大数据技术体系太庞杂了,基础技术覆盖
数据采集、
数据预处理、
分布式存储、
NOSQL数据库、
多模式计算(批处理、在线处理、实时流处理、内存处理)、
多模态计算(图像、文本、视频、音频)、
数据仓库、
数据挖掘、机器学习、人工智能、深度学习、并行计算、可视化
等各种技术范畴和不同的层面。另外大数据应用领域广泛,各领域采用技术的差异性还是比较大的。
短时间很难掌握多个领域的大数据理论和技术,建议
从应用切入、以点带面
,先从一个实际的应用领域需求,搞定一个一个技术点,有一定功底之后,再举一反三横向扩展,这样学习效果就会好很多。
下面是网上的一些技术资料,以供参考——————————————————————————————-
大数据技术初探

从前几年到现在所谓的大数据时代,移动互联网、物联网、云计算、人工智能、机器人、大数据等前沿信息技术领域,逐个火了一遍,什么是大数据,大数据的技术范畴包括那些,估计很多人都是根据自己所熟悉的领域在盲人摸象。
下文从DT(Data technology,数据技术)技术泛型角度来系统地介绍什么是大数据,包括那些核心技术,各领域之间的关系等等:
首先我们说机器学习,
机器学习(machine learning)
,是计算机科学和统计学的交叉学科,核心目标是通过函数映射、数据训练、最优化求解、模型评估等一系列算法实现,让计算机拥有对数据进行自动分类和预测的功能;机器学习领域包括很多智能处理算法,分类、聚类、回归、相关分析等每类下面都有很多算法进行支撑,如SVM,神经网络,Logistic回归,决策树、EM、HMM、贝叶斯网络、随机森林、LDA等,无论是网络排名的十大算法还是二十大算法,都只能说是冰山一角;总之计算机要智能化,机器学习是核心的核心,深度学习、数据挖掘、商业智能、人工智能,大数据等概念的核心技术就是机器学习,机器学习用于图像处理和识别就是机器视觉,机器学习用于模拟人类语言就是自然语言处理,机器视觉和自然语言处理也是支撑人工智能的核心技术,机器学习用于通用的数据分析就是数据挖掘,数据挖掘也是商业智能的核心技术。
深度学习(deep learning)
,机器学习里面现在比较火的一个子领域,深度学习是已经被研究过几十年的神经网络算法的变种,由于在大数据条件下图像,语音识别等领域的分类和识别上取得了非常好的效果,有望成为人工智能取得突破的核心技术,所以各大研究机构和IT巨头们都投入了大量的人力物力做相关的研究和开发工作。
数据挖掘(data mining)
,是一个很宽泛的概念,类似于采矿,要从大量石头里面挖出很少的宝石,从海量数据里面挖掘有价值有规律的信息同理。数据挖掘核心技术来自于机器学习领域,如深度学习是机器学习一种比较火的算法,当然也可以用于数据挖掘。还有传统的商业智能(BI)领域也包括数据挖掘,OLAP多维数据分析可以做挖掘分析,甚至Excel基本的统计分析也可以做挖掘。关键是你的技术能否真正挖掘出有用的信息,然后这些信息可以提升指导你的决策,如果是那就算入了数据挖掘的门。
人工智能(artifical intelligence)
,也是一个很大的概念,终极目标是机器智能化拟人化,机器能完成和人一样的工作,人脑仅凭几十瓦的功率,能够处理种种复杂的问题,怎样看都是很神奇的事情。虽然机器的计算能力比人类强很多,但人类的理解能力,感性的推断,记忆和幻想,心理学等方面的功能,机器是难以比肩的,所以机器要拟人化很难单从技术角度把人工智能讲清楚。人工智能与机器学习的关系,两者的相当一部分技术、算法都是重合的,深度学习在计算机视觉和棋牌走步等领域取得了巨大的成功,比如谷歌自动识别一只猫,最近谷歌的AlpaGo还击败了人类顶级的专业围棋手等。但深度学习在现阶段还不能实现类脑计算,最多达到仿生层面,情感,记忆,认知,经验等人类独有能力机器在短期难以达到。
最后我们才说大数据(big data),大数据本质是一种方法论,一句话概括,就是通过分析和挖掘全量海量的非抽样数据进行辅助决策。上述技术原来是在小规模数据上进行计算处理,大数据时代呢,只是数据变大了,核心技术还是离不开机器学习、数据挖掘等,另外还需考虑海量数据的分布式存储管理和机器学习算法并行处理等核心技术。总之大数据这个概念就是个大框,什么都能往里装,大数据源的采集如果用传感器的话离不开物联网、大数据源的采集用智能手机的话离不开移动互联网,大数据海量数据存储要高扩展就离不开云计算,大数据计算分析采用传统的机器学习、数据挖掘技术会比较慢,需要做并行计算和分布式计算扩展,大数据要互动展示离不开可视化,大数据的基础分析要不要跟传统商业智能结合,金融大数据分析、交通大数据分析、医疗大数据分析、电信大数据分析、电商大数据分析、社交大数据分析,文本大数据、图像大数据、视频大数据…诸如此类等等范围太广…,总之大数据这个框太大,其终极目标是利用上述一系列核心技术实现海量数据条件下的人类深度洞察和决策智能化!这不仅是信息技术的终极目标,也是人类社会发展管理智能化的核心技术驱动力。
