软件工程中应用的15种图:
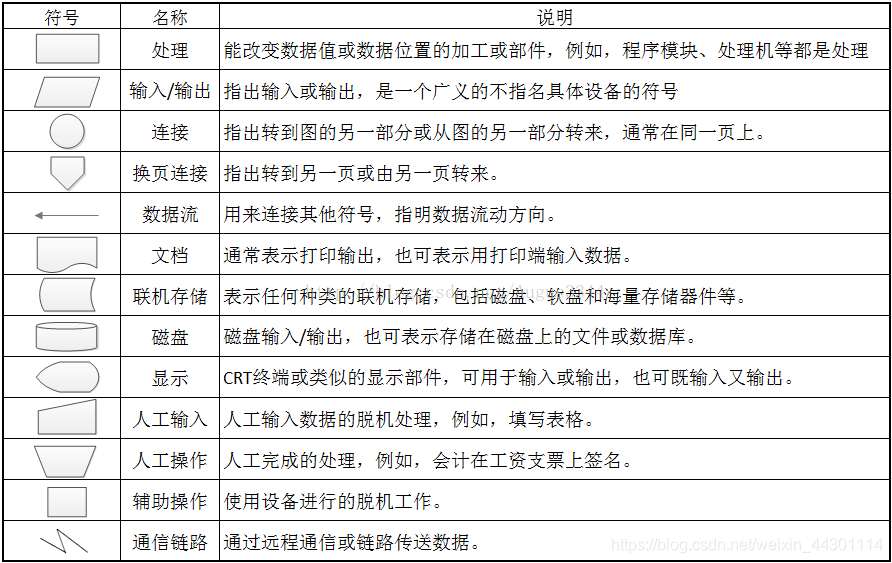
1、系统流程图
不论什么程序设计语言,程序设计都有3种基本结构:顺序结构、选择结构和循环结构。三种基本结构的特点: 一个入口,一个出口,不出现死循环和死语句。
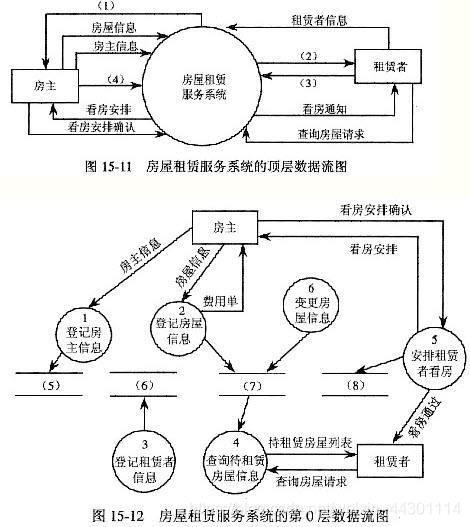
2、数据流图或数据流程图(Data Flow Diagram),缩写为DFD
数据流图是结构化分析方法中使用的工具,它以图形的方式描绘数据在系统中流动和处理的过程,由于它只反映系统必须完成的逻辑功能,所以它是一种功能模型
数据流图DFD是描述系统中数据流程的一种图形工具,它标志了一个系统的逻辑输入和逻辑输出,以及把逻辑输入转换逻辑输出所需的加工处理。
值得注意的是,数据流图不是传统的流程图或框图,数据流也不是控制流。数据流图是从数据的角度来描述一个系统,而框图是从对数据进行加工的工作人员的角度来描述系统。
DFD显示系统将输入和输出什么样的信息,数据如何通过系统前进以及数据将被存储在何处。它不显示关于进程计时的信息,也不显示关于进程将按顺序还是并行运行的信息,而不像传统的关注控制流的结构化流程图,或者UML活动工作流程图,它将控制流和数据流作为一个统一的模型。
数据流图从数据传递和加工的角度,以图形的方式刻画数据流从输入到输出的移动变换过程。
数据流程图包括:
a.指明数据存在的数据符号,这些数据符号也可指明该数据所使用的媒体;
b.指明对数据执行的处理的处理符号,这些符号也可指明该处理所用到的机器功能;
c.指明几个处理和(或)数据媒体之间的数据流的流线符号;
d.便于读、写数据流程图的特殊符号。
在处理符号的前后都应是数据符号。数据流程图以数据符号开始和结束,数据流图有两种典型结构,一是变换型结构,它所描述的工作可表示为输入、主处理和输出,呈线性状态。另一种是事务型结构,这种数据流图呈束状,即一束数据流平行流入或流出,可能同时有几个事务要求处理。
数据流程图中有以下几种主要元素:
→: 数据流。数据流是数据在系统内传播的路径,因此由一组成分固定的数据组成.如订票单由旅客姓名、年龄、单位、身份证号、日期、目的地等数据项 组成.由于数据流是流动中的数据,所以必须有流向,除了与数据存储之间的数据流不用命名外,数据流应该用名词或名词短语命名.
