一、图像分类
-
什么是图像分类?
任务目标:
给定一张图片,识别图像中的物体是什么

-
数学表示
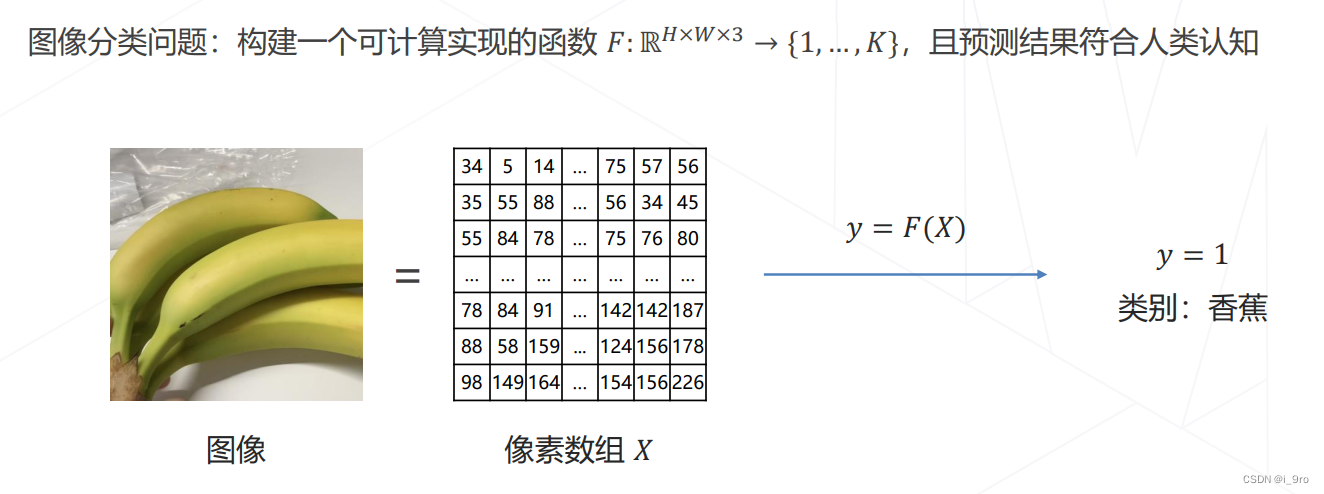
-
难点
语义化,图像的内容是像素整体呈现出的结果,和个别像素的值没有直接关联,难以遵循具体的规则设计算法 -
让机器从数据中学习

局限性:机器学习算法善于处理低维、分布相对简单的数据。