本文主要任务是利用Pytorch实现DeeoFM模型,并在将模型运行在Criteo数据集上进行验证测试。
DeepFM模型简述
FM模型善于挖掘二阶特征交叉关系,而神经网络DNN的优点是能够挖掘高阶的特征交叉关系,于是DeepFM将两者组合到一起,实验证明DeepFM比单模型FM、DNN效果好。DeepFM相当于同时组合了原Wide部分+二阶特征交叉部分+Deep部分三种结构,无疑进一步增强了模型的表达能力。
![]()

数据集介绍和运行环境
运行环境:python 3.6、pytorch 1.5、pandas、numpy
Criteo数据集:Criteo Dataset 是CTR领域的经典数据集,特征经过脱敏处理,[I1,I13]为数值特征,[C1,C26]为类别特征。
kaggle Criteo:是完整的数据集,大概有45000000个样本
下载地址:
Kaggle Display Advertising Challenge Dataset – Criteo Engineering
sample Criteo:是对kaggle Criteo数据集的采样,有1000000个样本
代码实现
run_deepfm.py代码实现
导入库
import pandas as pd
import torch
from sklearn.metrics import log_loss, roc_auc_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
import sys
import os
import torch.nn as nn
import numpy as np
import torch.utils.data as Data
from torch.utils.data import DataLoader
import torch.optim as optim
import torch.nn.functional as F
from sklearn.metrics import log_loss, roc_auc_score
from collections import OrderedDict, namedtuple, defaultdict
import random
from deepctrmodels.deepfm import Deepfm设置随机种子,保证程序可再现
seed = 1024
torch.manual_seed(seed) # 为CPU设置随机种子
torch.cuda.manual_seed(seed) # 为当前GPU设置随机种子
torch.cuda.manual_seed_all(seed) # 为所有GPU设置随机种子
np.random.seed(seed)
random.seed(seed)读入数据
sparse_features = ['C' + str(i) for i in range(1, 27)] #C代表类别特征 class
dense_features = ['I' + str(i) for i in range(1, 14)] #I代表数值特征 int
col_names = ['label'] + dense_features + sparse_features
data = pd.read_csv('dac/train.txt', names=col_names, sep='\t')
feature_names = sparse_features + dense_features #全体特征名
data[sparse_features] = data[sparse_features].fillna('-1', ) # 类别特征缺失 ,使用-1代替
data[dense_features] = data[dense_features].fillna(0, ) # 数值特征缺失,使用0代替
target = ['label'] 类别特征编号,数值特征maxmin归一化
# 1.Label Encoding for sparse features,and do simple Transformation for dense features
# 使用LabelEncoder(),为类别特征的每一个item编号
for feat in sparse_features:
lbe = LabelEncoder()
data[feat] = lbe.fit_transform(data[feat])
# 数值特征 max-min 0-1归化
mms = MinMaxScaler(feature_range=(0, 1))
data[dense_features] = mms.fit_transform(data[dense_features])建立字典{特征名:特征总类别数} (数值特征类别数直接置为1)
# 2.count #unique features for each sparse field,and record dense feature field name
feat_sizes1={ feat:1 for feat in dense_features}
feat_sizes2 = {feat: len(data[feat].unique()) for feat in sparse_features}
feat_sizes={}
feat_sizes.update(feat_sizes1)
feat_sizes.update(feat_sizes2)划分数据集,这里的得到的训练集、测试集都以 {特征名 : 特征数据} 这样的形式输入模型
# 3.generate input data for model
train, test = train_test_split(data, test_size=0.2,random_state=2020)
# print(train.head(5))
# print(test.head(5))
train_model_input = {name: train[name] for name in feature_names}
test_model_input = {name: test[name] for name in feature_names}模型运行,模型参数主要是 dnn_hidden_units:神经网络参数,dnn_dropout:dropout参数 ,ebedding_size:embedding向量长度。
device = 'cpu'
use_cuda = True
if use_cuda and torch.cuda.is_available():
print('cuda ready...')