□: 数据源(终点).代表系统之外的实体,可以是人、物或其他软件系统
○: 对数据的加工(处理).加工是对数据进行处理的单元,它接收一定的数据输入,对其进行处理,并产生输出
〓: 数据存储.表示信息的静态存储,可以代表文件、文件的一部分、数据库的元素等
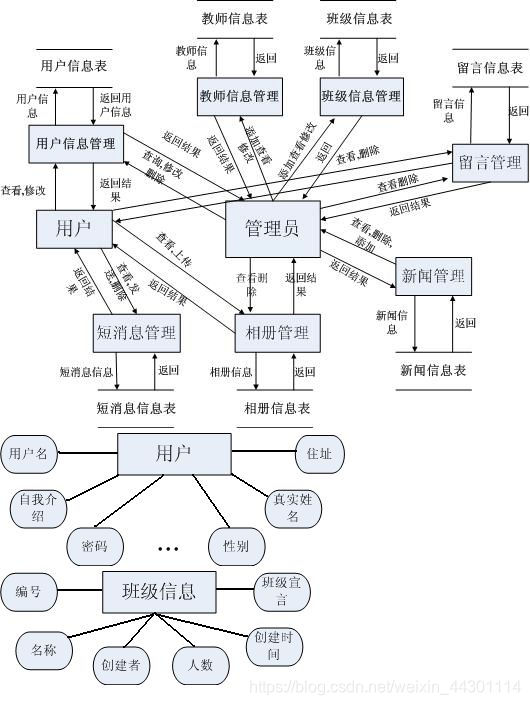
3、数据字典
数据字典是指对数据的数据项、数据结构、数据流、数据存储、处理逻辑等进行定义和描述,其目的是对数据流程图中的各个元素做出详细的说明,使用数据字典为简单的建模项目。简而言之,数据字典是描述数据的信息集合,是对系统中使用的所有数据元素的定义的集合。
数据字典(data dictionary)是对于数据模型中的数据对象或者项目的描述的集合,这样做有利于程序员和其他需要参考的人。分析一个用户交换的对象系统的第一步就是去辨别每一个对象,以及它与其他对象之间的关系。这个过程称为数据建模,结果产生一个对象关系图。当每个数据对象和项目都给出了一个描述性的名字之后,它的关系再进行描述(或者是成为潜在描述关系的结构中的一部分),然后再描述数据的类型(例如文本还是图像,或者是二进制数值),列出所有可能预先定义的数值,以及提供简单的文字性描述。这个集合被组织成书的形式用来参考,就叫做数据字典。
据字典在需求分析阶段被建立。
数据字典是一个预留空间,一个数据库,这是用来储存信息数据库本身。
数据字典可能包含的信息,例如:
数据库设计资料
数据内部储存的SQL程序
用户权限
用户统计
数据库的过程中的信息
数据库增长统计
数据库性能统计
数据字典则是系统中各类数据描述的集合,是进行详细的数据收集和数据分析所获得的主要成果。
数据字典通常包括数据项\数据结构\数据流\数据存储和处理过程五个部分。
其中数据项是数据的最小组成单位,若干个数据项可以组成一个数据结构。数据字典通过对数据项和数据结构的定义,来描述数据流、数据存储的逻辑内容。
数据字典是关于数据的信息的集合,也就是对数据流图中包含的所有元素的定义的集合.
数据字典还有另一种含义,是在数据库设计时用到的一种工具,用来描述数据库中基本表的设计,主要包括字段名、数据类型、主键、外键等描述表的属性的内容。
以Oracle数据库字典为例:数据字典分为数据字典表和数据字典视图
Oracle数据库字典通常是在创建和安装数据库时被创建的,Oracle数据字典是Oracle数据库系统工作的基础,没有数据字典的支持,Oracle数据库系统就不能进行任何工作。数据字典中的表是不能直接被访问的,但是可以访问数据字典中的视图。
数据字典表里的数据是Oracle系统存放的系统数据,而普通表存放的是用户的数据。为了方便的区别这些表,这些表的名字都是用”
"
结
尾
,
这
些
表
属
于
S
Y
S
用
户
。
数
据
字
典
表
由
"结尾,这些表属于SYS用户。 数据字典表由
”
结
尾
,
这
些
表
属
于
S
Y
S
用
户
。
数
据
字
典
表
由
ORACLE_HOME/rdbms/admin/sql.bsq 脚本创建, 这个脚本里又调用了其他的脚本来创建这些数据字典表。 在那些创建脚本里有基表的创建SQL。
Oracle 对数据字典表的说明:
These underlying tables store information about the database. Only Oracle Database should write to and read these tables. Users rarely access the base tables directly because they are normalized and most data is stored in a cryptic format.
这些数据字典表,只有Oracle 能够进行读写。
SYS用户下的这些数据字典表,存放在system 表空间下面,表名都用”
"
结
尾
,
为
了
便
于
用
户
对
数
据
字
典
表
的
查
询
,
O
r
a
c
l
e
对
这
些
数
据
字
典
都
分
别
建
立
了
用
户
视
图
,
这
样
即
容
易
记
住
,
还
隐
藏
了
数
据
字
典
表
表
之
间
的
关
系
,
O
r
a
c
l
e
针
对
这
些
对
象
的
范
围
,
分
别
把
视
图
命
名
为
D
B
A
X
X
X
X
,
A
L
L
X
X
X
X
和
U
S
E
R
X
X
X
X
。
数
据
字
典
视
图
分
2
类
:
静
态
数
据
字
典
(
静
态
性
能
视
图
)
和
动
态
数
据
字
典
(
动
态
性
能
视
图
)
。
静
态
数
据
字
典
中
的
视
图
分
为
三
类
,
它
们
分
别
由
三
个
前
缀
构
成
:
u
s
e
r
∗
、
a
l
l
∗
、
d
b
a
∗
。
u
s
e
r
∗
:
该
视
图
存
储
了
关
于
当
前
用
户
所
拥
有
的
对
象
的
信
息
。
(
即
所
有
在
该
用
户
模
式
下
的
对
象
)
a
l
l
∗
:
该
视
图
存
储
了
当
前
用
户
能
够
访
问
的
对
象
的
信
息
,
而
不
是
当
前
用
户
拥
有
的
对
象
。
(
与
u
s
e
r
∗
相
比
,
a
l
l
∗
并
不
需
要
拥
有
该
对
象
,
只
需
要
具
有
访
问
该
对
象
的
权
限
即
可
)
d
b
a
∗
:
该
视
图
存
储
了
数
据
库
中
所
有
对
象
的
信
息
。
(
前
提
是
当
前
用
户
具
有
访
问
这
些
数
据
库
的
权
限
,
一
般
来
说
必
须
具
有
管
理
员
权
限
)
这
些
视
图
由
S
Y
S
用
户
创
建
的
,
所
以
使
用
需
要
加
上
S
Y
S
,
为
了
方
便
,
O
r
a
c
l
e
为
每
个
数
据
字
典
表
的
视
图
头
建
立
了
同
名
字
的
公
共
同
义
词
(
p
u
b
l
i
c
s
y
n
o
n
y
m
s
)
.
