一、tcp和udp的使用?区别? tcp的可靠性怎么保证?数据不丢失
1.1 UDP:用户数据报协议
UDP 特点:无连接、不可靠:
-
无连接
,在通讯之前不需要建立连接,直接传输数据 -
不可靠
,是将数据包的分组从一台主机发送到另一台主机,但并不保证数据报能够到达另一端,任何必须的可靠性都由应用程序提供。在UDP情况下,虽然可以确保发送消息的大小,却不保证消息一定会到达目的端
- UDP没有超时和重传功能,当UDP数据封装到IP数据报传输时,如果丢失,会发送一个ICMP无差错报文给源主机
-
即使出现网络阻塞情况,
UDP也无法进行流量控制
。此外,传输途中即使出现丢包,UDP也不负责重发,甚至出现包的到达顺序杂乱
也没有纠正的功能
。 - UDP在传输数据之前不需要先建立连接,远地主机在收到UDP报文后,不需要给出任何确认,虽然UDP不提供可靠交付,但在某些情况下UDP却是一种最有效的工作方式(一般用于即时通信),比如:QQ语音、QQ视频、直播等。
1.2 TCP:传输控制协议
- TCP协议是面向连接的、可靠的、有流量控制、拥塞控制、面向字节流传输的协议
-
题目:
-
TCP的可靠数据传输
- TCP的可靠数据传输服务确保数据在传输中是完整且按序的
-
需要解决的问题:
- 乱序 序号seq字段
-
丢包
- 确认号ack+超时/重传
-
减少丢包
- 拥塞控制 解决网络延时突然增大,触发大量的数据重传,导致网络负担加重问题
- 流量控制-利用滑动窗口 当接收方来不及处理发送方数据时,提示发送方速率,防止包丢失
-
序号和确认号
-
TCP协议面向字节流,为每个字节都编上序号。在发送时多个字节组成报文段发送。
- 序号seq字段指的是第一个报文段第一个子节的序号
- 确认号ack字段指的是希望收到的下一个报文段的第一个字节的序号
-
TCP提供全双工通信:
- 发送缓存:准备发送的数据&以及发送但没有收到确认的数据
- 接受缓存:按序到达但没有被应用程序读取的数据&没有按需到达的数据
-
TCP默认使用累计确认
- 只会返回该按序接受的报文段下一个报文的第一个序号
- 累计确认可以让我们同时对多个接受的报文进行一次确认
-
TCP协议面向字节流,为每个字节都编上序号。在发送时多个字节组成报文段发送。
-
重传
-
超时+重传
- 发送发发送一个未被确认的数据包后就启动一个计时器,如果在指定时间内没有收到ACK,发送方可以重传该报文
- 存在问题:等待时间太长
-
冗余确认(冗余ACK)提前知道数据丢失-快速重传
- 每当比期望序号大的失序报文段到达时,发送一个冗余ACK,指明下一个期待字节的序号
- TCP发送方一次性可以发送多个报文段,接收方使用累计确认
-
超时+重传
-
TCP流量控制
- 流量控制:让发送方慢点,要让接收方来得及接受 TCP利用滑动窗口机制实现流量控制 (控制方:接收方 被控制方:发送方)
-
原理:在通信过程中,接收方根据接受缓存的大小,通过设置确认报文段的窗口字段来将rwnd(接受窗口)通知发送给发送方,发送方的发送窗口取接受窗口rwnd和拥塞窗口cwnd的最小值
- 接受窗口:接收方根据接受缓存设置的值,并告诉给发送方,反映接收方容量
- 拥塞窗口:发送方根据自己估算的网络拥塞程度而设置的窗口值,反映网络当前的容量
-
TCP拥塞控制
- 拥塞控制的目的:防止过多的数据注入到网络中,全局性
- 四种算法 慢开始+拥塞避免 快重传+快恢复
- TCP和UDP的区别,需要先将self转为strong指针,避免在运行到某个关键步骤时self对象被析构。
-
__block
- __block可以用于解决block内部无法修改auto变量值的问题
- __block不能修饰全局变量、静态变量(static)
- 编译器会将__block变量包装成一个对象,对象里一个_forwarding指针,此指针指向自身对象
四、 block的变量捕获机制原理,哪些变量会强引用,哪些不会?所有外部变量都会强引用吗?
