop.mapreduce.mapJoin;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;
/**
* @author codestart
* @create 2023-06-22 0:05
*/
public class MapJoinMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
private HashMap<String, String> pdMap = new HashMap<>();
private Text outK = new Text();
@Override
protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
//获取缓存文件,并封装文件内容
URI[] cacheFiles = context.getCacheFiles();
//获取文件系统,使用流打开文件(获取文件流)
FileSystem fs = FileSystem.get(context.getConfiguration());
FSDataInputStream open = fs.open(new Path(cacheFiles[0]));
//从流读数据(使用缓冲流读数据)
BufferedReader reader = new BufferedReader(new InputStreamReader(open, "UTF-8"));
String line;
//使用comment包下,判断读取的数据是否为空
while (StringUtils.isNotEmpty(line = reader.readLine())) {
String[] split = line.split("\t");
//使用HashMap集合赋值
pdMap.put(split[0], split[1]);
}
//关流
IOUtils.closeStream(reader);
}
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
//处理主数据文件(pd.txt)
//获取一行数据
String s = value.toString();
//分割
String[] split = s.split("\t");
//获取要Join的数据(pid)
String s1 = pdMap.get(split[1]);
//封装数据
outK.set(split[0] + "\t" + s1 + "\t" + split[1]);
context.write(outK,NullWritable.get());
}
}
(2)Driver类
package com.hadoop.mapreduce.mapJoin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.FileInputStream;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @author codestart
* @create 2023-06-21 23:52
*/
public class MapJoinDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException, URISyntaxException {
//1、获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2、设置jar位置
job.setJarByClass(MapJoinDriver.class);
//3、关联Mapper
job.setMapperClass(MapJoinMapper.class);
//4、设置Mapper输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
//5、设置最终输出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//加载数据缓存 D:\data\input\tablecache
job.addCacheFile(new URI("file:///D:/data/input/tablecache/pd.txt"));
//设置不需要Reduce
job.setNumReduceTasks(0);
//6、设置输入输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\data\\input\\inputtable2"));
FileOutputFormat.setOutputPath(job, new Path("D:\\data\\output\\output1"));
//7、提交job
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
(4)最终效果和总结
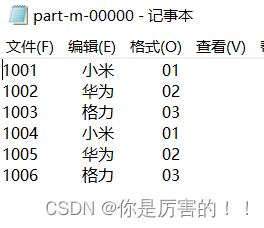
总结:使用Map join实现连接两个数据集,避免了存在一个数据集非常大,一个数据集非常小,会产生数据倾斜的问题,所以使用Map join对数据集进行连接。
以上是我通过网络学习,自己总结和练习的过程。一是为了防止自己忘记学过的知识,二是分享自己学习过程得到的结果,以此来发布博客。以上如有雷同,请联系本人!
版权声明:本文为weixin_61959079原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。