这
样
简
单
的
处
理
就
省
去
了
写
s
y
s
.
的
麻
烦
。
除
了
静
态
数
据
字
典
中
三
类
视
图
,
其
他
的
字
典
视
图
中
主
要
的
是
V
"结尾,为了便于用户对数据字典表的查询, Oracle对这些数据字典都分别建立了用户视图,这样即容易记住,还隐藏了数据字典表表之间的关系,Oracle针对这些对象的范围,分别把视图命名为DBA_XXXX, ALL_XXXX和USER_XXXX。 数据字典视图分2类:静态数据字典(静态性能视图) 和 动态数据字典(动态性能视图)。 静态数据字典中的视图分为三类,它们分别由三个前缀构成:user_*、 all_*、 dba_*。 user_*:该视图存储了关于当前用户所拥有的对象的信息。(即所有在该用户模式下的对象) all_*:该视图存储了当前用户能够访问的对象的信息, 而不是当前用户拥有的对象。(与user_*相比,all_* 并不需要拥有该对象,只需要具有访问该对象的权限即可) dba_*:该视图存储了数据库中所有对象的信息。(前提是当前用户具有访问这些数据库的权限,一般来说必须具有管理员权限) 这些视图由SYS用户创建的,所以使用需要加上SYS,为了方便, Oracle为每个数据字典表的视图头建立了同名字的公共同义词(public synonyms). 这样简单的处理就省去了写sys.的麻烦。 除了静态数据字典中三类视图,其他的字典视图中主要的是V
”
结
尾
,
为
了
便
于
用
户
对
数
据
字
典
表
的
查
询
,
O
r
a
c
l
e
对
这
些
数
据
字
典
都
分
别
建
立
了
用
户
视
图
,
这
样
即
容
易
记
住
,
还
隐
藏
了
数
据
字
典
表
表
之
间
的
关
系
,
O
r
a
c
l
e
针
对
这
些
对
象
的
范
围
,
分
别
把
视
图
命
名
为
D
B
A
X
X
X
X
,
A
L
L
X
X
X
X
和
U
S
E
R
X
X
X
X
。
数
据
字
典
视
图
分
2
类
:
静
态
数
据
字
典
(
静
态
性
能
视
图
)
和
动
态
数
据
字
典
(
动
态
性
能
视
图
)
。
静
态
数
据
字
典
中
的
视
图
分
为
三
类
,
它
们
分
别
由
三
个
前
缀
构
成
:
u
s
e
r
∗
、
a
l
l
∗
、
d
b
a
∗
。
u
s
e
r
∗
:
该
视
图
存
储
了
关
于
当
前
用
户
所
拥
有
的
对
象
的
信
息
。
(
即
所
有
在
该
用
户
模
式
下
的
对
象
)
a
l
l
∗
:
该
视
图
存
储
了
当
前
用
户
能
够
访
问
的
对
象
的
信
息
,
而
不
是
当
前
用
户
拥
有
的
对
象
。
(
与
u
s
e
r
∗
相
比
,
a
l
l
∗
并
不
需
要
拥
有
该
对
象
,
只
需
要
具
有
访
问
该
对
象
的
权
限
即
可
)
d
b
a
∗
:
该
视
图
存
储
了
数
据
库
中
所
有
对
象
的
信
息
。
(
前
提
是
当
前
用
户
具
有
访
问
这
些
数
据
库
的
权
限
,
一
般
来
说
必
须
具
有
管
理
员
权
限
)
这
些
视
图
由
S
Y
S
用
户
创
建
的
,
所
以
使
用
需
要
加
上
S
Y
S
,
为
了
方
便
,
O
r
a
c
l
e
为
每
个
数
据
字
典
表
的
视
图
头
建
立
了
同
名
字
的
公
共
同
义
词
(
p
u
b
l
i
c
s
y
n
o
n
y
m
s
)
.
这
样
简
单
的
处
理
就
省
去
了
写
s
y
s
.