- 在使用block的时候,为了避免产生循环引用,通常需要使用wekself与strongself,self持有block,block持有self
- 某个类将block作为自己的属性变量(强引用),然后该类在block的方法体里面又使用了该类本身(block内部使用强引用),这里会产生循环引用问题,
- 不是所有的block都需要强引用
- 是指在 block 内部会专门新增一个成员变量,来存储传进来的值。或者说将外面的值捕获到 block 结构体中存储。
五. swift和OC的区别
- OC的类由.h和.m两个文件组成,而swift只有。swift一个文件。所以swift文件数量比oc有一定减少
- 不像c语言和oc语言一样必须要有一个主函数main()作为程序的入口,swift程序从第一句开始向下顺序执行,一直到最后。(swift将全局范围内的收据可执行代码作为程序入口,swift也有main函数,只是不用我们自己编写)
- swift数据类型都会自动判断,只区分变量var和常量let
- 关于BOOL类型更加严格,swift不再是OC的非0就是真,而是true才是真false才是假
- swift的switch语句后面可以跟各种数据类型了,eg:int,字符串,元组,区间都行,并且里面不用写break
- swift中可以定义不继承于其他的类,不能被其它类继承
-
final关键字
- 使用final关键字修饰的类,不能被其它类继承
- 继承final关键字修饰的类回报错:inheritance from a final calss ‘……’
- 类方法修饰符:static
-
guard关键词
-
注意事项:
- guard关键字必须使用在函数中
- guard关键字必须和else同时出现
- guard关键字只有条件为false的时候才能走else语句 相反执行后边语句
-
用处
- 判断某个参数是否符合要求,不符合直接返回,省去过多的if-else语句
-
注意事项:
-
In out 关键词
-
In-out 是修饰函数参数类型,表示该参数在函数内修改后(即函数返回后),其值为修改后的值
- 适用类型为变量
- in-out修饰后的参数,在传参时需&修饰
-
In-out 是修饰函数参数类型,表示该参数在函数内修改后(即函数返回后),其值为修改后的值
- oc的NSDictionary的key要遵循NSCopying协议,一般使用字符串;Swift的Dictionary的key遵循Hashable就行,可以使用字符串,也能使用int等类型
-
swift比oc的优势
- swift容易阅读,语法和文件结构简易化
- swift更易于维护,文件分离后结构更清晰
-
swift更加安全,它是类型安全的语音
- swift是一个类型安全的语言,即可以让你清楚知道代码要处理的值的类型,如果代码需要一个string,你不会不小心传进去一个int
- 由于swift类型安全的,所以它会在编译你得代码时进行类型检查,并把不匹配的类型标记为错误,可以让你在开发的时候尽早发现并修复错误
- 当你需要处理不同类型的值时,类型检查可以帮你避免错误。声明常量和变量的时候并不需要显示指定类型,如果没有显示指定类型,swift会使用类型推断来选择合适的类型,有了类型推断,编译器可以在编译代码的时候自动推断出表达式的类型。原理就是检查赋值
- 因为有类型推断,和c.oc比起来,swift很少需要声明类型。常量和变量虽然需要明确类型,但大部分工作并不需要自己来完成
- swift代码更少,简洁的语法,可以省去大量冗余代码
- swift速度更快,运算性能更高
-
swift比oc的劣势
- 使用人数少
- 版本不稳定,之前升级swift3大动刀
- 社区的开源项目少,很多类库都不支持swift,现在好点,在好转
- 公司使用的比例不高,很多公司以稳为主,还是再使用OC开发,很少一些在进行混合开发,更少一些事纯swift开发
- 偶尔开发中遇到一些问题,很难查找到相关资料,是一个弊端
- 纯swift的运行和OC有本质区别,一些oc中运行时的强大功能,在swift中变无效了
- 对于不支持swift的一些第三方类库,如果非得使用,只能混合编程,利用桥接文件实现。
六、swift类和结构体的区别?class、struct
- 类属于引用类型,结构体属于值类型
- 类允许被继承,结构体不允许被继承
- 类中的每一个成员变量都必须被初始化,否则编译器会报错,而结构体不需要,编译器会自动帮我们生成init函数,给变量赋一个默认值
七、swift哪些是值类型,哪些是引用类型
- 基本类型都是值类型,eg:整形(int)、浮点型(float)、布尔类型(boolean)、字符串(string)、数组(Array)\字典(dictionary)、元组(Tuple)这些 底层是以结构体(struct)的形式实现的,所以结构体(struct)也是值类型,枚举(enum)也是值类型。
- 值类型的变量在赋值时是值拷贝的
