济南友泉软件有限公司
本文主要整理MPI编程相关的基本概念、基本框架等相关内容。
限于笔者认知水平与研究深度,难免有不当指出,欢迎批评指正!
注1:文章内容会不定期更新。
注2:限于篇幅,部分内容未标明出处,请谅解。
在高性能计算场景中,常用的消息传递编程模型包括
MPI
(Message Passing Interface)和
PVM
(Parallel Virtual Machine)等。MPI(Message Passing Interface)以其
高效的通信性能
、
较好的移植性
、
强大的功能
等优点而成为了消息传递编程模型(事实上)的行业标准。
MPI
是一种基于消息传递的分布式并行计算编程模型与标准。各个厂商或组织遵循这些标准实现自己的MPI软件包,典型的实现包括开放源代码的MPICH、OpenMPI、MS-MPI、DeinoMPI以及不开放源代码的Intel MPI。
零、并行程序设计导论
并行计算机(parallel computer):指能在同一时间执行多条指令的计算机。
并行编程模型(parallel programming model):并行计算机体系架构的一种抽象。
并行计算(parallel computing):是用多个处理器来协同求解同一问题,即将被求解的问题分解成若干个部分,各部分均由一个独立的处理机来并行计算。
并行算法(parallel algorithm):就是多个处理器来协同求解问题的方法和步骤。
一、MPI入门
1.1 MPI基础
MPI编程模型:a)
进程级并行
,同一份代码对应多个进程,每个并行进程均有自己独立的地址空间,每个进程通过communicator rank标记; b)
消息通信
,进程间通过显式地发送和接收消息来实现通信。
进程组:不同进程构成的有序集合。
A group is an ordered set of process identifiers (henceforth processes); processes are implementation-dependent objects. Each process in a group is associated with an integer rank. Ranks are contiguous and start from zero.
通信上下文:描述了一个通信空间,不同通信上下文的消息互不干涉、相互独立。
A context is a property of communicators (defined next) that allows partitioning of the communication space. A message sent in one context cannot be received in another context. Contexts are not explicit MPI objects; they appear only as part of the realization of communicators.
通信域(Communicator):由进程组、通信上下文等组成,用于描述进程间的通信关系,也就是定义哪些进程间可以通信。
同步(Synchronization):发起调用之后,
本调用者
必须等到
所有调用者
均
执行到此
同步调用点
,确保
不同调用者
的
同步调用点
前面的调用均已执行完毕。
阻塞(Blocking):发起调用之后,
本调用者
必须等到
本次调用
对应的事务处理完毕。
有序接收:阻塞/非阻塞通信均遵循有效接收的语义约束,即先发送的消息一定被先匹配的消息调用接受,即便后发送的消息先到达。
1.2 MPI网络通信模型
由于MPI抽象了底层的网络通信细节,所以,大多数情况下,并不需要掌握MPI底层网络通信模型。实际上,关于这一部分的网络资料很少,仅发现一篇讲述Open MPI架构的资料。
The Architecture of Open Source Applications (Volume 2): Open MPI
目前,OpenMPI、MPICH、Intel MPI支持OpenFabrics Interfaces (OFI)以实现了不同底层网络硬件的通信。OFI是一套网络通信编程接口,主要包括Libfabric、OFI provider等组件。
Ref. from Libfabric——————————————————————————————————–
OFI is a framework focused on exporting communication services to applications. OFI is specifically designed to meet the performance and scalability requirements of high-performance computing (HPC) applications running in a tightly coupled network environment. The key components of OFI are application interfaces, provider libraries, kernel services, daemons, and test applications.
Libfabric is a library that defines and exports the user-space API of OFI, and is typically the only software that applications deal with directly. The libfabric’s API does not depend on the underlying networking protocols, as well as on the implementation of the particular networking devices, over which it may be implemented. OFI is based on the notion of application centric I/O, meaning that the libfabric library is designed to align fabric services with application needs, providing a tight semantic fit between applications and the underlying fabric hardware. This reduces overall software overhead and improves application efficiency when transmitting or receiving data over a fabric.
——————————————————————————————————–Ref. from Libfabric

1.3 MPI数据类型
由于计算集群中每台计算机软硬件架构可能不同(不同的厂商、不同的处理器、不同的操作系统等),因此,可能存在不同的数据表示方法。为了支持异构计算,MPI提供了
预定义数据类型
来解决异构计算中的互操作性问题。
除此之外,MPI引入
派生数据类型
的概念,允许定义由数据类型不同且地址空间不连续的数据项组成的消息。
Tab.1 MPI数据类型
|
|
|
|
|
|
INTEGER INTEGER*1 INTEGER*2 INTEGER*4 |
|
|
|
REAL REAL*2 REAL*4 REAL*8 DOUBLE PRECISION |
|
|
|
COMPLEX DOUBLE COMPLEX |
|
|
|
LOGICAL |
|
|
|
CHARACTER(1) |
|
|
|
|
signed char unsigned char signed short int unsigned short int unsigned int signed int unsigned long int signed long int long long int |
|
|
|
float double long double |
|
|
|
|
|
|
|
|
1.4 常用编程接口
虽然MPI定义编程接口有很多,但是实际工作中经常使用的却并不多。下表罗列了部分常用的MPI编程接口。
Tab. 2 常用MPI接口
|
|
|
|
|
MPI_INIT |
Initialize the MPI execution environment |
|
|
MPI_FINALIZE |
Terminates MPI execution environment |
|
|
|
[in] communicator of tasks to abort
[in] error code to return to invoking environment
|
Terminates all MPI processes associated with the communicator comm |
|
MPI_WTIME |
MPI_WTIME returns a floating-point number of seconds, representing elapsed wall-clock time since some time in the past | |
| MPI_BARRIER(comm) |
[in] communicator (handle) |
Blocks the caller until all processes in the communicator have called it; that is, the call returns at any process only after all members of the communicator have entered the call. |
|
MPI_GROUP_INCL ( group, n, ranks, newgroup ) |
[in] group (handle)
[in] number of elements in array ranks (and size of newgroup ) (integer)
[in] ranks of processes in group to appear in newgroup (array of integers)
[out] new group derived from above, in the order defined by ranks (handle) |
Produces a group by reordering an existing group and taking only listed members |
|
|
|
Determines the rank of the calling process in the communicator |
|
|
|
Determines the size of the group associated with a communicator |
|
MPI_COMM_GROUP(comm, group) |
[in] Communicator (handle)
[out] Group in communicator (handle) |
Accesses the group associated with given communicator |
|
MPI_COM_CREATE ( comm, group, newcomm ) |
[in] communicator (handle)
[in] group, which is a subset of the group of comm (handle)
[out] new communicator (handle) |
Creates a new communicator |
|
MPI_COM_SPLIT ( comm, color, key, newcomm ) |
[in] communicator (handle)
[in] control of subset assignment (nonnegative integer). Processes with the same color are in the same new communicator
[in] control of rank assigment (integer)
[out] new communicator (handle) |
Creates new communicators based on colors and keys |
|
|
|
Performs a blocking send |
|
|
|
Blocking receive for a message |
|
MPI_BCAST ( buffer, count, datatype, root, comm ) |
[in/out] starting address of buffer (choice)
[in] number of entries in buffer (integer)
[in] data type of buffer (handle)
[in] rank of broadcast root (integer)
[in] communicator (handle) |
Broadcasts a message from the process with rank “root” to all other processes of the communicator |
|
MPI_GATHER ( sendbuf, sendcount, sendtype, recvbuf, recvcount, recvtype, root, comm ) |
Gathers together values from a group of processes |
[in] starting address of send buffer (choice)