的
麻
烦
。
除
了
静
态
数
据
字
典
中
三
类
视
图
,
其
他
的
字
典
视
图
中
主
要
的
是
V
视图,之所以这样叫是因为他们都是以V
或
G
V
或GV
或
G
V
开头的。这些视图会不断的进行更新,从而提供了关于内存和磁盘的运行情况,所以我们只能对其进行只读访问而不能修改它们。
Throughout its operation, Oracle Database maintains a set of virtual tables that record current database activity. These views are calleddynamic performance views because they are continuously updated while a database is open and in use. The views, also sometimes calledV$ views。
V
视
图
是
基
于
X
视图是基于X
视
图
是
基
于
X
虚拟视图的。V$视图是SYS用户所拥有的,在缺省状况下,只有SYS用户和拥有DBA系统权限的用户可以看到所有的视图,没有DBA权限的用户可以看到USER_和ALL_视图,但不能看到DBA_视图。与DBA_,ALL,和USER_视图中面向数据库信息相反,这些视图可视的给出了面向实例的信息。
动态性能表用于记录当前数据库的活动,只存于数据库运行期间,实际的信息都取自内存和控制文件。 DBA可以使用动态视图来监视和调节数据。
数据字典的组成:
1、数据项
2、数据结构
3、数据流
4、数据存储
5、处理过程
6、外部实体
数据字典
数据字典是数据库的重要组成部分。它存放有数据库所用的有关信息,对用户来说是一组只读的表。数据字典内容包括:
1、数据库中所有模式对象的信息,如表、视图、簇、及索引等。
2、分配多少空间,当前使用了多少空间等。
3、列的缺省值。
4、约束信息的完整性。
5、用户的名字。
6、用户及角色被授予的权限。
7、用户访问或使用的审计信息。
8、其它产生的数据库信息。
数据库数据字典是一组表和视图结构。它们存放在SYSTEM表空间中。
数据库数据字典不仅是每个数据库的中心。而且对每个用户也是非常重要的信息。用户可以用SQL语句访问数据库数据字典。
关于数据的信息集合,是一种用户可以访问的记录数据库和应用程序元数据的目录,是对数据库内表信息的物理与逻辑的说明
数据字典各部分的描述
①数据项:数据流图中数据块的数据结构中的数据项说明
数据项是不可再分的数据单位。对数据项的描述通常包括以下内容:
数据项描述={数据项名,数据项含义说明,别名,数据类型,长度,
取值范围,取值含义,与其他数据项的逻辑关系}
其中“取值范围”、“与其他数据项的逻辑关系”定义了数据的完整性约束条件,是设计数据检验功能的依据。
若干个数据项可以组成一个数据结构。
②数据结构:数据流图中数据块的数据结构说明
数据结构反映了数据之间的组合关系。一个数据结构可以由若干个数据项组成,也可以由若干个数据结构组成,或由若干个数据项和数据结构混合组成。对数据结构的描述通常包括以下内容:
数据结构描述={数据结构名,含义说明,组成:{数据项或数据结构}}
③数据流:数据流图中流线的说明
数据流是数据结构在系统内传输的路径。对数据流的描述通常包括以下内容:
数据流描述={数据流名,说明,数据流来源,数据流去向,
组成:{数据结构},平均流量,高峰期流量}
其中“数据流来源”是说明该数据流来自哪个过程,即数据的来源。“数据流去向”是说明该数据流将到哪个过程去,即数据的去向。“平均流量”是指在单位时间(每天、每周、每月等)里的传输次数。“高峰期流量”则是指在高峰时期的数据流量。
④数据存储:数据流图中数据块的存储特性说明
数据存储是数据结构停留或保存的地方,也是数据流的来源和去向之一。对数据存储的描述通常包括以下内容:
数据存储描述={数据存储名,说明,编号,流入的数据流,流出的数据流,
组成:{数据结构},数据量,存取方式}