- calss(类)是引用类型,与值类型不同,引用类型在被赋予到一个变量、常量或者一个函数时,其值不会被拷贝。因此,引用的是已存在的实例本身而不是拷贝。
-
值类型和引用类型的内存管理
- 值类型存储在栈区:每个值类型变量都有其自己的数据副本,并且对一个变量的操作不会影响另一个变量。
- 引用类型存储在其他位置(堆区):我们内存中有一个指向该位置的引用。引用类型的变量指向相同类型的数据。因此,对一个变量进行的操作会影响另一变量所指向的数据
- 栈区:存储临时数据:方法的参数和局部变量。每次我们调用一个方法时,都会在栈上分配一块新的内存。该方法退出时,将释放该内存。(出特殊情况外)所以值类型都在此处
- 堆区:存储具有生存期的对象。这些都是swift引用类型,还有一些值类型的情况。堆和栈朝着彼此增长,堆区的分配一般按照地址从小到大进行,而栈区的分配一般按照地址从大到小进行分配。
八、OC中KVO的底层实现原理 哪些操作改变 通知外部
-
kvo简介
* kvo是oc对观察者设置模式的一种实现,它提供一种机制,指定一个被观察对象(如A类),当对象中的某个属性发生变化的时候,对象就会接到通知,并作出相应的处理。在mvc架构下的项目,kco机制很适合实现model模型和view视图之间的通讯。ed:代码中,在模型类a创建属性数据,在控制器中创建观察者,一旦属性数据发生改变,观察者收到通知,通过kvo再在控制器使用回调方法处理实现视图B的更新 -
实现原理
- KVO的实现依赖于object-c强大的runtim,KVO的底层实现是监听setter方法。当观察某对象A时,KVO动态机制会动态创建一个A的子类,并为这个新的子类重写父类的setter发放。setter方法随后负责通知观察对象属性的变化
-
深入理解
- Applea使用isa混写来实现KVO,当观察对象A的时候(也就是调用对象A注册观察者的时候),KCO机制会动态创建一个A的新的子类:NSKVONotifying_A的新类,该类继承自对象A的本类,且KVO会为NSKVONotifying_A重写其父类的setter方法,setter方法会负责在调用seeter方法之前或之后,通知所有观察对象属性值的更爱状况
-
addobserver方法内部实现:
- 在这个方法中,被观察对象的issa指针从指向原来的A类,KVO机制修改为指向A类的子类NSKVONotifying_A,来实现当前类属性值改变的监听。
- Isa指针的作用:每个对象都有一个isa指针,指向该对象的类。它告诉Runtime系统这个对象的类是什么,所以对象注册为观察者的时候,isa指针会指向新的子类,那么这个对象就会变成新的对象了,因此,该对象调用setter就会调用已经重写的setter了,从而激活键值通知机制
-
子类setter方法剖析:
- KVO的键值观察通知依赖于NSObject的两个方法:willChangeValueForKey didChangeValueForKey.在存取值的前后分别调用的方法。被观察属性发生改变之前,willchangeValueforkey:被调用,通知系统该keypath的属性值即将变更;当改变发生后,didchangevalueforkey:被调用,通知系统该keypath的属性已经变更;之后。observeValueForKey:ofObject:change:context:也会被调用。且重写观察属性的setter方法这种继承方式的注入实在运行时而不是编译时实现的。
九、iOS 线程和进程
-
进程
* 进程是指系统中正在运行的一个应用程序,是程序执行的一个实例
* 程序运行时系统会创建一个进程,并为它分配资源,然后把该进程放入进程就绪队列,进程调度器选中它的时候就会为它分配CPU时间,程序开始真正运行
* 每个进程之间都是独立的,每个进程运行在其专有且受保护的内存空间中
* 再MAC电脑上,可以通过活动监视器查看所开启的进程(iOS开发是单进程,安卓可以是多进程) -
线程
- 线程是进程的基本执行单元,一个进程中的所有任务都是在线程中进行的
- 进程想要执行任务必须得有线程,一个任务至少有一个线程
- 程序启动时会默认开启一条线程,这条线程被称为主线程或者UI线程
-
进程和线程的区别
- 进程是资源分配的最小单位,线程是程序执行的最小单位
- 进程有自己的独立地址空间,每启动一个进程,程序就会为它分配地址空间,简历数据表来维护代码段,堆栈段和数据段,这种操作非常昂贵。而线程是共享进程中的数据的,使用相同的地址空间,因此CPU切换一个线程花费的远比进程小的多,同事创建一个线程的开销也比进程要小很多
- 线程之间的通信更方便,通一进程下的线程共享全局变量、静态变量等数据,而进程之间的通信需要以通信的方式(IPC)进行。不过如何处理好同步与互斥是编写多线程程序的难点
- 多拿时候多进程程序更雄壮,多线程程序只要有一个线程撕掉,整个进程也就死掉了,而一个进程死掉并不会对另外的一个进程造成影响,因为进程有自己独立的地址空间。
-
多线程的意义
-
一个进程的任务都是多个的,单线程的执行效率肯定是低下的,在开发中都是多线程编程,为什么要使用多线程?