[in] number of elements in send buffer (integer)
[in] data type of send buffer elements (handle)
[out] address of receive buffer (choice, significant only at root)
[in] number of elements for any single receive (integer, significant only at root)
[in] data type of recv buffer elements (significant only at root) (handle)
[in] rank of receiving process (integer)
[in] communicator (handle) |
|
MPI_GATHERV ( sendbuf, sendcount, sendtype, recvbuf, recvcounts, displs, recvtype, root, comm ) |
Gathers into specified locations from all processes in a group |
[in] starting address of send buffer (choice)
[in] number of elements in send buffer (integer)
[in] data type of send buffer elements (handle)
[out] address of receive buffer (choice, significant only at root)
[in] integer array (of length group size) containing the number of elements that are received from each process (significant only at root)
[in] integer array (of length group size). Entry i specifies the displacement relative to recvbuf at which to place the incoming data from process i (significant only at root)
[in] data type of recv buffer elements (significant only at root) (handle)
[in] rank of receiving process (integer)
[in] communicator (handle) |
|
MPI_SCATTER ( sendbuf, sendcount, sendtype, recvbuf, recvcount, recvtype, root, comm ) |
Sends data from one process to all other processes in a communicato |
[in] address of send buffer (choice, significant only at root)
[in] number of elements sent to each process (integer, significant only at root)
[in] data type of send buffer elements (significant only at root) (handle)
[out] address of receive buffer (choice)
[in] number of elements in receive buffer (integer)
[in] data type of receive buffer elements (handle)
[in] rank of sending process (integer)
[in] communicator (handle) |
|
MPI_SCATTERV ( sendbuf, sendcounts, displs, sendtype, recvbuf, recvcount, recvtype, root, comm ) |
Scatters a buffer in parts to all processes in a communicator |
[in] address of send buffer (choice, significant only at root)
[in] integer array (of length group size) specifying the number of elements to send to each processor
[in] integer array (of length group size). Entry i specifies the displacement (relative to sendbuf from which to take the outgoing data to process i
[in] data type of send buffer elements (handle)
[out] address of receive buffer (choice)
[in] number of elements in receive buffer (integer)
[in] data type of receive buffer elements (handle)
[in] rank of sending process (integer)
[in] communicator (handle) |
|
MPI_TYPE_CREATE_STRUCT ( count, array_of_blocklengths, array_of_displacements, array_of_types,
) |
Create an MPI datatype from a general set of datatypes, displacements, and block sizes |
[in] number of blocks (integer) — also number of entries in arrays array_of_types, array_of_displacements and array_of_blocklengths
[in] number of elements in each block (array of integer)
[in] byte displacement of each block (array of integer)
[in] type of elements in each block (array of handles to datatype objects)
[out] new datatype (handle) |
| MPI_GET_ADDRESS(location,address) | Get the address of a location in memory |
[in] location in caller memory (choice)
[out] address of location (address) |
| MPI_TYPE_COMMIT(datatype) | Commits the datatype |
[in] datatype (handle) |
| MPI_TYPE_FREE(datatype) | Frees the datatype |
[in] datatype that is freed (handle) |
在这些常用MPI接口中,MPI_INIT、MPI_COMM_RANK、MPI_COMM_SIZE、MPI_SEND、MPI_RECV、MPI_FINALIZE等构成了MPI最小编程子集。
1.5 MPI程序示例
本节通过一个简单的MPI程序来阐述MPI程序设计范式。
注意:无论是C还是FORTRAN,通信域内MPI进程rank均是从0开始编号。
#include "mpi.h"
#include <stdio.h>
int main(int argc, char* argv[])
{
int rank, size, i;
int buffer[10];
MPI_Status status;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (size < 2)
{
printf("Please run with two processes.\n"); fflush(stdout);
MPI_Finalize();
return 0;
}
if (rank == 0)
{
for (i = 0; i < 10; i++)
buffer[i] = i;
MPI_Send(buffer, 10, MPI_INT, 1, 123, MPI_COMM_WORLD);
}
if (rank == 1)
{
for (i = 0; i < 10; i++)
buffer[i] = -1;
MPI_Recv(buffer, 10, MPI_INT, 0, 123, MPI_COMM_WORLD, &status);
for (i = 0; i < 10; i++)
{
if (buffer[i] != i)
printf("Error: buffer[%d] = %d but is expected to be %d\n", i, buffer[i], i);
}
fflush(stdout);
}
MPI_Finalize();
return 0;
}
二、数据类型
为了解决非连续数据(数据块由不同类型数据组成,或者数据块内数据元素不相邻)的发送,MPI可以通过类型图来创建派生数据类型。
2.1 类型图
类型图实际上是一系列二元组<基类型,偏移>的无序集合。即
其中,基类型描述了数据元素的数据类型;偏移则描述了该数据元素在类型图中的起始位置,偏移量可以是负整数。
类型图的下界
:
类型图的上界
:
类型图的跨度
:
地址对界修正量
:使新建数据类型的跨度能被其对界量整除的最小非负整数。
2.2 伪数据类型
MPI提供了两个伪数据类型:MPI_LB、MPI_UB。这两个伪数据类型不占用空间,
主要用于指定新建数据类型的上下界
。
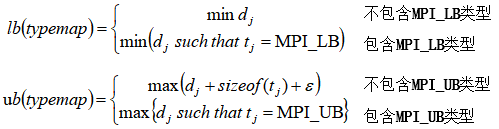
2.3 相关API
根据不同需要,为了简化派生数据类型的创建,MPI提供了丰富的API用于创建和管理派生数据类型。
|
API |
参数 |
说明 |
|
MPI_Type_commit |
|
Commits the datatype |
|
MPI_Type_free |
|
Frees the datatype |
| MPI_Type_contiguous |
[in] replication count (nonnegative integer)
[in] old datatype (handle)
[out] new datatype (handle) |
Creates a contiguous datatype |
| MPI_Type_vector |
[in] number of blocks (nonnegative integer)
[in] number of elements in each block (nonnegative integer)
[in] number of elements between start of each block (integer)
[in] old datatype (handle)
[out] new datatype (handle) |
Creates a vector (strided) datatype |
| MPI_Type_create_hvector |
[in] number of blocks (nonnegative integer)
[in] number of elements in each block (nonnegative integer)
[in] number of bytes between start of each block (integer)
[in] old datatype (handle)
[out] new datatype (handle) |
Create a datatype with a constant stride given in bytes |
| MPI_Type_indexed |
[in] number of blocks — also number of entries in indices and blocklens
[in] number of elements in each block (array of nonnegative integers)
[in] displacement of each block in multiples of old_type (array of integers)
[in] old datatype (handle)
[out] new datatype (handle) |
Creates an indexed datatype |
| MPI_Type_create_hindexed |
[in] number of blocks — also number of entries in displacements and blocklengths (integer)
[in] number of elements in each block (array of nonnegative integers)
[in] byte displacement of each block (array of integer)