其中“数据量”是指每次存取多少数据,每天(或每小时、每周等)存取几次等信息。“存取方法”包括是批处理,还是联机处理;是检索还是更新;是顺序检索还是随机检索等。
另外“流入的数据流”要指出其来源,“流出的数据流”要指出其去向。
⑤处理过程:数据流图中功能块的说明
数据字典中只需要描述处理过程的说明性信息,通常包括以下内容:
处理过程描述={处理过程名,说明,输入:{数据流},输出:{数据流},
处理:{简要说明}}
其中“简要说明”中主要说明该处理过程的功能及处理要求。功能是指该处理过程用来做什么(并不是怎么样做);处理要求包括处理频度要求,如单位时间里处理多少事务,多少数据量,响应时间要求等,这些处理要求是后面物理设计的输入及性能评价的标准。
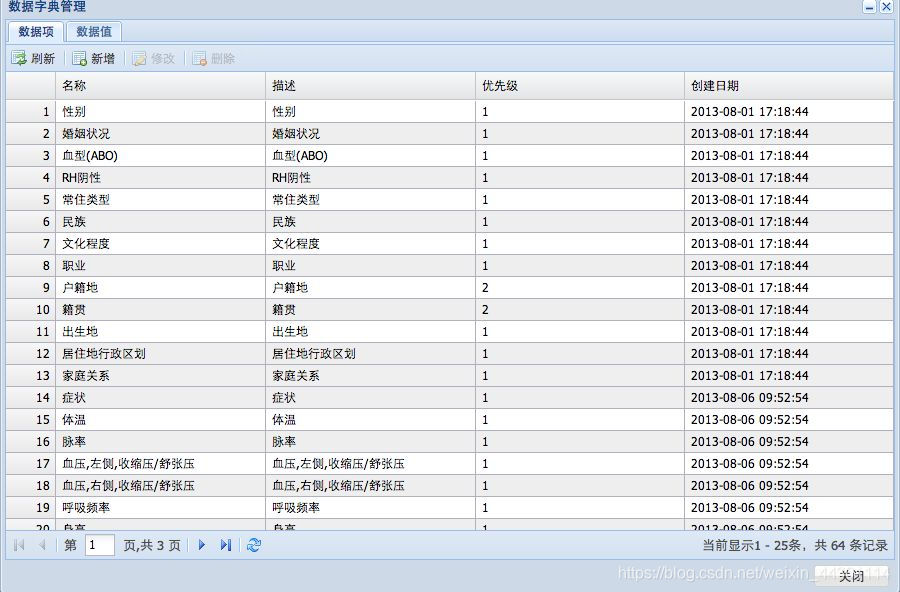
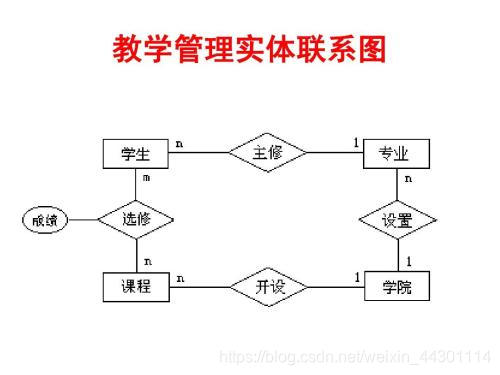
4、实体联系图
E-R图为实体-联系图,提供了表示实体型、属性和联系的方法,用来描述现实世界的概念模型。
构成E-R图的基本要素是实体型、属性和联系。
实体
实体是现实中存在的对象,有具体的,也有抽象的;有物理上存在的,也有概念性的;例如,学生、课程,等等。它们的特征是可以互相区别,否则就会被认为是同一对象。凡是可以互相区别、又可以被人们识别的事、物、概念等统统可以被抽象为实体。数据流图中的数据存贮就是一种实体。实体可以分为独立实体和从属实体或弱实体,独立实体是不依赖于其它实体和联系而可以独立存在的实体,如图1.9中的“学生档案”、“课程档案”等等,独立实体常 常被直接简称为实体;从属实体是这样一类实体,其存在依赖于其它实体和联系,在实体联系图中用带圆角的矩形框表示,例如图1.9中的“注册记录”是从属实体,它的存在依赖于实体 “学生档案”和联系“注册”,“选课单”也是从属实体,它的存在依赖于实体“学生档案”、“课程档案”和联系“选课”。
联系
实体之间可能会有各种关系。例如,“学生”与“课程”之间有“选课”的关系。这种实体和实体之间的关系被抽象为联系。在实体联系图中,联系用联结有关实体的菱形框表示,如图1.9所示。联系可以是一对一(1:1),一对多(1:N)或多对多(M:N)的,这一点在实体联系图中 也应说明。例如在大学教务管理问题中,“学生”与“课程”是多对多的“选课”联系联系。
属性
实体一般具有若干特征,这些特征就称为实体的属性,例如图1.9中的实体“学生”,具 有学号、姓名、性别、出生日期和系别等特征,这些就是它的属性。
联系也可以有属性,例如学生选修某门课程学期,它既不是学生的属性,也不是课程的属性,因为它依赖于某个特定的学生,又依赖于某门特定的课程,所以它是学生与课程之间的联系“选课”的属性。在图1.9中,联系“选课”的属性被概括在从属实体“选课单”中。联系 具有属性这一概念对于理解数据的语义是非常重要的。
重要概念编辑
主键
如果实体的某一属性或某几个属性组成的属性组的值能唯一地决定该实体其它所有属性的值,也就是能唯一地标识该实体,而其任何真子集无此性质,则这个属性或属性组称为实体键。如果一个实体有多个实体键存在,则可从其中选一个最常用到的作为实体的主键。例如实体“学生”的主键是学号,一个学生的学号确定了,那么他的姓名、性别、出生日期和系别等属性也就确定了。在实体联系图中,常在作为主键的属性或属性组与相应实体的联线上加一短垂线表 示。
外键
如果实体的主键或属性(组)的取值依赖于其它实体的主键,那么该主键或属性(组)称为外键。例如,从属实体“注册记录”的主键“学号”的取值依赖于实体“学生”的主键“学号”,“选课单”的主键“学号”和“课程号”的取值依赖于实体“学生”的主键“学号”和实体“课程”的主键“课程号”,这些主键和属性就是外键。
属性域
属性可以是单值的,也可以是多值的。例如一个人所获得的学位可能是多值的。当某个属性对某个实体不适应或属性值未知时,可用空缺符NULL表示。
在画实体联系图时,为了使得图形更加清晰、易读易懂,可以将实体和实体的属性分开来画, 并且对实体进行编号。允许包括其它组合属性意味着属性可以是一个层次结构,通讯地址就是一种具有层次结构的属性。