- 比如:循环执行十万次的循环,在循环进行还进行局部变量的创建,此过程执行完成共耗时接近一分钟,如果此流程放在主线程,会造成主线程卡顿,极大的影响用户体验。
- 所以通常情况下,我们都会进行异步处理,开启新的线程给我这些事物进行处理,而如果一个事物很复杂,比较耗时,可以将一个大的事物拆分成多个小的食物进行并发处理,这样可以节省时间,并且不会影响用户体验
-
一个进程的任务都是多个的,单线程的执行效率肯定是低下的,在开发中都是多线程编程,为什么要使用多线程?
-
多线程的优缺点
-
优点:
- 能适当提高程序的执行效率
- 能释放提高资源的利用效率(如CPU、内存)
- 线程上的任务执行完成后,线程会自动销毁
-
缺点:
- 开启线程需要占用一定的内存空间(默认情况下,每一个线程都占512KB)
- 如果开启大量的线程,会占用大量的内存空间,降低程序的性能
- 线程越多,CPU在调用线程上的开销就越大,程序设计更加复杂,比如线程间的通信,多线程的数据共享
-
优点:
-
时间片:
- 时间片又称“量子”或“处理器片”是分时操作系统分配给每个正在运行的进程微观上的一段CPU时间(在抢占内核中是:从进程开始运行直到被抢占的时间)
-
简单来说就是:CPU时间片即CPU分配给多个程序的时间每个线程被分配一个时间段,称作它的时间片
- 宏观上,我们可以同时打开多个应用程序,每个程序并行不悖,同时运行
- 微观上,由于只有一个CPU,一次只能处理程序要求的一部分,如果处理公平,一种方法就是引入时间片,每个程序轮流执行。
- 多程序的执行:是CPU快速的在多个线程之间进行切换。线程数过多,CPU会在多个线程之间切换,销毁大量的CPU资源,反而导致执行效率的下降
- 多线程同时执行,是指CPU快速的在多个线程之间的切换,CPU调度线程的时间足够快,就造成了多线程的同时执行的效果
- 如果线程数非常多,CPU会在N个线程之间切换,消耗大量的CPU资源,每个线程被调度的次数降低,线程的执行效率降低。
十、timer使用的注意事项 tableview滑动时,会停止计时,如何解决这个问题,不论滑动不滑动 都能正常工作
- 原因:滑动的时候,主线程的runloop会切换到UITrackingRunLoopMode,执行的就是这个mode下任务,而timer是添加到NSDefaultRunloopMode下的,所以timer任务不会执行,只有当UITrackingRunLoopMode的任务执行完毕,runloop切换到NSDefaultRunloopMode,才会继续执行timer
- 解决办法:将timer放到NSRunloopCommonModes中执行即可,[NSRunloop currentRunLoop] addTimer:timer forMode:NSRunCommonModes]; [NSRunloop currentRunLoop] run];
十一、runloop的作用?