[in] old datatype (handle)
[out] new datatype (handle) |
Create a datatype for an indexed datatype with displacements in bytes |
|
MPI_Type_create_struct |
|
Create an MPI datatype from a general set of datatypes, displacements, and block sizes |
| MPI_Type_extent |
[in] datatype (handle)
[out] datatype extent (integer) |
Returns the extent of a datatype |
| MPI_Type_size |
[in] datatype (handle)
[out] datatype size (integer) |
Return the number of bytes occupied by entries in the datatype |
| MPI_Type_create_resized |
[in] input datatype (handle)
[in] new lower bound of datatype (integer)
[in] new extent of datatype (integer)
[out] output datatype (handle) |
Create a datatype with a new lower bound and extent from an existing datatype |
| MPI_Type_lb |
[in] datatype (handle)
[out] displacement of lower bound from origin, in bytes (integer) |
Returns the lower-bound of a datatype |
| MPI_Type_ub |
[in] datatype (handle)
[out] displacement of upper bound from origin, in bytes (integer) |
Returns the upper bound of a datatype |
三、点对点通信
在MPI中,点对点通信(Point-to-Point Communication)指的是一对进程之间的通信,一个进程发送消息,另一个进程接收消息。点对点通信是MPI通信的基础。

=============================
Ref. from
MPI
: A Message-Passing Interface Standard
Sending and receiving of
messages
by processes is the basic MPI communication mechanism. The basic point-to-point communication operations are
send
and
receive
.
MPI
: A Message-Passing Interface Standard =============================
3.1 MPI消息
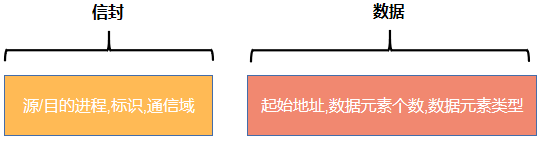
MPI消息由信封与数据等两部分组成。信封部分描述了消息发送或接收进程及其相关信息;数据部分是消息的主体,承载需要发送的内容。
=============================
Ref. from
MPI
: A Message-Passing Interface Standard
The data part of the message consists of a sequence of
count
values, each of the type indicated by
datatype
.
count
may be zero, in which case the data part of the message is empty.
In addition to the data part, messages carry information that can be used to distinguish messages and selectively receive them. This information consists of a fixed number of fields, which we collectively call the message envelope. These fields are source, destination, tag and communicator.
The message source is implicitly determined by the identity of the message sender. The other fields are specified by arguments in the send procedure.
The message destination is specified by the dest argument.
The integer-valued message tag is specified by the tag argument. This integer can be used by the program to distinguish different types of messages.
A communicator specifies the communication context for a communication operation. Each communication context provides a separate “communication universe”: messages are always received within the context they were sent, and messages sent in different contexts do not interfere. The communicator also specifies the set of processes that share this communication context. This process group is ordered and processes are identified by their rank within this group.
Ref. from
MPI
: A Message-Passing Interface Standard =============================
3.2 通信模式
在MPI中,通信模式(Communication Modes)包含
标准通信模式
(standard mode)、
缓存通信模式
(buffered-mode)、
同步通信模式
(synchronous-mode)、
就绪通信模式
(ready-mode)等四种。
| 通信模式 | 发送 | 接收 |
| 标准通信模式 | MPI_SEND | MPI_RECV |
| 缓存通信模式 | MPI_BSEND | |
| 同步通信模式 | MPI_SSEND | |
| 就绪通信模式 | MPI_RSEND |
3.3 相关API
| 接口 | 参数 | 描述 |
|
MPI_Send |
[in] initial address of send buffer (choice)
[in] number of elements in send buffer (nonnegative integer)
[in] datatype of each send buffer element (handle)
[in] rank of destination (integer)
[in] message tag (integer)
[in] communicator (handle) |
Performs a blocking send |
|
MPI_Recv |
[out] initial address of receive buffer (choice)
[in] maximum number of elements in receive buffer (integer)
[in] datatype of each receive buffer element (handle)
[in] rank of source (integer)
[in] message tag (integer)
[in] communicator (handle)
[out] status object (Status) |
Blocking receive for a message |
| MPI_Sendrecv |
[in] initial address of send buffer (choice)
[in] number of elements in send buffer (integer)
[in] type of elements in send buffer (handle)
[in] rank of destination (integer)
[in] send tag (integer)
[out] initial address of receive buffer (choice)
[in] number of elements in receive buffer (integer)
[in] type of elements in receive buffer (handle)
[in] rank of source (integer)
[in] receive tag (integer)
[in] communicator (handle)
[out] status object (Status). This refers to the receive operation. |
Sends and receives a message |
| MPI_Bsend |
[in] initial address of send buffer (choice)
[in] number of elements in send buffer (nonnegative integer)
[in] datatype of each send buffer element (handle)
[in] rank of destination (integer)
[in] message tag (integer)
[in] communicator (handle) |
Basic send with user-provided buffering |
| MPI_Ssend |
[in] initial address of send buffer (choice)
[in] number of elements in send buffer (nonnegative integer)
[in] datatype of each send buffer element (handle)
[in] rank of destination (integer)
[in] message tag (integer)
[in] communicator (handle) |
Blocking synchronous send |
| MPI_Rsend |
[in] initial address of send buffer (choice)
[in] number of elements in send buffer (nonnegative integer)
[in] datatype of each send buffer element (handle)
[in] rank of destination (integer)
[in] message tag (integer)
[in] communicator (handle) |
Blocking ready send |
| MPI_Buffer_attach |
[in] initial buffer address (choice)
[in] buffer size, in bytes (integer) |
Attaches a user-provided buffer for sending |
| MPI_Buffer_detach |
[out] initial buffer address (choice)
[out] buffer size, in bytes (integer) |
Removes an existing buffer (for use in This operation will block until all messages currently in the buffer have been transmitted. Upon return of this function, the user may reuse or deallocate the space taken by the buffer. |
四、组通信
组通信(Collective Communication, 又称集合通信)需要一个一组进程内的所有进程同时参加通信,组内各个不同进程的调用形式完全相同。
=============================
Ref. from
MPI
: A Message-Passing Interface Standard
Collective communication is defined as communication that involves a group or groups of processes.
