BOM(Byte Order Mark)
在分析unicode之前,先把bom(byte order mark)说一下。
bom是unicode字符顺序的标识符号,一般以魔数(magic code)的形式出现在以Unicode字符编码的文件的开始的头部,作为该文件的编码标识。
来举个很简单的例子,在windows下新建一个文本文件,并另存为utf8的文件格式:

该文件里面没有任何内容,我们再用Hex Edit来查看该文件的二进制内容:
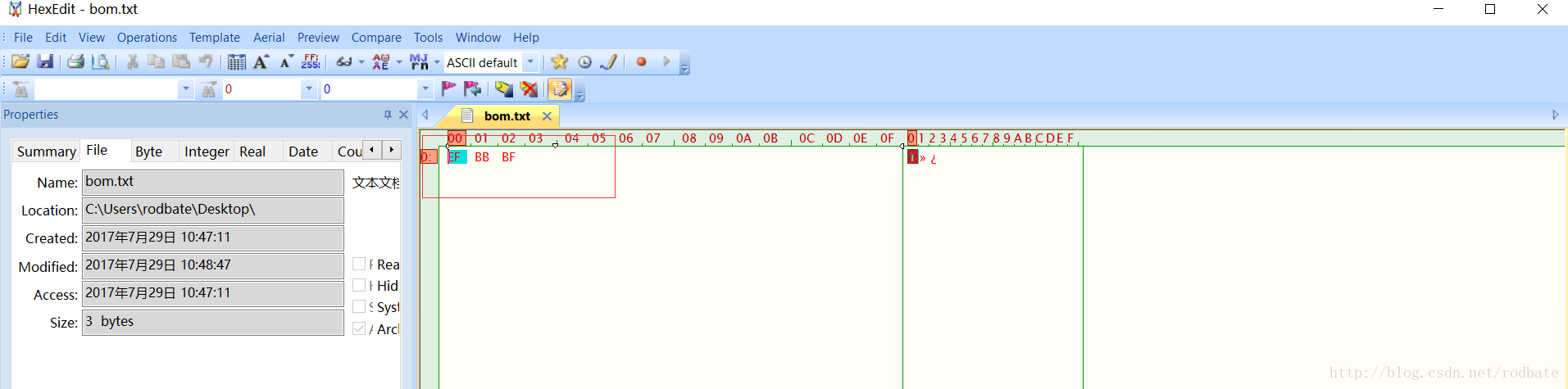
0XEFBBBF就是这个文件的bom, 这也就是标识该文件是以utf8为编码格式的,下面来看看字符编码与其bom的对应关系
| 字符编码 | Bom (十六进制) |
|---|---|
| UTF-8 | EF BB BF |
| UTF-16 (BE) 大端 | FE FF |
| UTF-16 (LE) 小端 | FF FE |
| UTF-32 (BE) 大端 | 00 00 FE FF |
| UTF-32 (LE) 小端 | FF FE 00 00 |
| GB-18030 | 84 31 95 33 |
上面只是列举了一些常用的字符编码,上面其它的bom验证也可以像上面的utf8 bom一样验证。
UTF-8编码剖析
Unicode编码以code point 来标识每一个字符, code point 的范围是
0x000000 – 0x10FFFF,也就是每一个字符的code point都落在这个范围,而utf8的一个字符可以用1-4字节来表示,可能有人会说这code point最大也就是0x10FFFF,为什么最大不是可以用三个字节表示呢?那是因为utf8有自己独特的表示格式,先来看看下面的对应关系:
| 字节数 | 字符code point位数 | 最小的code point | 最大的code point | 第一个字节 | 第二个字节 | 第三个字节 | 第四个字节 |
|---|
版权声明:本文为rodbate原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。