Runloop 处理事件接收和分发的机制,一个runloop就是一个事件处理的循环,用来不停地调度工作及处理输入事件,使用runloop的目的是保证程序执行的线程不会被系统终止。
十二、MVC和MVVM的区别?技术选型时怎么定用哪个?
- MVVM与MVC最大区别就是:MVVM实现了View和Model的自动同步,也就是Model的数据改变时,我们不用自己手动操作Dom元素,来改变View的显示,而是改变数据后该数据对应View层显示会自动改变。MVVM并不是用VM完全取代了C,ViewModel存在的目的在于抽离Controller中展示的业务逻辑,而不是替代Controller,其他视图操作业务员等还是应该放在Controller中实现。
- MVVM主要解决了MVC大量dom操作使页面渲染性能降低,加载速度变慢,影响用户体验
十三、OC的方法查找流程?消息机制?
-
方法的查找流程(氛围快速查找流程和慢速查找流程)
-
快速查找流程 (由)汇编语言编写,从-objc_msgSend开始:
- 通过消息接受者的isa,查找其类或者元类(实例方法通过isa找对象的元类)。
- 当找到类或者元类后,通过内存偏移,找到类的cache属性,然后再调用cachelookup
- 在cachelookup流程中,将方法编号转换成对应的key,再去cache缓存中找该方法。
- 如果该方法已经不在cache中缓存了,那么直接返回方法的imp
- 如果在chche中找不到,那么进入jumpmiss流程,调用_objc_msgSend_uncached
- 在_objc_msgSend_uncache中,调用methodTableLookup,到此则意味着快速查找流程结束了
- methodtablelookup中,则准备一些相关的参数等,然后调用_class_loookupMethodAndLoafCache3进入慢速查找流程
-
_class_loookupMethodAndLoafCache3里面又调用了LookUpImpOrForward函数(这个函数主要分为四部分)
- 查找缓存中是否缓存了该方法,这个方法的cache有可能在别的地方调用的时候传true
- 判断当前的类是否河大,是否已经实例化,如果没有实例化,那么需要对类,类的父类,以及类元类,元类的元类进行实例化
- 在当前类中的方法列表中查找该方法,如果查到到直接返回IMP
- 在父类的方法列表中查找该方法,如果父类没有,则循环找父类的父类,直到老祖宗级别,找到返回IMP