One of the key arguments in a call to a collective routine is a communicator that
defines the group or groups of participating processes and provides a context for the operation.
MPI
: A Message-Passing Interface Standard =============================
4.1 功能概述
通信
、
同步
、
计算
等三个方面来分析组通信API。
- 通信
组通信实现了进程组内所有进程的通信,这个进程组由组通信API的通信域参数进行指定。MPI确保
组通信消息不会与点-点通信相互混淆
。
One of the key arguments in a call to a collective routine is a communicator that defines the group or groups of participating processes and provides a context for the operation
.
Several collective routines such as broadcast and gather have a single originating or receiving process. Such a process is called the root.
Some arguments in the collective functions are specified as “significant only at root,” and are ignored for all participants except the root.
Collective communication calls may use the same communicators as point-to-point communication;
MPI guarantees that messages generated on behalf of collective communication calls will not be confused with messages generated by point-to-point communication.
The collective operations do not have a message tag argument.
- 同步
MPI组通信并不承诺组通信调用返回后,本进程组内的其他进程是否已经完成调用,它只是保证返回调用的进程相对应的操作已经完成,此时可以释放缓冲区或者使用缓冲区内的内容。因此,
不应当寄希望组通信调用会起到同步的作用
。
Collective operations can (but are not required to) complete as soon as the caller’s participation in the collective communication is finished. A blocking operation is complete as soon as the call returns. A nonblocking (immediate) call requires a separate completion call.
The completion of a collective operation indicates that the caller is free to modify locations in the communication buffer. It does not indicate that other processes in the group have completed or even started the operation (unless otherwise implied by the description of the operation). Thus,
a collective communication operation may, or may not, have the effect of synchronizing all participating MPI processes.
It is dangerous to rely on synchronization side-effects of the collective operations for program correctness.
For example, even though a particular implementation may provide a broadcast routine with a side-effect of synchronization, the standard does not require this, and a program that relies on this will not be portable
. On the other hand, a correct, portable program must allow for the fact that a collective call may be synchronizing. Though one cannot rely on any synchronization side-effect, one must program so as to allow it.
- 计算
组通信也提供了
归约
、
扫描
等操作。
Global
reduction
operations such as sum, max, min, or user-defined functions, where the result is returned to all members of a groupand a variation where the result is returned to only one member.
4.2 常用API
根据通信方式、数据操作等,MPI提供了大量的API支持组通信。
|
接口 |
参数 |
说明 |
| MPI_Barrier |
[in] communicator (handle) |
Blocks until all processes in the communicator have reached this routine. |
| MPI_Bcast |
[in/out] starting address of buffer (choice)
[in] number of entries in buffer (integer)
[in] data type of buffer (handle)
[in] rank of broadcast root (integer)
[in] communicator (handle) |
Broadcasts a message from the process with rank “root” to all other processes of the communicator |
| MPI_Scatter |
[in] address of send buffer (choice, significant only at root)
[in] number of elements sent to each process (integer, significant only at root)
[in] data type of send buffer elements (significant only at root) (handle)
[out] address of receive buffer (choice)
[in] number of elements in receive buffer (integer)
[in] data type of receive buffer elements (handle)
[in] rank of sending process (integer)
[in] communicator (handle) |
Sends data from one process to all other processes in a communicator |
| MPI_Scatterv |
[in] address of send buffer (choice, significant only at root)
[in] integer array (of length group size) specifying the number of elements to send to each processor
[in] integer array (of length group size). Entry i specifies the displacement (relative to sendbuf from which to take the outgoing data to process i
[in] data type of send buffer elements (handle)
[out] address of receive buffer (choice)
[in] number of elements in receive buffer (integer)
[in] data type of receive buffer elements (handle)
[in] rank of sending process (integer)
[in] communicator (handle) |
Scatters a buffer in parts to all processes in a communicator |
| MPI_Gather |
[in] starting address of send buffer (choice)
[in] number of elements in send buffer (integer)
[in] data type of send buffer elements (handle)
[out] address of receive buffer (choice, significant only at root)
[in] number of elements for any single receive (integer, significant only at root)
[in] data type of recv buffer elements (significant only at root) (handle)
[in] rank of receiving process (integer)
[in] communicator (handle) |
Gathers together values from a group of processes |
| MPI_Gatherv |
[in] starting address of send buffer (choice)
[in] number of elements in send buffer (integer)
[in] data type of send buffer elements (handle)
[out] address of receive buffer (choice, significant only at root)
[in] integer array (of length group size) containing the number of elements that are received from each process (significant only at root)
[in] integer array (of length group size). Entry i specifies the displacement relative to recvbuf at which to place the incoming data from process i (significant only at root)
[in] data type of recv buffer elements (significant only at root) (handle)
[in] rank of receiving process (integer)
[in] communicator (handle) |
Gathers into specified locations from all processes in a group |
| MPI_Allgather |
[in] starting address of send buffer (choice)
[in] number of elements in send buffer (integer)
[in] data type of send buffer elements (handle)
[out] address of receive buffer (choice)
[in] number of elements received from any process (integer)
[in] data type of receive buffer elements (handle)
[in] communicator (handle) |
Gathers data from all tasks and distribute the combined data to all tasks |
| MPI_Allgatherv |
[in] starting address of send buffer (choice)
[in] number of elements in send buffer (integer)
[in] data type of send buffer elements (handle)
[out] address of receive buffer (choice)
[in] integer array (of length group size) containing the number of elements that are received from each process
[in] integer array (of length group size). Entry i specifies the displacement (relative to recvbuf ) at which to place the incoming data from process i
[in] data type of receive buffer elements (handle)
[in] communicator (handle) |
Gathers data from all tasks and deliver the combined data to all tasks |
| MPI_Alltoall |
[in] starting address of send buffer (choice)
[in] number of elements to send to each process (integer)
[in] data type of send buffer elements (handle)
[out] address of receive buffer (choice)
[in] number of elements received from any process (integer)
[in] data type of receive buffer elements (handle)
[in] communicator (handle) |
Sends data from all to all processes |
| MPI_Alltoallv |
[in] starting address of send buffer (choice)
[in] integer array equal to the group size specifying the number of elements to send to each processor
[in] integer array (of length group size). Entry j specifies the displacement (relative to sendbuf from which to take the outgoing data destined for process j
[in] data type of send buffer elements (handle)
[out] address of receive buffer (choice)
[in] integer array equal to the group size specifying the maximum number of elements that can be received from each processor
[in] integer array (of length group size). Entry i specifies the displacement (relative to recvbuf at which to place the incoming data from process i
[in] data type of receive buffer elements (handle)
[in] communicator (handle) |
Sends data from all to all processes; each process may send a different amount of data and provide displacements for the input and output data. |
| MPI_Reduce |
[in] address of send buffer (choice)
[out] address of receive buffer (choice, significant only at root)
[in] number of elements in send buffer (integer)
[in] data type of elements of send buffer (handle)
[in] reduce operation (handle)
[in] rank of root process (integer)
[in] communicator (handle) |
Reduces values on all processes to a single value |
| MPI_Allreduce |
[in] starting address of send buffer (choice)
[out] starting address of receive buffer (choice)
[in] number of elements in send buffer (integer)
[in] data type of elements of send buffer (handle)
[in] operation (handle)
[in] communicator (handle) |
Combines values from all processes and distributes the result back to all processes |
| MPI_Scan |
[in] starting address of send buffer (choice)
[out] starting address of receive buffer (choice)
[in] number of elements in input buffer (integer)
[in] data type of elements of input buffer (handle)
[in] operation (handle)
[in] communicator (handle) |
Computes the scan (partial reductions) of data on a collection of processes |
4.3 程序示例:计算圆周率

,根据定积分公式
,,
// pi.cpp : This file contains the 'main' function. Program execution begins and ends there.