图像数据在几十万维的空间中以复杂的方式”缠绕”在一起,常规的机器学习算法难以处理这种复杂数据分布
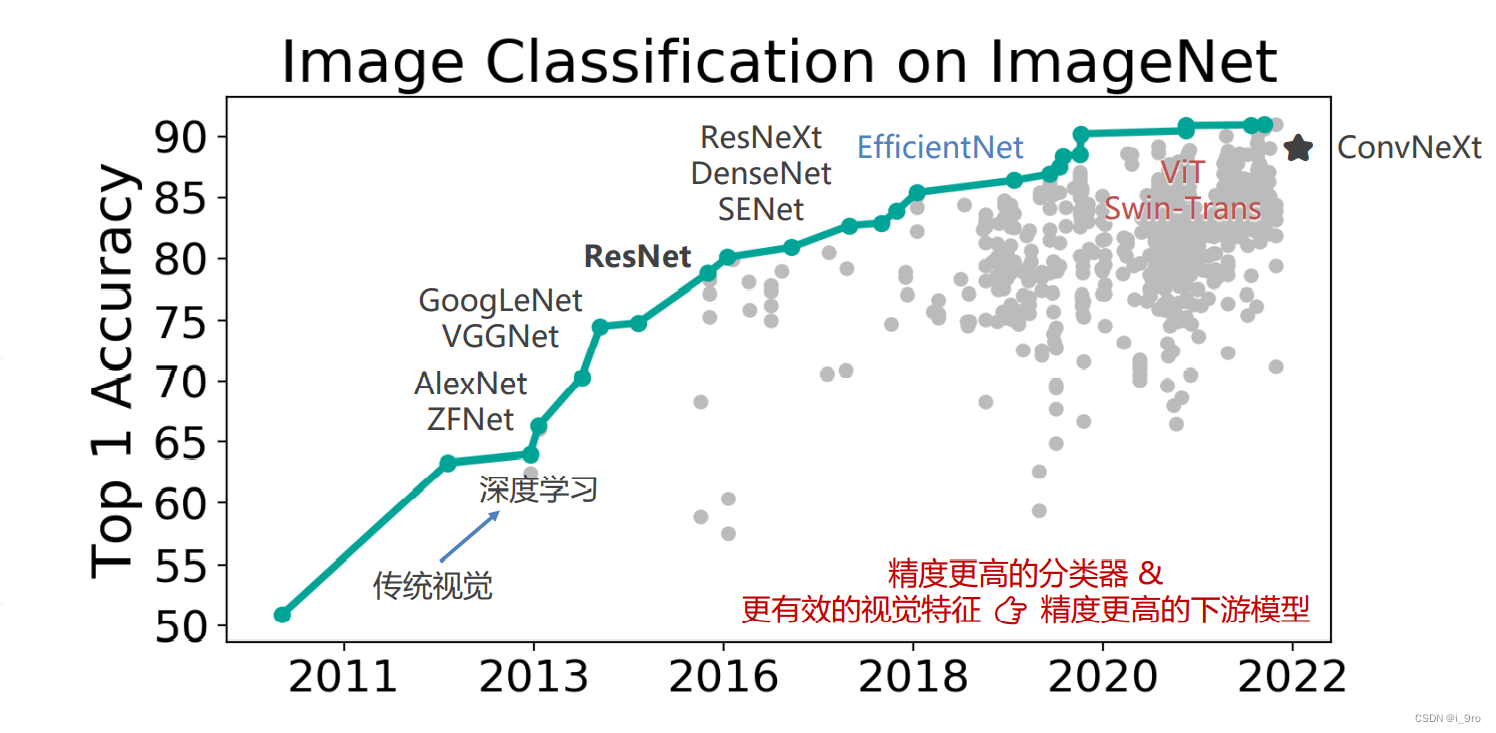
二、图像分类算法进展
-
传统方法:设计图像特征 (1990s~2000s)
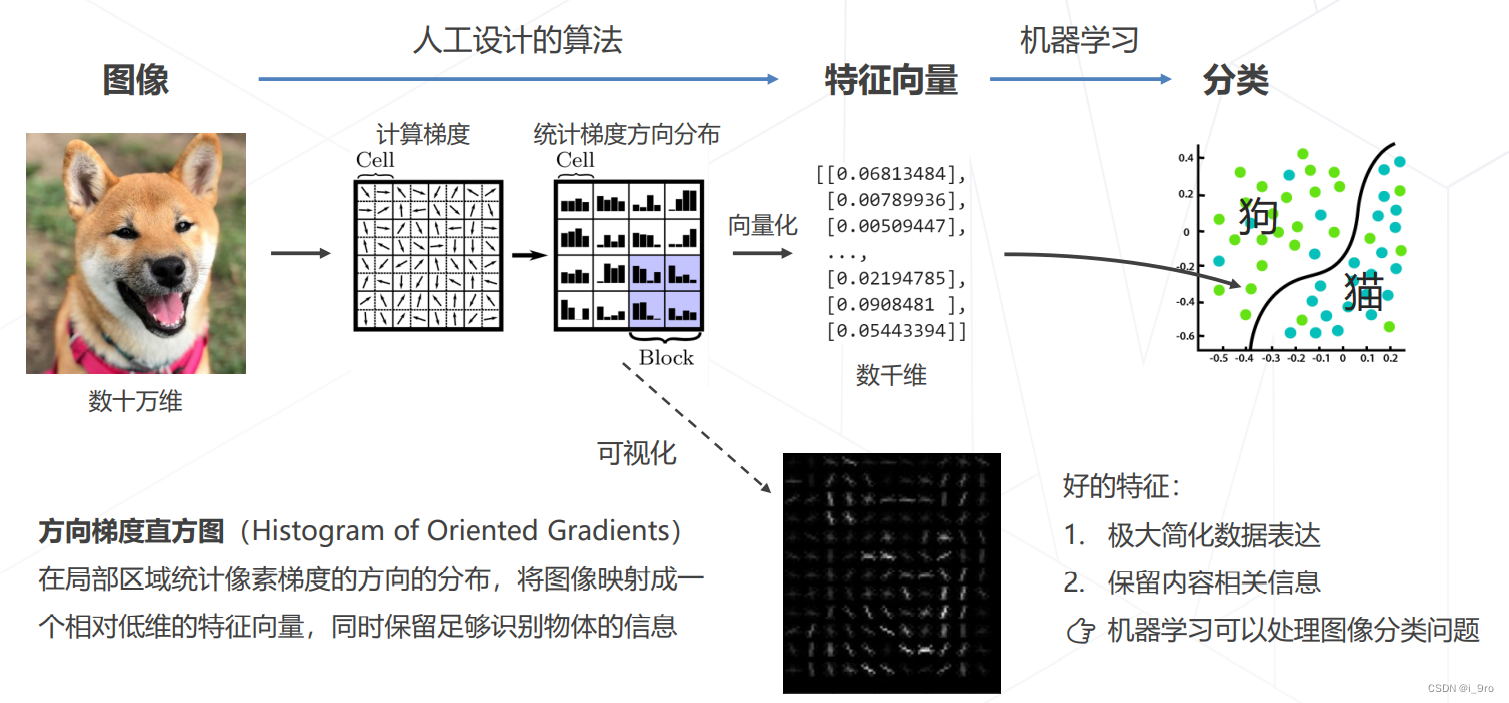