- 如果到这步还没有找到,那么进入方法转发阶段
- 如果方法转发成功 成功,否则崩溃报错
-
方法查找小结
-
实例方法的查找流程
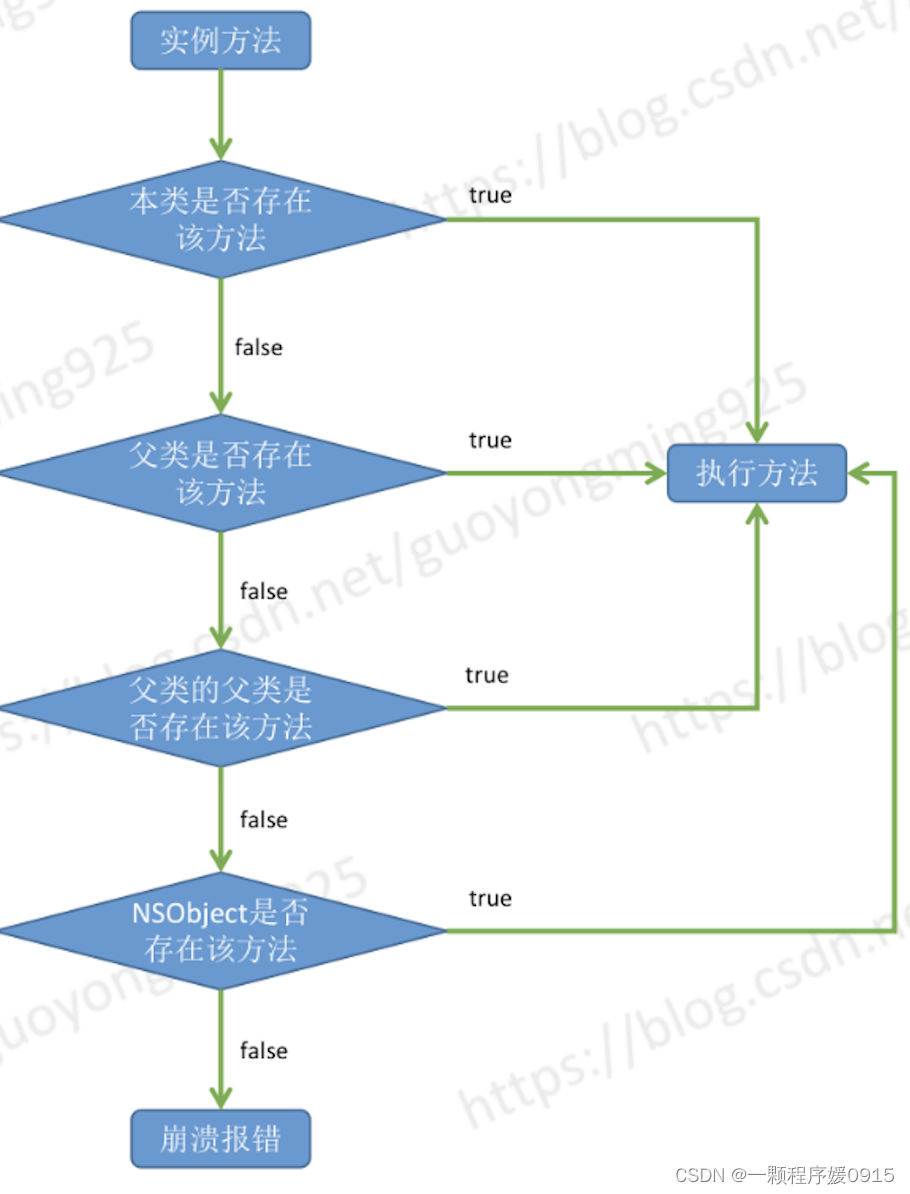
-
类方法的查找流程
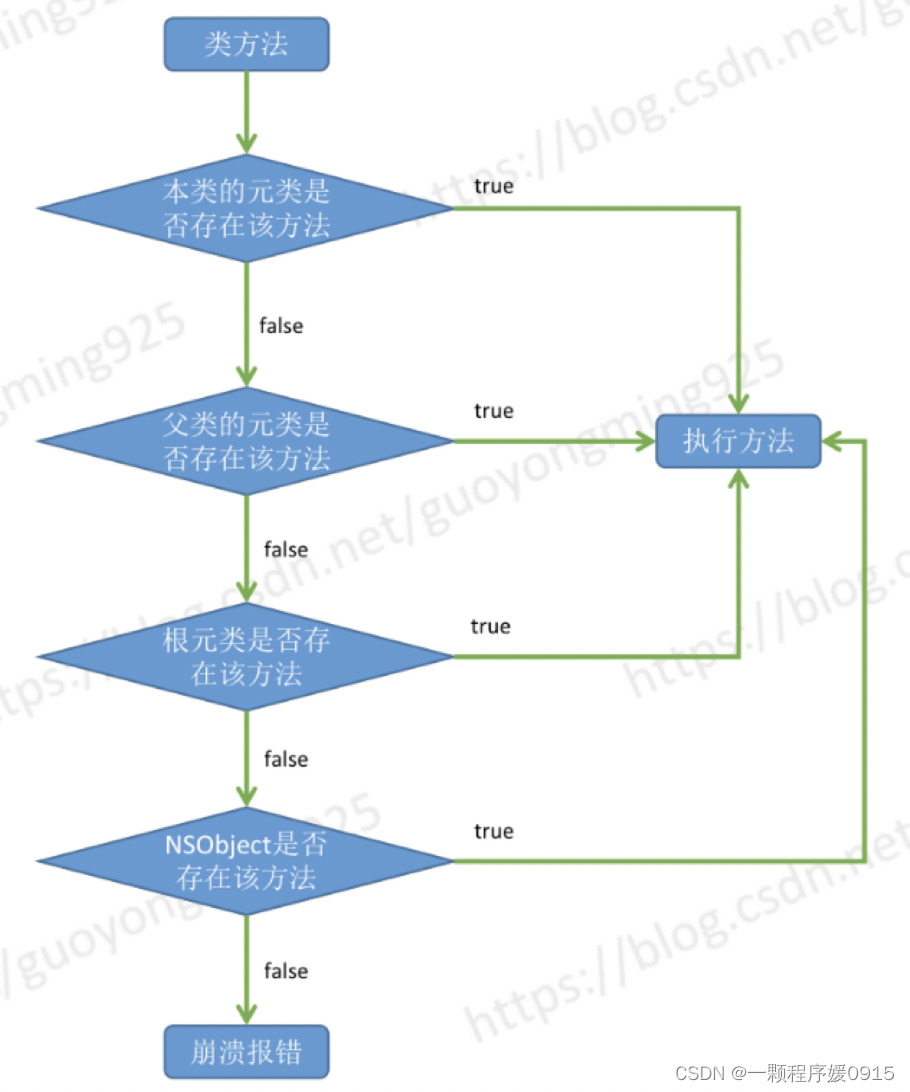
-
-
快速查找流程 (由)汇编语言编写,从-objc_msgSend开始:
-
OC的方法方法调用其实都是转成了objc_mshSend函数的调用,给receiver(方法调用者)发送了一条消息 objc_msgSend底层有三大阶段:消息发送阶段,动态方法解析阶段,消息转发阶段
-
消息发送阶段
- 首先判断消息接受者是否为空,如果为空,直接返回,如果不为空,通过isa指针找到类对象,从类对象的cache中查找,找到直接调用,找不到就从方法列表class_rw_t里面查找,知道啊直接调用并缓存到cache中,找不到就通过superclass指针找到父类的类对象,从父类类对象的cache中查找,找到直接调用并缓存到receiverCladd的cache中,找不到就从父类类对象的方法列表class_rw_t里面查找,找到直接调用并缓存到receiverClass的cache中,找不到就继续通过superclass指针往上找,直到基类都找不到的话就进入到动态方法分析阶段
-
动态方法解析阶段
-
首先会判断是否已进行动态方法解析
- 是:会调用resolveInstanceMethod:方法来动态解析方法,并且标记为已经动态解析
- 否:进入消息转发阶段
-
首先会判断是否已进行动态方法解析
-
消息转发阶段
-
调用forwardingTargetForSelector:方法看返回值是否为nil
- 否:objc_msgSend(返回子,SEL)
- 是:调用methodSignatureForSelector:方法进行方法签名
-
看返回值是否为nil
- 否:调用forwardinvocation:方法
- 是:调用doesNotRecognizeSelectot:方法
- objc_msgSend如果找不到合适的方法进行调用,会报错unrecognizws selector sent to instance
-
调用forwardingTargetForSelector:方法看返回值是否为nil
-
Oc 的消息机制,流程总结
-