//
#include <iostream>
#include <mpi.h>
const double PI = 4.0 * atan(1.0);
int main(int argc, char *argv[])
{
::MPI_Init(&argc, &argv);
int size;
::MPI_Comm_size(MPI_COMM_WORLD, &size);
int rank;
::MPI_Comm_rank(MPI_COMM_WORLD, &rank);
int N = 100;
// the lb and up for local integral
int nx_begin = (rank + 0) * (int)std::ceil(1.0 * N / size);
int nx_end = (rank + 1) * (int)std::ceil(1.0 * N / size);
if (rank == 0)
{
std::cout << "nx_begin = " << nx_begin << ", nx_end = " << nx_end << std::endl;
}
double dx = 1.0 / N;
double sum = 0.0;
// numerical integral for process 'rank'
for (int i = nx_begin; i < nx_end; ++i)
{
if (i < N)
{
double x = dx * (i + 0.5);
sum = sum + 4.0 / (1.0 + x * x);
}
}
sum = sum / N;
::MPI_Barrier(MPI_COMM_WORLD);
// sum all integrals
double pi = 0.0;
::MPI_Reduce(&sum, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
//::MPI_Allreduce(&sum, &pi, 1, MPI_DOUBLE, MPI_SUM, MPI_COMM_WORLD);
// output the result and error
if (rank == 0 || rank == 1)
{
std::cout << "Process " << rank << ", pi estamated is " << pi << ", error " << fabs(pi - PI) / PI << std::endl;
}
::MPI_Finalize();
}
五、进程组和通信域
通信域、进程组是MPI中的比较重要的改建,构成了MPI网络通信的核心组件。
5.1 通信域
通信域(Communicator)定义了MPI进程通信的范围与状态。MPI通信域由通信上下文、进程组、进程拓扑、属性等内容组成。
当调用MPI_INIT函数之后,MPI自动创建了MPI_COMM_NULL、MPI_COMM_SELF、MPI_COMM_WORLD等通信域。
5.2 进程组
进程组实际上是由一些列进程构成的有序集合。无论对于FORTRAN还是C/C++,进程组内每个进程均有一个从0开始编号的进程ID(通过MPI_COMM_RANK获得进程ID)。
MPI预定义了MPI_GROUP_NULL、MPI_GROUP_EMPTY、MPI_COOM_GROUP等进程组。
5.3 常用API
|
接口 |
参数 |
说明 |
| MPI_Comm_size |
[in] communicator (handle)
[out] number of processes in the group of comm (integer) |
Determines the size of the group associated with a communicator |
| MPI_Comm_rank |
[in] communicator (handle)
[out] rank of the calling process in the group of comm (integer) |
Determines the rank of the calling process in the communicator |
| MPI_Comm_create |
[in] communicator (handle)
[in] group, which is a subset of the group of comm (handle)
[out] new communicator (handle) |
Creates a new communicator |
| MPI_Comm_split |
[in] communicator (handle)
[in] control of subset assignment (nonnegative integer). Processes with the same color are in the same new communicator
[in] control of rank assigment (integer)
[out] new communicator (handle) |
Creates new communicators based on colors and keys |
| MPI_Comm_free |
[in] Communicator to be destroyed (handle) |
Marks the communicator object for deallocation |
| MPI_Comm_group |
[in] Communicator (handle)
[out] Group in communicator (handle) |
Accesses the group associated with given communicator |
| MPI_Group_size |
[in] group (handle) Output Parameter:
[out] number of processes in the group (integer) |
Returns the size of a group |
| MPI_Group_rank |
[in] group (handle)
[out] rank of the calling process in group, or MPI_UNDEFINED if the process is not a member (integer) |
Returns the rank of this process in the given group |
| MPI_Group_incl |
[in] group (handle)
[in] number of elements in array ranks (and size of newgroup ) (integer)
[in] ranks of processes in group to appear in newgroup (array of integers)
[out] new group derived from above, in the order defined by ranks (handle) |
Produces a group by reordering an existing group and taking only listed members |
| MPI_Group_excl |
[in] group (handle)
[in] number of elements in array ranks (integer)
[in] array of integer ranks in group not to appear in newgroup
[out] new group derived from above, preserving the order defined by group (handle) |
Produces a group by reordering an existing group and taking only unlisted members |
| MPI_Group_free |
[in] group to free (handle) |
Frees a group |
六、非阻塞通信
在MPI中,非阻塞通信(Nonblocking Communication)调用不等到通信操作完成便可以返回,在这过程中,处理器可以同时进行其他操作,从而实现
计算与通信的重叠
,进而大大提高程序执行的效率。
====================Ref. from 都志辉 <高性能计算并行编程激素-MPI并行程序设计>

Ref. from 都志辉 <高性能计算并行编程激素-MPI并行程序设计>====================
6.1 非阻塞通信API
| 通信模式 | 发送 | 接收 | |
| 标准通信模式 | MPI_ISEND | MPI_IRECV | |
| 缓存通信模式 | MPI_IBSEND | ||
| 同步通信模式 | MPI_ISSEND | ||
| 就绪通信模式 | MPI_IRSEND | ||
| 重复非阻塞通信 | 标准通信模式 | MPI_SEND_INIT | MPI_RECV_INT |
| 缓存通信模式 | MPI_BSEND_INIT | ||
| 同步通信模式 | MPI_SSEND_INIT | ||
| 就绪通信模式 | MPI_RSEND_INIT | ||
6.2 非阻塞通信对象
MPI非阻塞通信调用会返回一个非阻塞通信对象request,通过这个返回参数可以查询非阻塞通信状态。
| 接口 | 参数 | 说明 |
| MPI_WAIT |
[in] request (handle)
[out] status object (Status). May be MPI_STATUS_IGNORE. |
Waits for an MPI request to complete |
| MPI_WAITANY |
[in] list length (integer)
[in/out] array of requests (array of handles)
[out] index of handle for operation that completed (integer). In the range 0 to count-1. In Fortran, the range is 1 to count.