缺点:受限于人类的智慧,手工设计特征更多局限在像素层面的计算,丢失信息过多,在视觉任务上的性能达到瓶颈。
在 ImageNet 图像识别挑战赛里,2010 和 2011 年的冠军队伍都使用了经典的视觉方法,基于手工设计的特征 + 机器学习算法实现图像分类,Top-5 错误率在 25% 上下。 -
从特征工程到特征学习
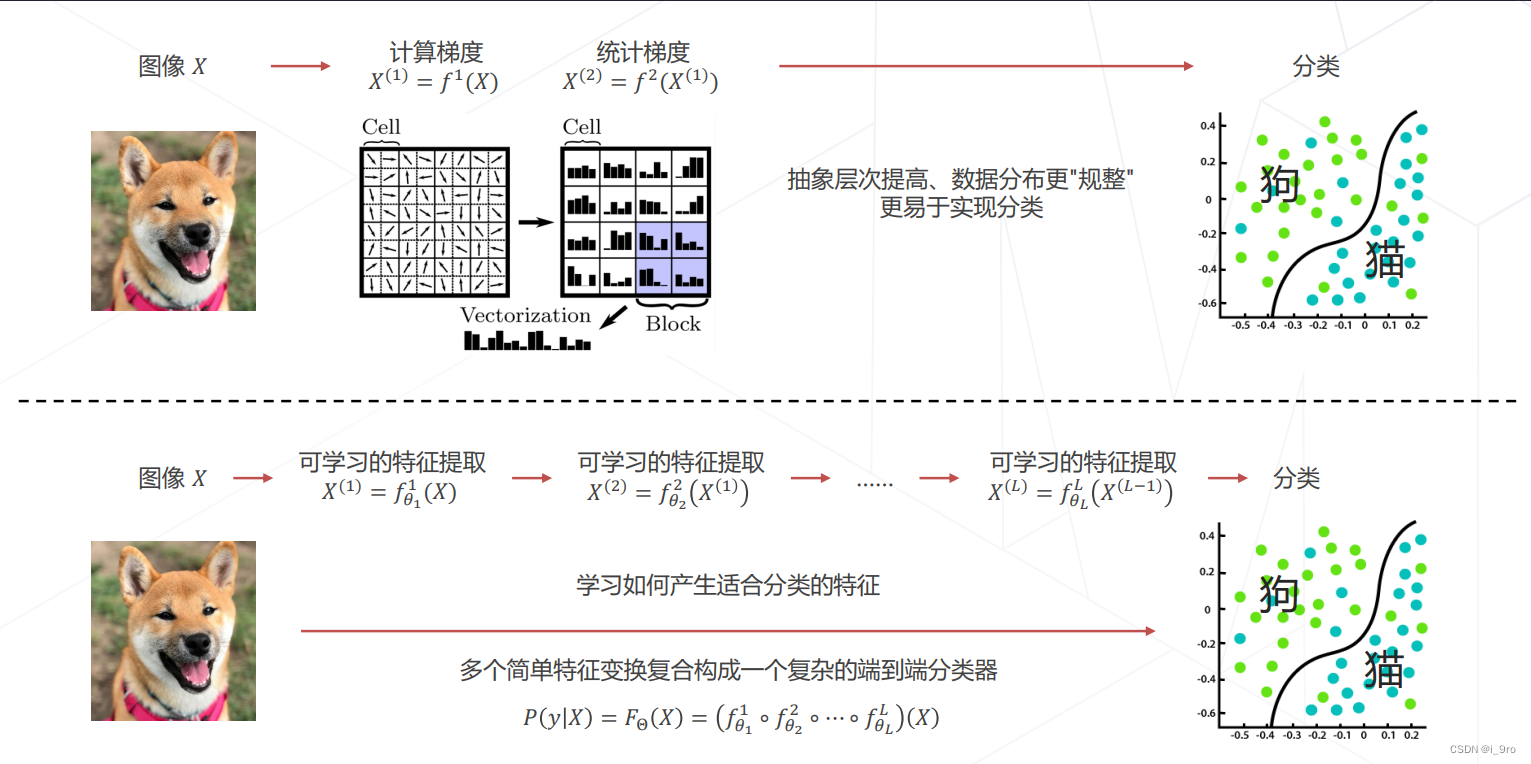
特征提取阶段技术发展:
-
卷积 ? CNN
- 实现一步特征提取
- 特征和图像一样具有二维空间结构
-
多头注意力
- 实现一步特征提取 ? Transformer
-
深度学习时代
AlexNet 的诞生:在 2012 年的竞赛中,来自多伦多大学的团队首次使用深度学习方法,一举将错误率降低至 15.3% ,而传统视觉算法的性能已经达到瓶颈,2015 年,卷积网络的性能超越人类
三、卷积神经网络应用
- AlexNet 2012
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097–1105, 201
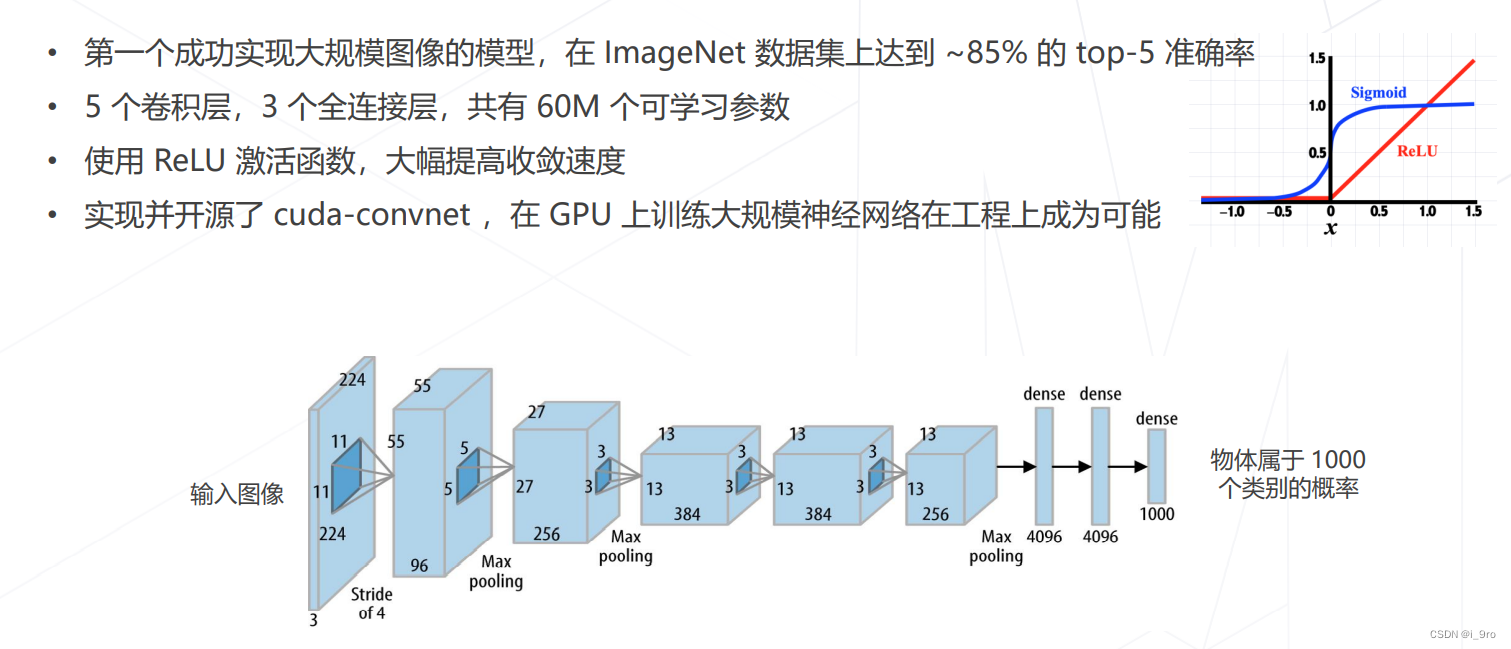
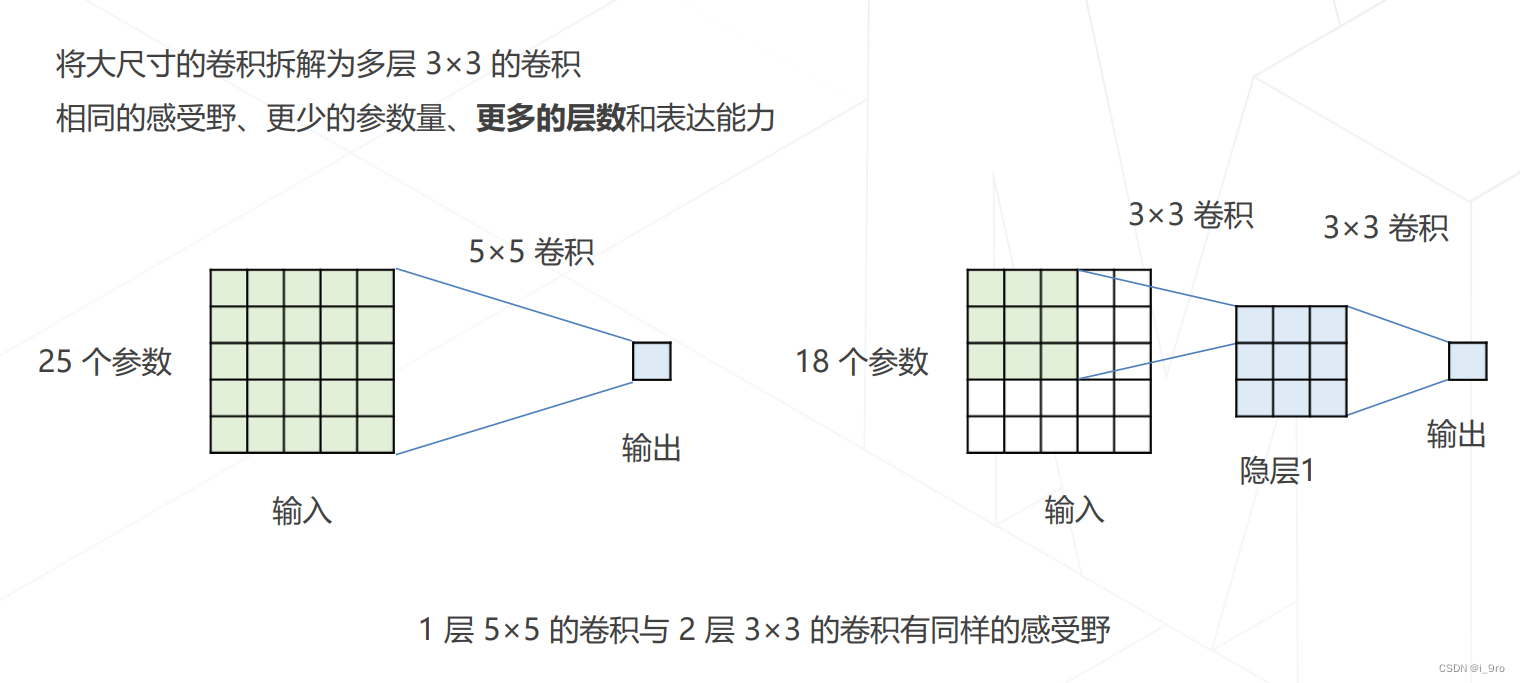
此后,卷积神经网络逐渐向网络层数增加发展