objc的消息机制,是通过objc_megSend方法发送消息给接受者,发送消息的流程是:
- 去类和父类的方法缓存里面找(找不到的话,就去动态方法解析)
- resolveinstanceMethod:通过这个方法,去动态方法解析(如果解析还没找到该方法的调用者)
- forwardTargetForSelector:方法去消息转发
- methodSignalForSelector:去方法签名
- Forwardinvocation:去最后的操作
-
objc的消息机制,是通过objc_megSend方法发送消息给接受者,发送消息的流程是:
-
消息发送阶段
十四、abc三个任务,怎么保证啊a,b,执行完执行c?
-
dispatch_group
-
流程:
- 创建一个group:dispatch_group_t group = dispatch_group_create();
-
把一个异步操作加到group中:
- dispatch_group_enter(group);
- dispatch_async(dispatch_get_global_queue(DISPARCH_QUEUE_PRIQRITY_DEFAULT,0),^{* dispatch_group_leave(group)});
-
等待group完成所有异步操作
-
dispatch_group_notify(group,dispatch_get_main_queue(),^{
});
-
dispatch_group_notify(group,dispatch_get_main_queue(),^{
-
说明:
- dispatch_group_notify:当group中所有的block操作都完成后才会执行,不会阻塞当前调用线程,如果需要阻塞当前调用线程,可使用dispath_group_wait(group,DISPATCH_TIME_FOREVER);
- dipatch_group_enter:增加当前group执行block数
- dispatch_group_leave:减少当前group执行block数
-
重点:
- Diaptch_group_enter与dispatch_group_leave必须成对出现
- Ios6.0以下系统版本需要手动管理dispatch_group对象生命周期,dispatch_retain和dispatch_release
-
流程:
- dispatch_barrier
十五、GCD的栅栏函数?