[out] status object (Status). May be MPI_STATUS_IGNORE. |
Waits for any specified MPI Request to complete |
| MPI_WAITALL |
[in] list length (integer)
[in] array of request handles (array of handles)
[out] array of status objects (array of Statuses). May be MPI_STATUSES_IGNORE. |
Waits for all given MPI Requests to complete |
| MPI_WAITSOME |
[in] length of array_of_requests (integer)
[in] array of requests (array of handles)
[out] number of completed requests (integer)
[out] array of indices of operations that completed (array of integers)
[out] array of status objects for operations that completed (array of Status). May be MPI_STATUSES_IGNORE. |
Waits for some given MPI Requests to complete |
| MPI_TEST |
[in] MPI request (handle)
[out] true if operation completed (logical)
[out] status object (Status). May be MPI_STATUS_IGNORE. |
Tests for the completion of a request |
| MPI_TESTANY |
[in] list length (integer)
[in] array of requests (array of handles)
[out] index of operation that completed, or MPI_UNDEFINED if none completed (integer)
[out] true if one of the operations is complete (logical)
[out] status object (Status). May be MPI_STATUS_IGNORE. |
Tests for completion of any previdously initiated requests |
| MPI_TESTALL |
[in] lists length (integer)
[in] array of requests (array of handles)
[out] True if all requests have completed; false otherwise (logical)
[out] array of status objects (array of Status). May be MPI_STATUSES_IGNORE. |
Tests for the completion of all previously initiated requests |
| MPI_TESTSOME |
[in] length of array_of_requests (integer)
[in] array of requests (array of handles)
[out] number of completed requests (integer)
[out] array of indices of operations that completed (array of integers)
[out] array of status objects for operations that completed (array of Status). May be MPI_STATUSES_IGNORE.
|
Tests for some given requests to complete |
七、进程拓扑
进程拓扑(Process Topologies)是 (域内) 通信器的一个附加属性,它描述了一个通信域内各进程间的逻辑联接关系。进程拓扑提供了一种方便的命名机制,辅助映射进程到硬件。
=============================
Ref. from
MPI
: A Message-Passing Interface Standard
A process group in MPI is a collection of n processes. Each process in the group is assigned a rank between 0 and n-1. In many parallel applications a linear ranking of processes does not adequately reflect the logical communication pattern of the processes (which is usually determined by the underlying problem geometry and the numerical algorithm used). Often the processes are arranged in topological patterns such as two- or three-dimensional grids. More generally, the logical process arrangement is described by a graph. In this chapter we will refer to this logical process arrangement as the “virtual topology.”
A topology is an extra, optional attribute that one can give to an intra-communicator; topologies cannot be added to intercommunicators. A topology can provide a convenient naming mechanism for the processes of a group (within a communicator), and additionally, may assist the runtime system in mapping the processes onto hardware.
MPI supports three topology types:
Cartesian
,
graph
, and
distributed
graph.
Ref. from
MPI
: A Message-Passing Interface Standard =============================
7.1 笛卡尔拓扑
笛卡尔拓扑是将通信域内的进程排列成具有规则网格形状的拓扑结构。
7.2 图拓扑
The communication pattern of a set of processes can be represented by a graph. The nodes represent processes, and the edges connect processes that communicate with each other.
7.3 相关API
|
接口 |
参数 |
说明 |
| MPI_Cart_create |
[in] input communicator (handle)
[in] number of dimensions of cartesian grid (integer)
[in] integer array of size ndims specifying the number of processes in each dimension
[in] logical array of size ndims specifying whether the grid is periodic (true) or not (false) in each dimension
[in] ranking may be reordered (true) or not (false) (logical)
[out] communicator with new cartesian topology (handle) |
Makes a new communicator to which topology information has been attached |
| MPI_Graph_create |
[in] input communicator without topology (handle)
[in] number of nodes in graph (integer)
[in] array of integers describing node degrees (see below)
[in] array of integers describing graph edges (see below)
[in] ranking may be reordered (true) or not (false) (logical)
[out] communicator with graph topology added (handle) |
Makes a new communicator to which topology information has been attached |
八、MPI-2
MPI-2
是 MPI 论坛在 1997 年宣布的 MPI 修改版本。原来的 MPI 被重命名为
MPI-1
。
MPI-2
增加了增加了
并行I/O
、
远程存储访问
、
动态进程管理
等新特性。
8.1 基本概念
串行 I/O
: 读写文件的操作由一个进程完成, 即根结点上的进程 发出 I/O 请求, 将整个文件全部读入, 其他进程需要的数据区域则以消息传递方式从根节点获得; 写文件也同样, 当某进程 的数据区域处理完毕, 需要写回磁盘时, 首先该进程以消息传 递方式发送给主结点, 由主结点对该数据区域进行写。
并行 I/O
: 各进程各自独立地发出 I/O 请求, 以得到相应的数据区域, 即不需要转发的操作,多个处理器可同时对共享文件或不同文件进行 I/O 访问。
阻塞 I/O
: 启动一个I/O操作后,直到 I/O请求完成才返回。
非阻塞 I/O
: 启动一个I/O操作后, 并不等待 I/O 请求完成。
集中式I/O
:通信域内所有进程都必须执行相同I/O调用,提供给调用函数的参数可以不同。
非集中式I/O
:通信域内单个进程就可以执行I/O调用,不需要其他进程参与。
起始偏移(displacement)
:一个文件的起始位置指相对于文件开头以字节为单位的一个绝对地址, 它用来定义一个“文件视窗”的起始位置。
A fifile displacement is an absolute byte position relative to the beginning of a fifile. The displacement defifines the location where a view begins. Note that a “fifile displacement” is distinct from a “typemap displacement.”