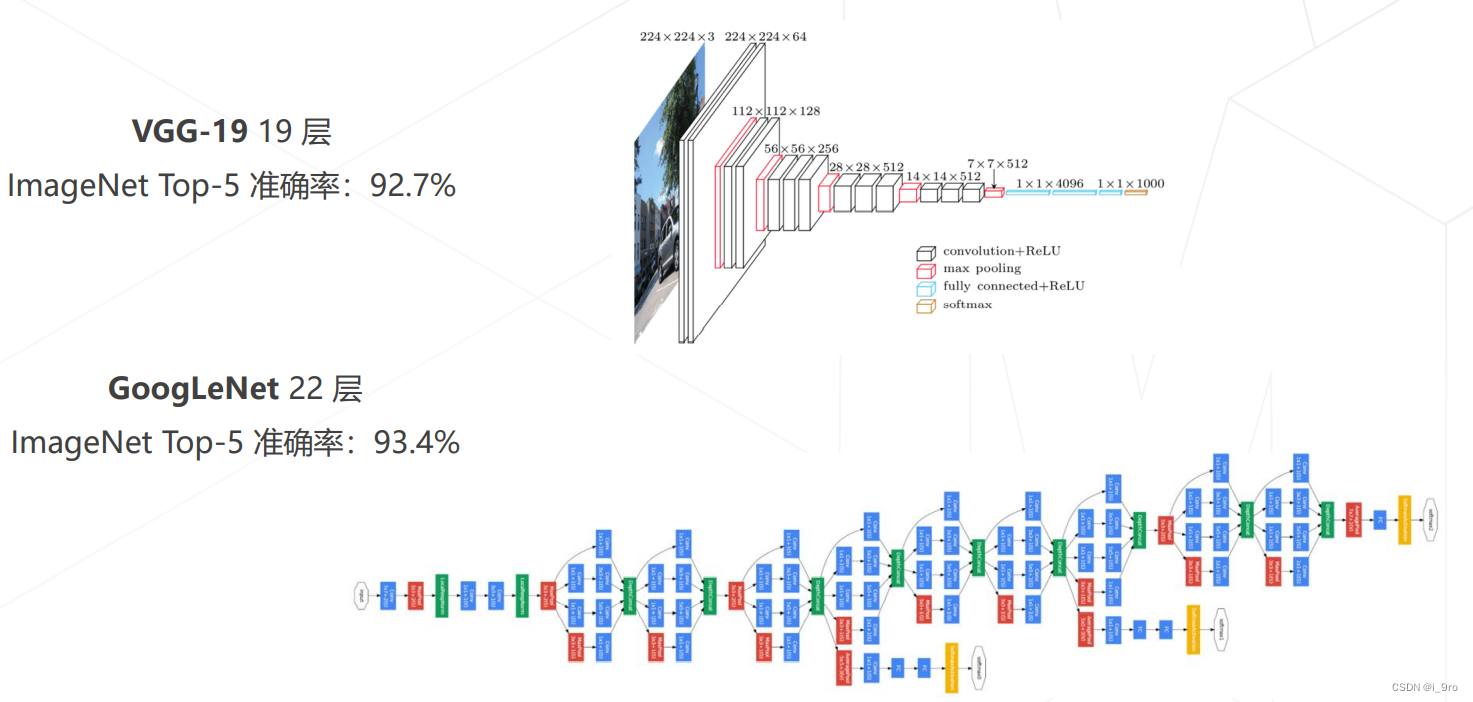
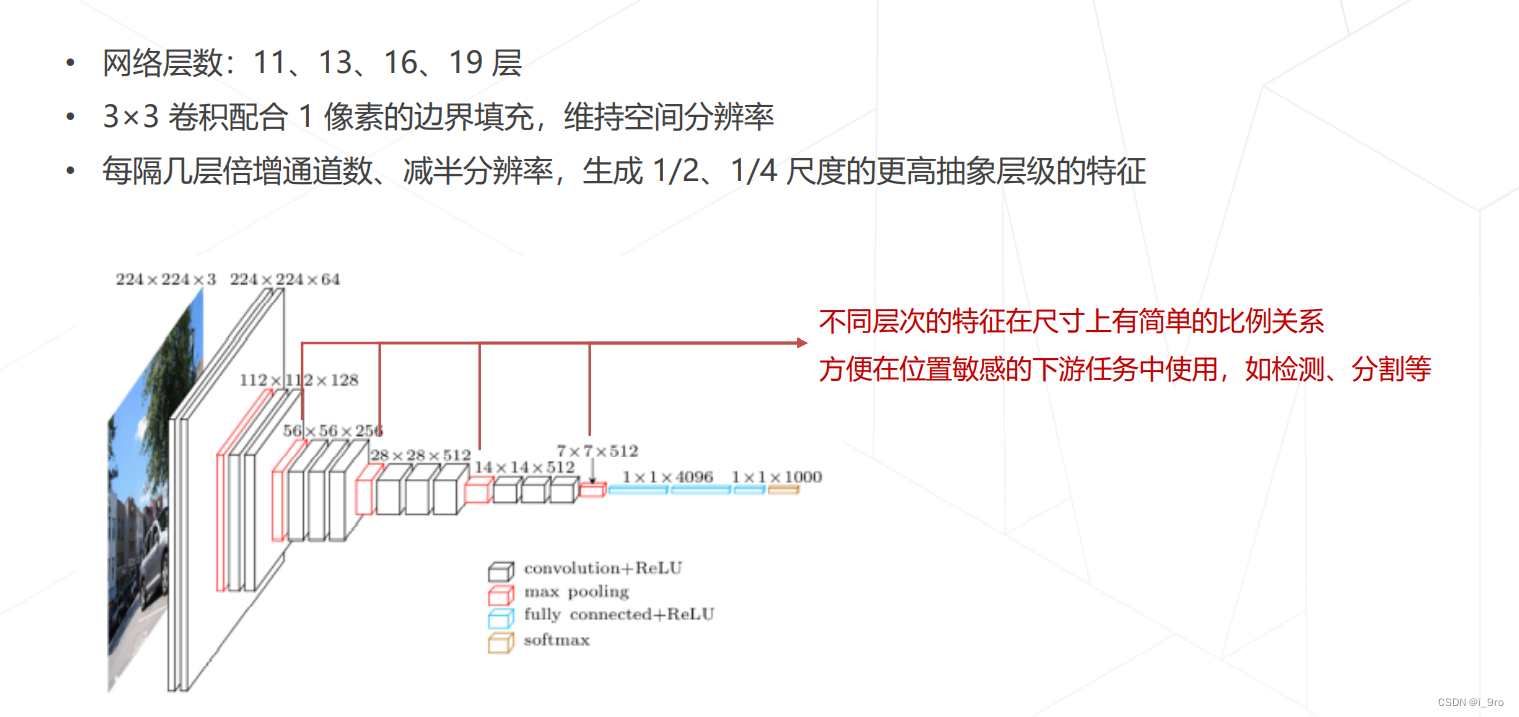
- VGG 2014
K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In International Conference on Learning