要素:
实体型:用矩形表示,矩形框内写明实体名;
属性:用椭圆形或圆角矩形表示,并用无向边将其与相应的实体连接起来;多值属性由双线连接;主属性名称下加下划线;
联系:用菱形表示,菱形框内写明联系名,并用无向边分别与有关实体连接起来,同时在无向边旁标上联系的类型
在E-R图中要明确表明1对多关系,1对1关系和多对多关系:
1对1关系在两个实体连线方向写1;
1对多关系在1的一方写1,多的一方写N
多对多关系则是在两个实体连线方向各写N,M
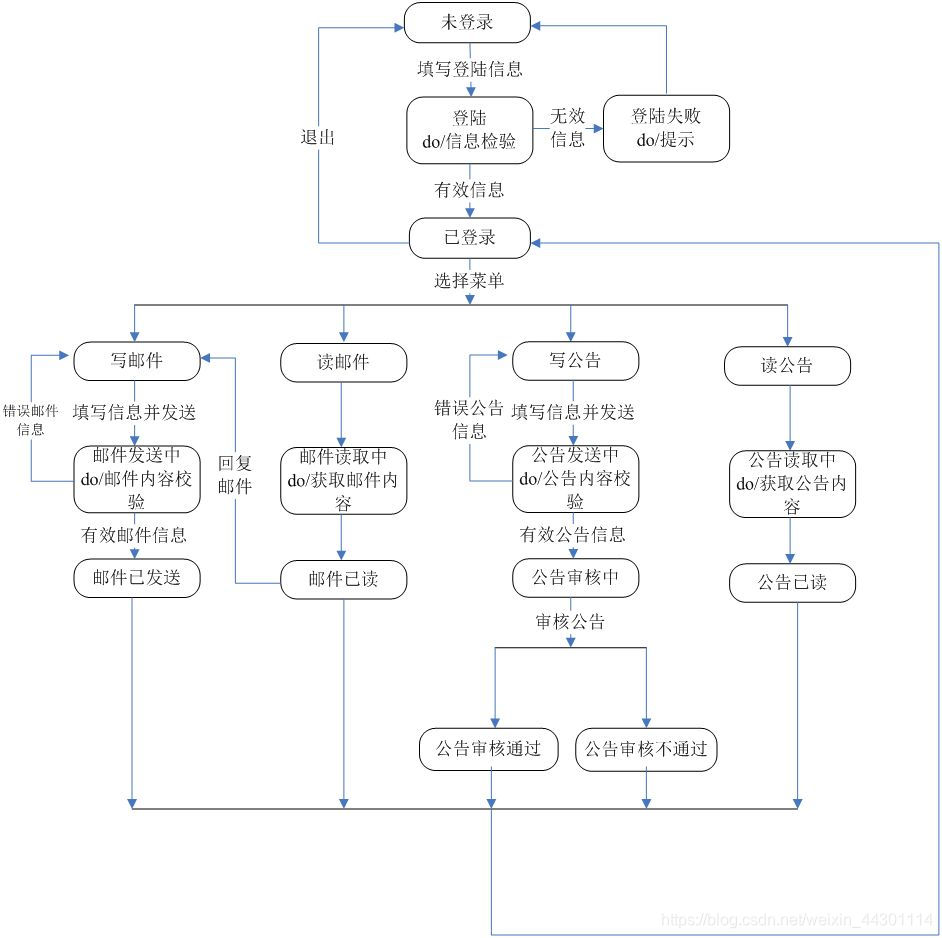
5、状态转换图
通过描绘系统的状态及引起系统状态转换的事件,来表示系统的行为。此外状态转换图还指明了作为特定事件的结果系统将做哪些动作(例如,处理数据)。因此状态转换图提供了行为建模机制。
在状态转换图中,每一个节点代表一个状态,其中双圈是终结状态。许多单片机教材上对工作模式的表达通常采用状态图的形式。
状态转换图是软件测试中书写测试用例时一种不常用的方法。
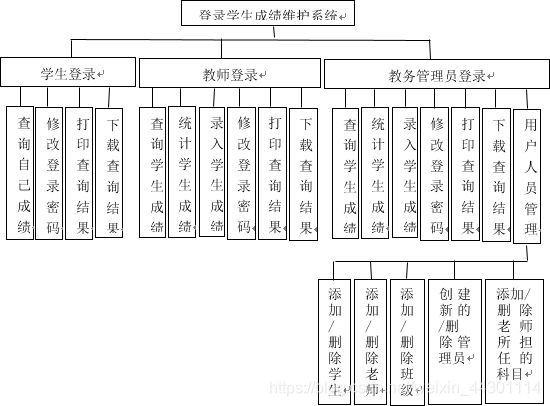
6、层次方框图
层次方框图即层次模块机构图。层次模块结构图(或称结构图structure chart)是1974年由W.Steven等人从结构化设计(structured design)的角度提出的一种工具。它的基本做法是将系统划分为若干子系统,子系统下再划分为若干的模块,大模块内再分小模块,而模块是指具备有输入输出、逻辑功能、运行程序和内部数据四种属性的一组程序。
层次模块结构图主要关心的是模块的外部属性,即上下级模块、同级模块之间的数据传递和调用关系,而并不关心模块的内部。换句话说也就是只关心它是什么,它能够做什么的问题,而不关心它是如何去做的(这一部分内容由下面的IPO图解决)。
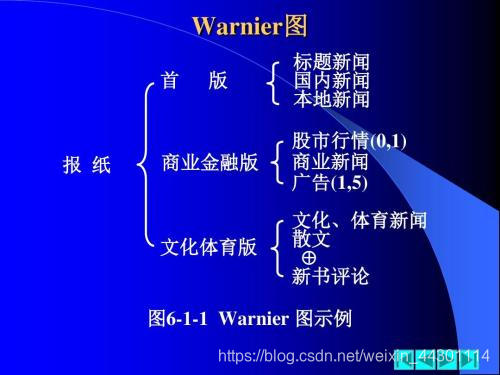
7、Warnier图
Warnier图是表示数据层次结构的一种图形工具,它用树形结构来描绘数据结构。它还能指出某一类数据或某一数据元素重复出现的次数,并能指明某一特定数据在某一类数据中是否是有条件的出现。在进行软件设计时,从Warnier图入手,能够很容易转换成软件的设计描述。以报纸的自动编辑系统为例。通常报纸的版面采用以下格式。
头版部分 社论部分 副刊部分
头条新闻 社论 体育新闻
国内新闻 专栏 商业新闻
当地新闻 读者来信 广告
讽刺漫画
上面给出的报纸概观就是一个数据的层次结构。上面给出了用Warnier图表示的报纸的数据层次结构。在这个Warnier图中,用花括号“{”表示层次关系,在同一括号下,自上到下是顺序排列的数据项。在有些数据项名字后面附加了圆括号,给出该数据项重复的次数。
例如,社论(1,1)表示社论占一栏;专栏(1,3)表示专栏占1到3栏;讽刺漫画(O,1)表示讽刺漫画可有可无,若有就占一栏。另外,Warnier图可以通过细化组合数据项进一步分解信息域。
8、IPO图
IPO图是输入/处理/输出图的简称,它是美国IBM公司提出的一种图形工具,能够方便地描绘输入数据、处理数据和输出数据的关系。
IPO图使用的基本符号少而简单,因此很容易掌握使用这种工具。它的基本形式是在左边的框中列出有关的输人数据,在中间的框中列出主要的处理,在右边的框中列出产生的输出数据。处理框中列出了处理的顺序,但是用这些基本符号还不足以精确描述执行处理的详细情况。
IPO图其他部分的设计和处理都是很容易的,惟独其中的处理过程描述部分较为困难。对于一些处理过程较为复杂的模块,用自然语言描述其功能十分困难,并且对同一段文字描述,不同的人还可能产生不同的理解(即所谓的二义性问题)。目前用于描述模块内部处理过程还有如下几种方法:结构化英语方法、决策树方法、判定表方法和算法描述语言方法。几种方法各有其长处和不同的适用范围,在实际工作中究竟用哪一种方法,需视具体的情况和设计者的习惯而定。
一个软件可由一张总的层次化模块结构图和若干张具体模块内部展开的IPO图组成。前者描述了整个系统的设计结构及各类模块之间的关系,后者描述了某个特定模块内部的处理过程和输入输出关系。