device = 'cuda:0'
model = Deepfm(feat_sizes , dnn_hidden_units=[400,400,400] , dnn_dropout=0.9 , ebedding_size = 8 ,
l2_reg_linear=1e-3, device=device)
# print(model)
# for name,tensor in model.named_parameters():
# print(name,tensor)
model.fit(train_model_input, train[target].values , test_model_input , test[target].values ,batch_size=50000, epochs=150, verbose=1)
pred_ans = model.predict(test_model_input, 50000)
print("final test")
print("test LogLoss", round(log_loss(test[target].values, pred_ans), 4))
print("test AUC", round(roc_auc_score(test[target].values, pred_ans), 4))
deepfm框架实现
init 部分
(1) 模型参数传递
def __init__(self, feat_sizes, sparse_feature_columns, dense_feature_columns,dnn_hidden_units=[400, 400,400], dnn_dropout=0.0, ebedding_size=4,
l2_reg_linear=0.00001, l2_reg_embedding=0.00001, l2_reg_dnn=0, init_std=0.0001, seed=1024,
device='cpu'):
super(Deepfm, self).__init__()
self.feat_sizes = feat_sizes
self.device = device
self.sparse_feature_columns = sparse_feature_columns
self.dense_feature_columns = dense_feature_columns
self.embedding_size = ebedding_size
self.l2_reg_linear = l2_reg_linear(2)FM 模型参数设置,具体就是设置embedding变换
self.feature_index 建立feature到列名到输入数据X的相对位置的映射
self.weight、self.embedding_dict1 与FM一阶项相关
self.embedding_dict2 用于embedding向量生成,与FM二阶项相关
self.feature_index = self.build_input_features(self.feat_sizes)
self.bias = nn.Parameter(torch.zeros((1,)))
# self.weight
self.weight = nn.Parameter(torch.Tensor(len(self.dense_feature_columns), 1)).to(device)
torch.nn.init.normal_(self.weight, mean=0, std=0.0001)
self.embedding_dict1 = self.create_embedding_matrix(self.sparse_feature_columns , feat_sizes , 1 ,
sparse=False, device=self.device)
self.embedding_dict2 = self.create_embedding_matrix(self.sparse_feature_columns , feat_sizes , self.embedding_size ,
sparse=False, device=self.device)(3)DNN模型参数设置,神经元数目,dropout率设置
# dnn
self.dropout = nn.Dropout(dnn_dropout)
self.dnn_input_size = self.embedding_size * len(self.sparse_feature_columns) + len(self.dense_feature_columns)
hidden_units = [self.dnn_input_size] + dnn_hidden_units
self.linears = nn.ModuleList(
[nn.Linear(hidden_units[i], hidden_units[i + 1]) for i in range(len(hidden_units) - 1)])
self.relus = nn.ModuleList(
[nn.ReLU() for i in range(len(hidden_units) - 1)])
for name, tensor in self.linears.named_parameters():
if 'weight' in name:
nn.init.normal_(tensor, mean=0, std=init_std)
# self.linears =self.linears.to(device)
self.dnn_linear = nn.Linear(
dnn_hidden_units[-1], 1, bias=False).to(device)
模型forward部分
FM实现
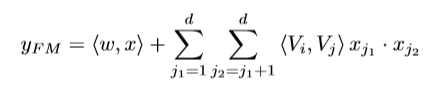
FM线性部分,即求一阶项之和
'''
FM liner
'''
sparse_embedding_list1 = [self.embedding_dict1[feat](
X[:, self.feature_index[feat][0]:self.feature_index[feat][1]].long())
for feat in self.sparse_feature_columns]
dense_value_list2 = [X[:, self.feature_index[feat][0]:self.feature_index[feat][1]]
for feat in self.dense_feature_columns]
linear_sparse_logit = torch.sum(
torch.cat(sparse_embedding_list1, dim=-1), dim=-1, keepdim=False)
linear_dense_logit = torch.cat(
dense_value_list2, dim=-1).matmul(self.weight)
logit = linear_sparse_logit + linear_dense_logit
sparse_embedding_list = [self.embedding_dict2[feat](
X[:, self.feature_index[feat][0]:self.feature_index[feat][1]].long())
for feat in self.sparse_feature_columns]FM二阶项求和
'''
FM second
'''
fm_input = torch.cat(sparse_embedding_list, dim=1) # shape: (batch_size,field_size,embedding_size)
square_of_sum = torch.pow(torch.sum(fm_input, dim=1, keepdim=True), 2) # shape: (batch_size,1,embedding_size)
sum_of_square = torch.sum(torch.pow(fm_input, 2), dim=1, keepdim=True) # shape: (batch_size,1,embedding_size)
cross_term = square_of_sum - sum_of_square
cross_term = 0.5 * torch.sum(cross_term, dim=2, keepdim=False) # shape: (batch_size,1)
logit += cross_termDNN部分
'''
DNN
'''
# sparse_embedding_list、 dense_value_list2
dnn_sparse_input = torch.cat(sparse_embedding_list, dim=1)
batch_size = dnn_sparse_input.shape[0]
# print(dnn_sparse_input.shape)
dnn_sparse_input=dnn_sparse_input.reshape(batch_size,-1)
# dnn_sparse_input shape: [ batch_size, len(sparse_feat)*embedding_size ]
dnn_dense_input = torch.cat(dense_value_list2, dim=-1)
# print(dnn_sparse_input.shape)
# dnn_dense_input shape: [ batch_size, len(dense_feat) ]
dnn_total_input = torch.cat([dnn_sparse_input, dnn_dense_input], dim=-1)
deep_input = dnn_total_input
for i in range(len(self.linears)):
fc = self.linears[i](deep_input)
fc = self.relus[i](fc)
fc = self.dropout(fc)
deep_input = fc
dnn_output = self.dnn_linear(deep_input)
实验结果
在kaggle Criteo 数据集上运行,实验结果图如下,最高AUC可以达到79.15%

完整代码:
GitHub – SpringtoString/DeepFM_torch
参考代码库DeepCTR:
GitHub – shenweichen/DeepCTR-Torch: 【PyTorch】Easy-to-use,Modular and Extendible package of deep-learning based CTR models.
DeepFM论文:
https://arxiv.org/pdf/1703.04247.pdf
PS:AUC值79.15%还达不到论文所体现的80%标准,参数比较难调,如果有大佬调出更好的结果,希望在评论下方留言。
官方链接失效了,数据集可以在kaggle下载:
Criteo_dataset | Kaggle