Representations, May 2015
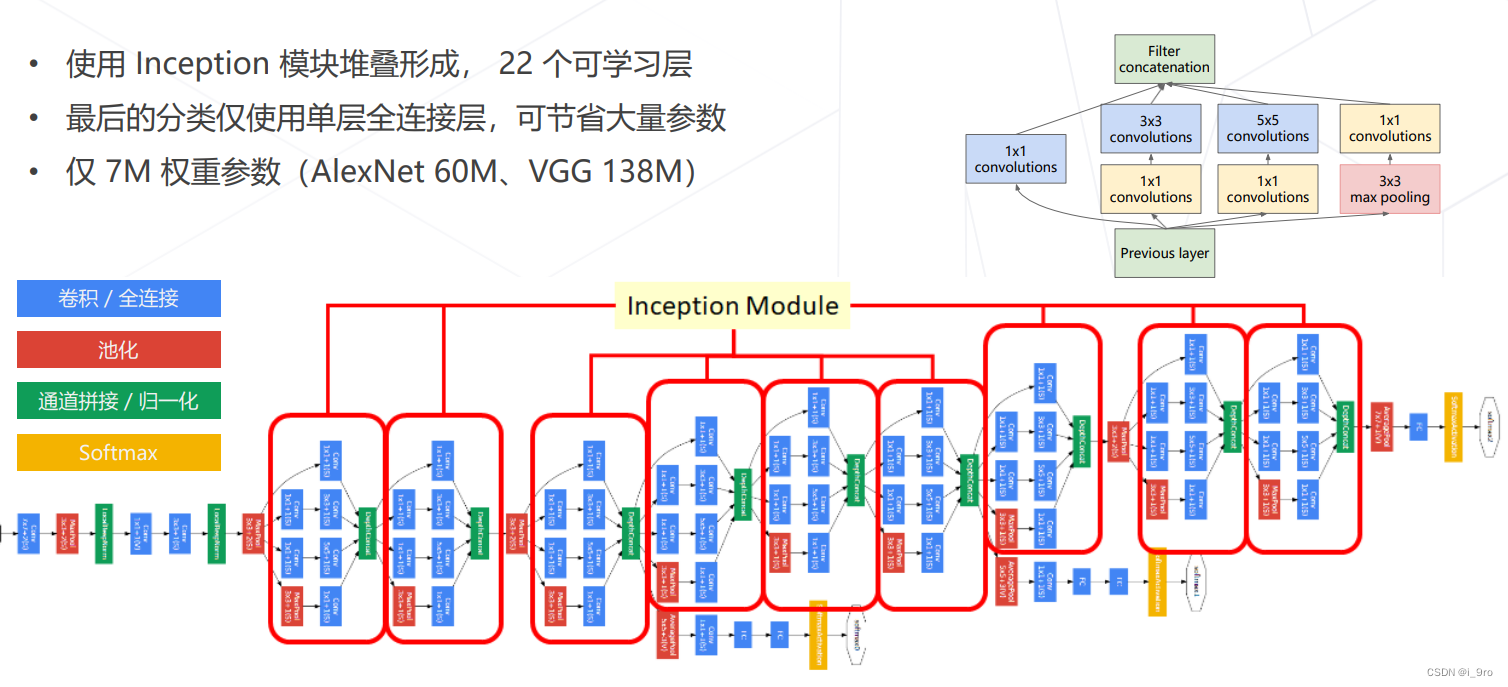
3. GoogLeNet (Inception v1, 2014)
Szegedy, Christian, et al. “Going deeper with convolutions.