IPO图的主体是算法说明部分,该部分可采用结构化语言、判定表、判定树,也可用N-S图、问题分析图和过程设计语言等工具进行描述,要准确而简明的描述模块执行的细节。
开发人员不仅可以利用IPO图进行模块设计,而且还可以利用它评价总体设计。用户和管理人员可利用IPO图编写、修改和维护程序。因而,IPO图是系统设计阶段的一种重要文档资料。
在IPO图中,输入、输出数据来源于数据词典。局部数据项是指个别模块内部使用的数据,与系统的其它部分无关,仅由本模块定义、存贮和使用。注释是对本模块有关问题作必要的说明。

9、层次图
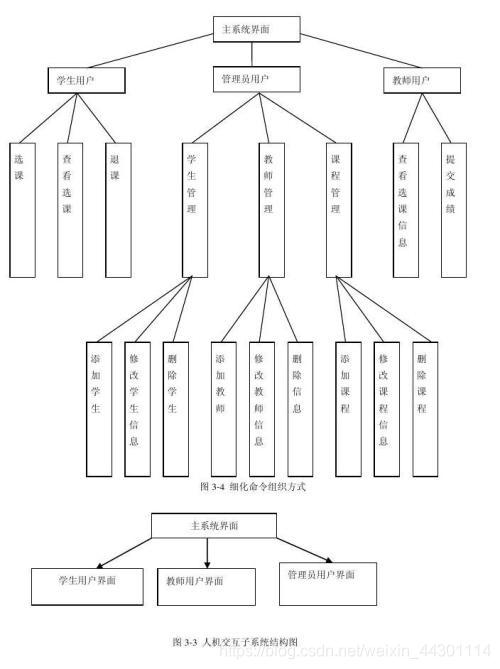
10、HIPO图
HIPO 图由层次结构图和IPO 图两部分构成,前者描述整个系统的设计结构以及各类模块之间的关系,后者描述某个特定模块内部的处理过程和输入/输出关系。
HIPO 图一般由一张总的层次化模块结构图和若干张具体模块内部展开的IPO 图组成。
IPO 图上部反映模块基本信息,即该模块在总体系统中的位置,所涉及的编码方案,数据文件/数据库,编程要求,设计者和使用者等信息。
IPO 图的下部主要用在数据流程分析阶段定义的输入、输出数据流的基础上,对给定模块的输入、输出数据流进行详细定义,重点对该模块的内部处理过程进行描述。输入、输出数据流的描述与标识参考数据流程分析,处理过程描述可用结构化描述语言、判断树、判定表和算法描述语言或伪码等,也可以用其他辅助性工具协助IPO 图的设计。
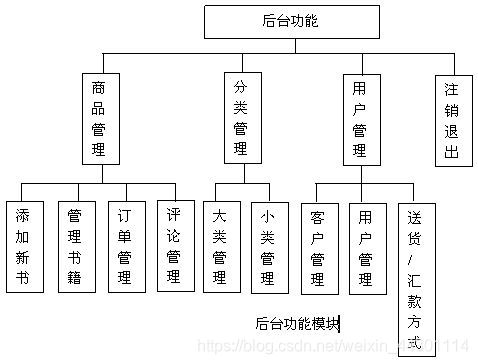
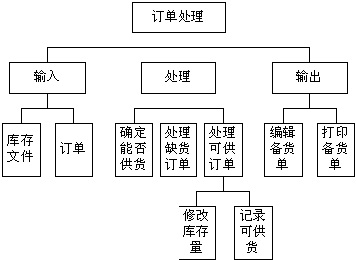
11、结构图
软件结构图是为了反映软件系统中组件之间相互关系和约束的体系结构设计图,称为软件体系结构图更为合适,一般通过分层次或分时间段等方式说明体系结构的各个组成部分的组合关系。
在结构化设计方法中,软件结构图主要分为变换型软件结构图和事务型软件结构图两种。
软件结构包括构成系统的设计元素的描述、设计元素之间的交互、设计元素的组合模式以及在这些模式中的约束。一个系统由一组构件以及它们之间的交互关系组成,这种系统本身又可以成为一个更大的系统的组成元素。
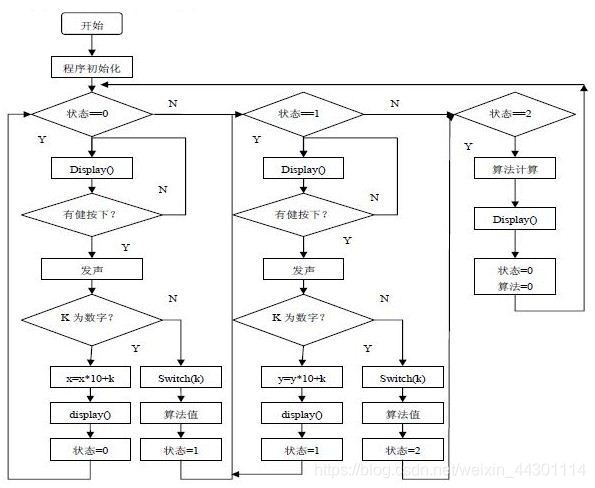
12、程序流程图
程序流程图又称程序框图,是用统一规定的标准符号描述程序运行具体步骤的图形表示。程序框图的设计是在处理流程图的基础上,通过对输入输出数据和处理过程的详细分析,将计算机的主要运行步骤和内容标识出来。程序框图是进行程序设计的最基本依据,因此它的质量直接关系到程序设计的质量。
13、盒图
摆弄数据离散度的一种图形。它对于显示数据的离散的分布情况效果不错。在软件工程中,Nassi和Shneiderman 提出了一种符合结构化程序设计原则的图形描述工具,叫做盒图,也被称为N-S图。
它由五个数值点组成:
最小值(min),下四分位数(Q1),中位数(median),上四分位数(Q3),最大值(max)。也可以往盒图里面加入平均值(mean)。
由于现实数据中总是存在各式各样地“脏数据”,也称为“离群点”,于是为了不因这些少数的离群数据导致整体特征的偏移,将这些离群点单独汇出,而盒图中的胡须的两级修改成最小观测值与最大观测值。这里有个经验,就是最大(最小)观测值设置为与四分位数值间距离为1.5个IQR(中间四分位数极差)。即
1、IQR = Q3-Q1,即上四分位数与下四分位数之间的差,也就是盒子的长度。
2、最小观测值为min = Q1 – 1.5
IQR,如果存在离群点小于最小观测值,则胡须下限为最小观测值,离群点单独以点汇出。如果没有比最小观测值小的数,则胡须下限为最小值。
3、最大观测值为max = Q3 + 1.5
IQR,如果存在离群点大于最大观测值,则胡须上限为最大观测值,离群点单独以点汇出。如果没有比最大观测值大的数,则胡须上限为最大值。
通过盒图,在分析数据的时候,盒图能够有效地帮助我们识别数据的特征:
1、直观地识别数据集中的异常值(查看离群点)。
2、判断数据集的数据离散程度和偏向(观察盒子的长度,上下隔间的形状,以及胡须的长度)。
14、PAD图
PAD是问题分析图(Problem Analysis Diagram)的英文缩写。
与方框图一样,PAD图也只能描述结构化程序允许使用的几种基本结构。发明以来,已经得到一定程度的推广。它用二维树形结构的图表示程序的控制流,以PAD图为基础,遵循机械的走树(Tree Walk)规则就能方便地编写出程序,用这种图转换为程序代码比较容易。
特征:
1)结构清晰,结构化程度高;
2)易于阅读
3)最左端的纵线是程序主干线,对应程序的第一层结构;每增一层PAD图向右扩展一条纵线,帮程序的纵线数等于程序层次数。
4)程序执行:从PAD图最左主干线上端结点开始,自上而下、自左向右依次执行,程序终止于最左主干线。
优点
PAD图
PAD图
1. 使用表示结构优化控制结构的PAD符号所设计出来的程序必然是程序化程序
2. PAD图所描述的程序结构十分清晰。图中最左边的竖线是程序的主线,即第一层控制结构。随着程序层次的增加,PAD图逐渐向右延伸,每增加一个层次,图形向右扩展一条竖线。PAD图中竖线的总条数就是程序的层次数;
3. 用PAD图表现程序逻辑,易读、易懂、易记。PAD图是二维树型结构的图形,程序从图中最左边上端的结点开始执行,自上而下,从左到右顺序执行;
4. 很容易将PAD图转换成高级程序语言源程序,这种转换可由软件工具自动完成,从而可省去人工编码的工作,有利于提高软件可靠性和软件生产率。
5. 既可用于表示程序逻辑,也可用于描述数据结构
6. PAD图的符号支持自顶向下、逐步求精方法的使用。开始时设计者可以定义一个抽象程序,随着设计工作的深入而使用“def”符号逐步增加细节,直至完成详细设计。
PAD图是面向高级程序设计语言的,为FORTRAN,COBOL和PASCAL等每种常用的高级程序设计语言都提供了一整套相应的图形符号。由于每种控制语句都有一个图形符号与之对应,显然将PAD图转换成与之对应的高级语言程序比较容易。
PAD是一种程序结构可见性好、结构唯一、易于编制、易于检查和易于修改的详细设计表现方法。用PAD可以消除软件开发过程中设计与制作的分离,也可消除制作过程中的“属人性”。虽然目前仍需要由人来编制程序,一旦开发的PAD编程自动化系统实现的话,计算机就能从PAD自动编程,到那时程序逻辑就是软件开发过程中人工制作的最终产品。显然在开发时间上大大节省,开发质量上将会大大提高。
缺点:不如流程图易于执行。
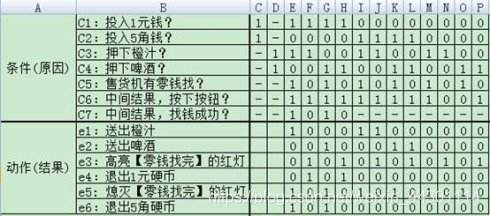
15、判定表、
判定表(Decision table)是另一种表达逻辑判断的工具。与结构化语言和判断树相比,判断表的优点是能把所有条件组合充分地表达出来;其缺点是判定表的建立过程较烦杂,且表达方式不如前两种简便。判定表在用于知识表达中,有许多其他方式所达不到的作用。
判定表通常有以下四个部分组成:
1)条件桩(Condition Stub):在左上部,列出了问题的所有条件。通常认为列出的条件的次序无关紧要。
2)动作桩(Action Stub):在左下部,列出了问题规定可能采取的操作。这些操作的排列顺序没有约束。
3)条件项(Condition Entry):在右上部,列出针对它左列条件的取值。在所有可能情况下的真假值。
4)动作项(Action Entry):在右下部,列出在条件项的各种取值情况下应该采取的动作。
判定表的建立步骤:
1)确定规则的个数.假如有n个条件。每个条件有两个取值(0,1),故有2的n次方种规则。
2)列出所有的条件桩和动作桩。
3)填入条件项。
4)填入动作项。得到初始判定表。
5)简化.合并相似规则(相同动作)。
判定表的优点:
能够将复杂的问题按照各种可能的情况全部列举出来,简明并避免遗漏。因此,利用判定表能够设计出完整的测试用例集合。在一些数据处理问题当中,某些操作的实施依赖于多个逻辑条件的组合,即:针对不同逻辑条件的组合值,分别执行不同的操作。判定表很适合于处理这类问题。