数据分析师的能力体系
如下图:

- 数学知识
数学知识是数据分析师的基础知识。
对于初级数据分析师,了解一些描述统计相关的基础内容,有一定的
公式计算
能力即可,了解常用统计模型算法则是加分。
对于高级数据分析师,
统计模型
相关知识是必备能力,
线性代数
(主要是矩阵计算相关知识)最好也有一定的了解。
而对于数据挖掘工程师,除了
统计学
以外,
各类算法
也需要熟练使用,对数学的要求是最高的。
- 分析工具
对于初级数据分析师,
玩转Excel是必须的,数据透视表和公式使用必须熟练,VBA是加分
。另外,还要学会一个统计分析工具,SPSS作为入门是比较好的。
对于高级数据分析师,
使用分析工具是核心能力
,
VBA基本必备
,SPSS/SAS/R至少要熟练使用其中之一,其他分析工具(如Matlab)视情况而定。
对于数据挖掘工程师……嗯,会
用用Excel
就行了,主要工作要
靠写代码来解决
呢。
- 编程语言
对于初级数据分析师,会写
SQL查询
,有需要的话写写Hadoop和Hive查询,基本就OK了。
对于高级数据分析师,除了
SQL
以外,学习
Python
是很有必要的,用来获取和处理数据都是事半功倍。当然其他编程语言也是可以的。
对于数据挖掘工程师,
Hadoop得熟悉
,
Python/Java
/C++至少得熟悉一门,Shell得会用……总之
编程语言绝对是数据挖掘工程师的最核心能力
了。
- 业务理解
业务理解说是数据分析师
所有工作的基础
也不为过,数据的获取方案、指标的选取、乃至最终结论的洞察,都依赖于数据分析师对业务本身的理解。
对于初级数据分析师,主要工作是
提取数据和做一些简单图表
,以及少量的洞察结论,拥有对
业务的基本了解
就可以。
对于高级数据分析师,需要对
业务有较为深入的了解
,能够基于数据,
提炼出有效观点
,对实际业务能有所帮助。
对于数据挖掘工程师,对
业务有基本了解
就可以,重点还是需要放在发挥自己的
技术能力
上。
- 逻辑思维
这项能力在我之前的文章中提的比较少,这次单独拿出来说一下。
对于初级数据分析师,逻辑思维主要体现在数据分析过程中每一步都有
目的性
,知道自己需要用什么样的
手段
,达到什么样的目标。
对于高级数据分析师,逻辑思维主要体现在
搭建完整有效的分析框架
,了解分析
对象之间的关联关系
,清楚
每一个指标变化的前因后果
,会
给业务带来的影响
。
对于数据挖掘工程师,逻辑思维除了体现在和
业务相关的分析
工作上,还包括
算法逻辑,程序逻辑
等,所以对逻辑思维的要求也是最高的。
- 数据可视化
数据可视化说起来很高大上,其实包括的范围很广,
做个PPT里边放上数据图表也可以算是数据可视化
,所以我认为这是一项普遍需要的能力。
对于初级数据分析师,能用
Excel和PPT
做出基本的图表和报告,能清楚的展示数据,就达到目标了。
对于高级数据分析师,需要探寻更好的数据可视化方法,使用更有效的
数据可视化工具
,根据实际需求做出或简单或复杂,但适合受众观看的数据可视化内容。
对于数据挖掘工程师,了解一些数据
可视化工具
是有必要的,也要根据需求做一些
复杂的可视化图表
,但通常不需要考虑太多美化的问题。
- 协调沟通
对于初级数据分析师,
了解业务、寻找数据、讲解报告
,都需要和不同部门的人打交道,因此
沟通能力
很重要。
对于高级数据分析师,需要开始
独立带项目
,或者
和产品做一些合作
,因此除了沟通能力以外,还需要一些
项目协调能力
。
对于数据挖掘工程师,和人
沟通技术
方面内容偏多,
业务方面
相对少一些,对
沟通协调
的要求也相对低一些。
- 快速学习
无论做数据分析的哪个方向,初级还是高级,都需要有快速学习的能力,
学业务逻辑、学行业知识、学技术工具、学分析框架
……数据分析领域中有学不完的内容,需要大家有一颗时刻不忘学习的心。
以上,就是我对数据分析师能力的总结。
数据分析师的工具体系
一图说明问题

可以从图上看到,
Python在数据分析中的泛用性相当之高
,流程中的各个阶段都可以使用Python。所以作为数据分析师的你如果需要学习一门编程语言,那么强力推荐Python~
以上,本期内容就讲完了。
作者:陈丹奕
链接:
知乎专栏
来源:知乎
HADOOP家族产品技术介绍:
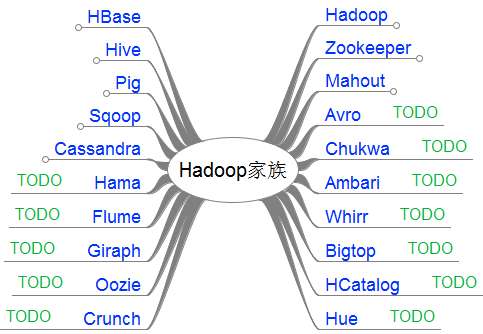
-
Apache Hadoop
: 是Apache开源组织的一个分布式计算
开源框架
,提供了一个分布式文件系统子项目(HDFS)和支持MapReduce分布式计算的软件架构。
-
Apache Hive
: 是基于Hadoop的一个
数据仓库工具
,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
-
Apache Pig
: 是一个基于Hadoop的
大规模数据分析工具
,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。
-
Apache HBase
: 是一个高可靠性、高性能、面向列、可伸缩的
分布式存储系统
,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
-
Apache Sqoop
: 是一个用来将Hadoop和关系型数据库中的
数据相互转移的工具
,可以将一个关系型数据库(MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
-
Apache Zookeeper
: 是一个为分布式应用所设计的分布的、开源的
协调服务
,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度,提供高性能的分布式服务
-
Apache Mahout
:是基于Hadoop的
机器学习和数据挖掘
的一个
分布式框架
。Mahout用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。
-
Apache Cassandra
:是一套开源
分布式NoSQL数据库系统
。它最初由Facebook开发,用于储存简单格式数据,集Google BigTable的数据模型与Amazon Dynamo的完全分布式的架构于一身
-
Apache Avro
: 是一个数据
序列化系统
,设计用于支持数据密集型,大批量数据交换的应用。Avro是新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制
-
Apache Ambari
: 是一种基于
Web的工具
,支持Hadoop集群的供应、
管理和监控
。
-
Apache Chukwa
: 是一个开源的用于监控大型分布式系统的数据收集系统,它可以将各种各样类型的数据收集成适合 Hadoop 处理的文件保存在 HDFS 中供 Hadoop 进行各种 MapReduce 操作。 -
Apache Hama
: 是一个基于HDFS的BSP(Bulk Synchronous Parallel)
并行计算框架
, Hama可用于包括图、矩阵和网络算法在内的大规模、大数据计算。
-
Apache Flume
: 是一个分布的、可靠的、高可用的
海量日志聚合的系统
,可用于日志数据收集,日志数据处理,日志数据传输。
-
Apache Giraph
: 是一个可伸缩的分布式
迭代图处理系统
, 基于Hadoop平台,灵感来自 BSP (bulk synchronous parallel) 和 Google 的 Pregel。
-
Apache Oozie
: 是一个工作流引擎服务器, 用于管理和协调运行在Hadoop平台上(HDFS、Pig和MapReduce)的任务。 -
Apache Crunch
: 是基于Google的FlumeJava库编写的Java库,用于创建MapReduce程序。与Hive,Pig类似,Crunch提供了用于实现如连接数据、执行聚合和排序记录等常见任务的模式库 -
Apache Whirr
: 是一套运行于云服务的类库(包括Hadoop),可提供高度的互补性。Whirr学支持Amazon EC2和Rackspace的服务。 -
Apache Bigtop
: 是一个对Hadoop及其周边生态进行打包,分发和测试的工具。 -
Apache HCatalog
: 是基于Hadoop的
数据表和存储管理
,实现中央的元数据和模式管理,
跨越Hadoop和RDBMS
,利用Pig和Hive提供关系视图。
-
Cloudera Hue
: 是一个基于
WEB的监控和管理系统
,实现对HDFS,MapReduce/YARN, HBase, Hive, Pig的web化操作和管理。
大数据技术资源推介
Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