基本类型(elementary datatype)
:定义一个文件最小访问单元的 MPI 数据类型, 基本类型可以是任何预定义或用户构造的并已经递交的 MPI 数据类型。
An etype (elementary datatype) is the unit of data access and positioning. It can be any MPI predefifined or derived datatype. Derived etypes can be constructed using any of the MPI datatype constructor routines, provided all resulting typemap displace
ments are non-negative and monotonically nondecreasing. Data access is performed in etype units, reading or writing whole data items of type etype.
Offffsets are expressed as a count of etypes; fifile pointers point to the beginning of etypes. Depending on context, the term “etype” is used to describe one of three aspects of an elementary datatype: a particular MPI type, a data item of that type, or the extent of that type.
文件类型(filetype)
:定义了文件中需要访问的数据分布,文件类型可以等于基本单元类型, 也可以是在基本单元类型基础上构造并已递交的任意 MPI 数据类型。
A filetype is the basis for partitioning a fifile among processes and defifines a template for accessing the fifile. A fifiletype is either a single etype or a derived MPI datatype constructed from multiple instances of the same etype. In addition, the extent of any hole in the fifiletype must be a multiple of the etype’s extent. The displacements in the typemap of the fifiletype are not required to be distinct, but they must be non-negative and monotonically nondecreasing.
文件视口(view):
一个文件中目前可以访问的数据集.,文件视口可以看作一个三元组<起始位置, 基本单元类型, 文件单元类型>。
A
view
defifines the current set of data visible and accessible from an open fifile as an ordered set of etypes. Each process has its own view of the fifile, defifined by three quantities: a displacement, an etype, and a fifiletype. The pattern described by a fifiletype is repeated, beginning at the displacement, to defifine the view. The pattern of repetition is defifined to be the same pattern that
MPI_TYPE_CONTIGUOUS would produce if it were passed the fifiletype and an
arbitrarily large count
Views can be changed by the user during program execution. The default view is a linear byte stream (displacement is zero, etype and fifiletype equal to MPI_BYTE).

8.2 MPI-2 并行I/O
MPI-2在
派生数据类型
基础之上,借助通过
缓存
、
数据过滤、合并访存
等技术,实现了大量进程对数据文件的并发访问。具体来说,MPI-2 并行I/O对
非集中式I/O使用“数据筛选”技术优化
,
对集中式I/O使用“两阶段IO”技术优化
。
Ref. from Walfredo Cirne ======================================================
The most effective approach to ameliorate this problem is parallel I/O. The basic idea is quite simple: If one disk cannot keep the pace of the processor, why not scatter I/O requests on many disks and have them process the requests in parallel?
Three orthogonal aspects characterize the file access operations:
positioning
,
synchronism
, and
coordination
.
Positioning
determines which part of the file is read from (or written to) disk and can be
explicitly specified
on the MPI call, or it can implicitly use the file pointer. In the latter case, there are still two alternatives: each process has its own
individual file pointer
but a unique (per file)
shared pointer
is also available. The effect of multiple calls to shared file pointer routines is defined to behave as if the calls were serialized.
Synchronism
defines whether the requested operation is guaranteed to be finished after the call returns.
Coordination
settles whether the request is an individual or a collective operation.
====================================================== Ref. from Walfredo Cirne
MPI-2 并行IO相关的API比较多,按照
定位方法
可以分为
显示偏移
、
独立文件指针
、
共享文件指针
等三类;按照
同步方式
,可以分为
阻塞
、
非阻塞
等两类;按照
协调方式
,分为
聚合
、
非聚合
等两类。
MPI 聚合IO通过将不同进程的请求合并,合并后可以对重新对文件进行连续规则的访问,这样可以大大提高IO性能。
|
Positioning |
Synchronism |
Coordination |
|
|
Individual |
Collective |
||
|
explicit offsets |
blocking |
MPI_FILE_READ_AT MPI_FILE_WRITE_AT |
MPI_FILE_READ_AT_ALL MPI_FILE_WRITE_AT_ALL |
|
nonblocking |
MPI_FILE_IREAD_AT MPI_FILE_IWRITE_AT |
MPI_FILE_READ_AT_ALL_BEGIN MPI_FILE_READ_AT_ALL_END MPI_FILE_WRITE_AT_ALL_BEING MPI_FILE_WRITE_AT_ALL_END |
|
|
individual file pointers |
blocking |
MPI_FILE_READ MPI_FILE_WRITE |
MPI_FILE_READ_ALL MPI_FILE_WRITE_ALL |
|
nonblocking |
MPI_FILE_IREAD MPI_FILE_IWRITE |
MPI_FILE_READ_ALL_BEGIN MPI_FILE_READ_ALL_END MPI_FILE_WRITE_ALL_BEGIN MPI_FILE_WRITE_ALL_END |
|
|
shared file pointers |
blocking |
MPI_FILE_READ MPI_FILE_WRITE |
MPI_FILE_READ_ORDERED MPI_FILE_WRITE_ORDERED |
|
nonblocking |
MPI_FILE_IREAD_SHARED MPI_FILE_IWRITE_SHARE |
MPI_FILE_READ_ORDERED_BEGIN MPI_FILE_READ_ORDERED_END MPI_FILE_WRITE_ ORDERED_BEGIN MPI_FILE_WRITE_ORDERED_END |
|
九、硬件层面
十、MPI应用:Jacobi迭代
Jacobi迭代法就是众多迭代法中比较早且较简单的一种,Jacobi迭代法的计算公式简单,每迭代一次只需计算一次矩阵和向量的乘法,且计算过程中原始矩阵
A
始终不变,比较容易并行计算。
本节通过Jacobi迭代求解线性方程组来展示MPI并行程序开发的相关知识点。
10.1 Jacobi迭代
对于
非奇异
线性方程组
令
,则有
,由此可以得到Jacobi迭代公式
其中,
。
即
10.2 程序实现
// jacobi.cpp : This file contains the 'main' function. Program execution begins and ends there.