-
https://www.jianshu.com/p/0473071bf719
-
什么是栅栏函数 (只有当栅栏函数执行完毕后才能执行后面的函数。使用栅栏函数规定线程执行顺序,栅栏函数不能使用全局并发队列)
- 在GCD中的栅栏函数有dispatch_barrier_async(异步)和dispatch_barrier_sync(同步),异步不会阻塞当前线程,同步会阻塞线程。在GCD的并行队列中,栅栏函数起到一个栅栏的作用,它等待队列所有位于barrier函数之前的操作执行完毕后执行,并且在barrier函数执行之后,barrier函数之后的操作才能得到执行,该函数需要同Dispatch_queue_creat函数生成的DISPATCH_QUEUE_CONCURRENT队列一起使用。
-
栅栏函数的使用
- 栅栏函数的这个特点,使得它适合用于做多读写单写读写锁。比如对于一个数据,可以多线程读取,但是只能单线程修改,就非常适合函数dispatch_barrier和同步函数diapatch_async配合并行队列做数据的读写安全机制
-
什么是栅栏函数 (只有当栅栏函数执行完毕后才能执行后面的函数。使用栅栏函数规定线程执行顺序,栅栏函数不能使用全局并发队列)
十六、 OC中的实例对象、类对象、元类对象的联系?
https://www.jianshu.com/p/3e634e701b5d
1. instance对象(实例对象)
* 实例对象就是类通过alooc出来的对象,每次allloc都会产生一个新的instance对象
* instance对象中存储着isa和其他成员变量
2. 类对象
* 每个类有且只有一个类对象,通过+ (Class)class OBJC_SWIFT_UNAVAILABLE(“use ‘aClass.self’ instead”);或者通过runtime函数object_getClass(id _Nullable obj) ;来获取NSLog(@“%p — %p”, [ZJPerson class], object_getClass(person));
* 类对象中存储着isa 指针、superClass指针、属性信息、实例方法信息、协议信息、成员变量信息(此处的成员变量和实例对象中的成员变量不太一样,实例中的成员变量记录的是值,而类对象的成员变量记录的是成员变量的类型以及名字)
3. 元类对象
* 每个类有且只有一个元类对象,通过runtime函数object_getClass(id _Nullable obj) ;来获取 ,只不过参数传类对象
* 元类对象中存储着:isa指针、superClass指针、类方法信息
4. 联系
1. instance对象的isa指针指向class对象
2. class对象的isa指向meta-class对象
3. meta-class的isa指针指向基类的meta-class
4. meta-class的isa指针指向父类的class
* 如果没有父类,则supreclass为nil
5. meta-class的super-class指向父类的meta-class
* 基类的meta-class的superclass指向基类的class
6. instance方法调用轨迹
* 通过instance的isa指针找到class,如果不存在就通过superclass指针往上找,直到为nil,抛出异常
7. class方法调用轨迹
* 通过class的isa指针找到meta_class,如果不存在就通过superclass指针往上找,直到为nil,抛出异常
5. 题目:
1. 对象的isa指针指向哪里?
* instance对象的isa指向class对象
* class对象的isa指向meta-class对象
* meta-class对象的isa指向基类的meta-class对象
2. OC的类信息存放在哪里?
* 成员变量具体的值,存放在instance对象中
* 成员变量、协议、实例方法、属性,存放在class对象中
* 类方法,存放在meta-class对象中
十七、堆和栈的区别
1. 申请方式不同。栈由系统自动分配,申请栈空间时不需要指明大小,而堆是人为申请开辟,申请堆空间时需要指明大小
2. 申请大小不同,栈获得的空间较小,而堆获得的空间较大
3. 申请效率不同,栈由系统自动分配,速度较快,而堆一般速度较慢
4. 存储内容不同,栈在函数调用时,函数调用的下一跳可执行语句的地址第一个进栈,然后函数的各个参数进栈,其中静态变量是不入栈的(局部变量、函数参数)。而堆一般是在头部用一个字节存放堆的大小,堆中的具体内容是人为安排的
5. 底层不同,栈是连续的空间,由高到低地址,而堆是不连续的空间,由低到高地址
十八、 学习其他的东西?性格?优势?
。。。