//
#include <iostream>
#include <cassert>
#include <mpi.h>
struct Matrix
{
public:
//-Constructor
Matrix(int m, int n)
: nRows(m)
, nCols(n)
{
data = (double*)malloc(nRows * nCols * sizeof(double));
}
~Matrix()
{
if (data) free(data);
}
//-Access
double operator()(const int i, const int j) const
{
//check(i, j);
return data[nCols * i + j];
}
double& operator()(const int i, const int j)
{
//check(i, j);
return data[nCols * i + j];
}
void check(const int i, const int j)
{
assert(i < nRows && j < nCols);
}
//-verbose
void print(const char* desc)
{
std::cout << std::endl << "=====================================================" << std::endl;
std::cout << desc << std::endl;;
std::cout << "data = " << std::endl;
std::cout << "[" << std::endl;
for (int i = 0; i < nRows; ++i)
{
for (int j = 0; j < nCols; ++j)
{
std::cout << "\t" << data[i * nCols + j];
}
std::cout << std::endl;
}
std::cout << "]" << std::endl << std::endl;
}
public:
double* data;
int nRows, nCols;
};
int main(int argc, char **argv)
{
::MPI_Init(&argc, &argv);
int size;
::MPI_Comm_size(MPI_COMM_WORLD, &size);
int myid;
::MPI_Comm_rank(MPI_COMM_WORLD, &myid);
int n = 3;
Matrix A(n, n), b(n, 1), x(n, 1);
if (myid == 0)
{
// Matrix A
A(0, 0) = 1.0; A(0, 1) = 2.0; A(0, 2) = -2.0;
A(1, 0) = 1.0; A(1, 1) = 1.0; A(1, 2) = 1.0;
A(2, 0) = 2.0; A(2, 1) = 2.0; A(2, 2) = 1.0;
// R.H.S
b(0, 0) = 1.0;
b(1, 0) = 1.0;
b(2, 0) = 2.0;
// Solution
x(0, 0) = 0.0;
x(1, 0) = 0.0;
x(2, 0) = 0.0;
}
::MPI_Bcast(A.data, A.nRows * A.nCols, MPI_DOUBLE, 0, MPI_COMM_WORLD);
::MPI_Bcast(b.data, b.nRows * b.nCols, MPI_DOUBLE, 0, MPI_COMM_WORLD);
::MPI_Bcast(x.data, x.nRows * x.nCols, MPI_DOUBLE, 0, MPI_COMM_WORLD);
//if (myid == 1)
//{
// A.print("Process 1 prints matrix A");
// b.print("Process 1 prints matrix b");
//}
int row_begin = myid * ( n / size + 1);
int row_end = (myid + 1) * (n / size + 1);
double err = FLT_MAX;
int iter = 0;
//std::cout << "Process " << myid << ": row_being = " << row_begin << ", row_end = " << row_end << std::endl;
do
{
// compute new x^{k+1} using Jacobi method
for (int i = row_begin; i < row_end; ++i)
{
if (i >= n)
{
break;
}
x(i, 0) = b(i, 0);
for (int j = 0; j < i; ++j)
{
x(i, 0) = x(i, 0) - A(i, j) * x(j, 0);
}
for (int j = i + 1; j < n; ++j)
{
x(i, 0) = x(i, 0) - A(i, j) * x(j, 0);
}
x(i, 0) = x(i, 0) / A(i, i);
}
//::MPI_Barrier(MPI_COMM_WORLD);
Matrix x_new(3, 1);
// Gather the new x^{k+1}
::MPI_Gather(x.data + row_begin, row_end - row_begin, MPI_DOUBLE, x_new.data, row_end - row_begin, MPI_DOUBLE, 0, MPI_COMM_WORLD);
// Update the x^{k} <- x^{k+1}
::MPI_Bcast(x_new.data, x.nRows * x.nCols, MPI_DOUBLE, 0, MPI_COMM_WORLD);
::memcpy(x.data, x_new.data, n * sizeof(double));
}
while (++iter < 10);
::MPI_Barrier(MPI_COMM_WORLD);
if (myid == 0)
{
x.print("The solution x is ");
}
::MPI_Finalize();
}
十一、MPI程序优化
使用非阻塞通信,实现计算-通信重叠。
十二、讨论
Q1
.请思考MPI_ANY_SOURCE、MPI_ANY_TAG、MPI_BYTE、MPI_PACKED的应用场景。
Q2
. 分析下界标记类型MPI_TYPE_LB、上界标记类型MPI_TYPE_UB的用途。
Q3
. 试阐述MPI-2 并行I/O的实现原理。
Q4
. 按照文件读写定位方式,MPI-2 并行I/O API可以分为explicit offset、individual file pointer、shared file pointer等三类,请分析三类并行I/O的适用场景。
Q5
. MPI-2中
MPI_FILE_READ_AT/MPI_FILE_WRITE_AT与POSIX C read有何区别?
附录A:安装MS-MPI
A.1 下载与安装
通过
Microsoft MPI
下载msmpisetup.exe、msmpisetup.exe,然后依次安装。
| 安装包 | 默认安装路径 |
| msmpisetup.exe | C:\Program Files\Microsoft MPI |
| msmpisetup.exe | C:\Program Files (x86)\Microsoft SDKs\MPI |
A.2 环境配置
Visual Studio 2019中新建C++控制台项目,然后修改以下项目属性




A.3 测试
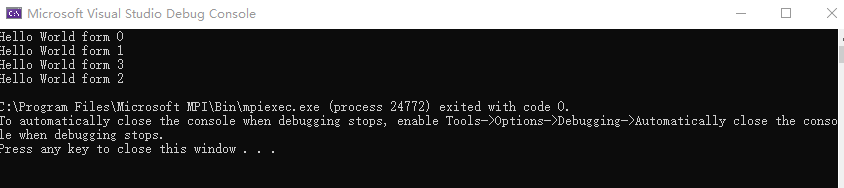
编写如下代码,
#include <iostream>
#include "mpi.h"
int main(const int argc,char **argv)
{
::MPI_Init(&argc, &argv);
int myid;
::MPI_Comm_rank(MPI_COMM_WORLD, &myid);
std::cout << "Hello World form " << myid << std::endl;
//std::cout << "Hello World!\n";
::MPI_Finalize();
return 0;
}编译并进行运行,验证测试是否成功。
文献资料
Peter Pacheco. An Introduction to Parallel Programming. Elsevier, 2011.
张林波. MPI并行编程讲稿. 中国科学院数学与系统科学研究院, 2006.
都志辉. 高性能计算并行编程技术-MPI并行程序设计. 清华大学出版社, 2001.
张武生. MPI并行程序设计实例教程. 清华大学出版社, 2009.
Walfredo Cirne. On Interfaces to Parallel I/O Subsystems.
徐树方. 数值线性代数. 北京大学出版社, 2013.
网络资料
Github MPICH
![]()
https://github.com/pmodels/mpich
OpenMPI
![]()
https://www.open-mpi.org/
DeinoMPI
![]()
http://mpi.deino.net/index.htm
MPI系列: 并行IO性能优化究竟是怎么玩的呢?
![]()
https://blog.csdn.net/BtB5e6Nsu1g511Eg5XEg/article/details/88084041
MPI如何对Lustre/GPFS文件系统优化?
![]()
https://cloud.tencent.com/developer/news/399820