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
-
阶段性问题
精度退化:模型层数增加到一定程度后,分类正确率不增反降
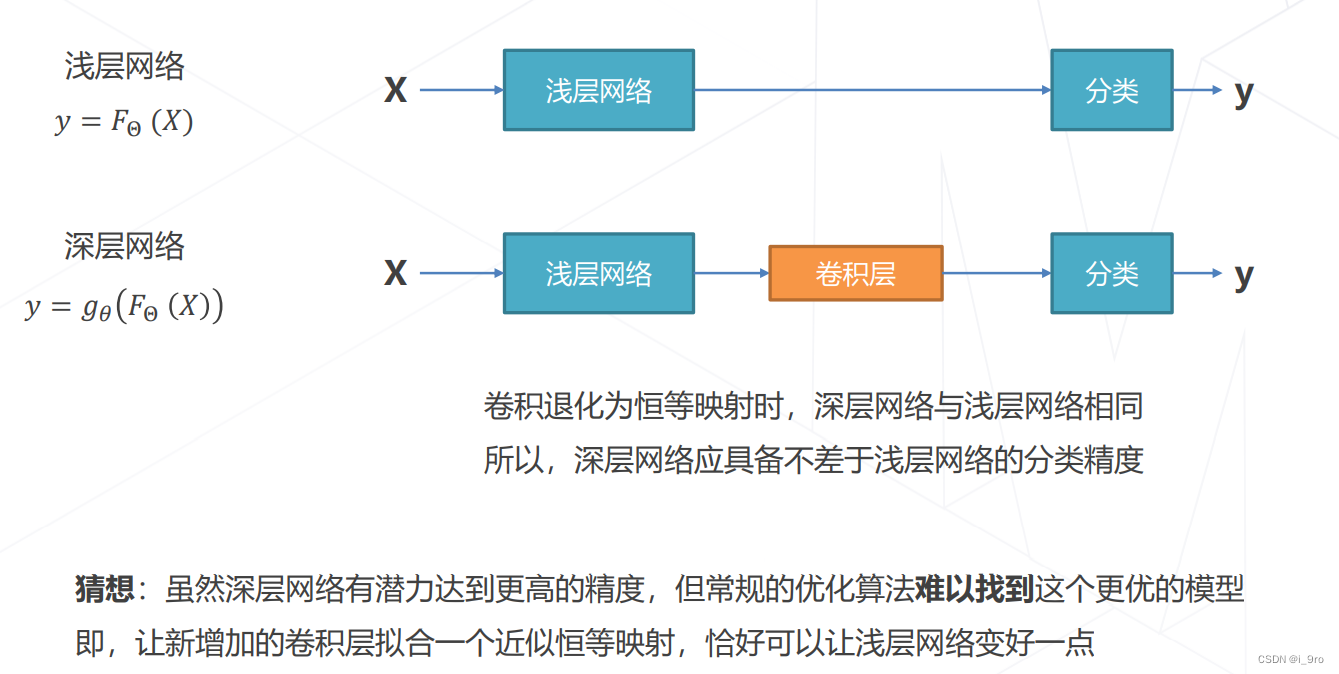
尝试解决:残差学习
- ResNet 2015
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern
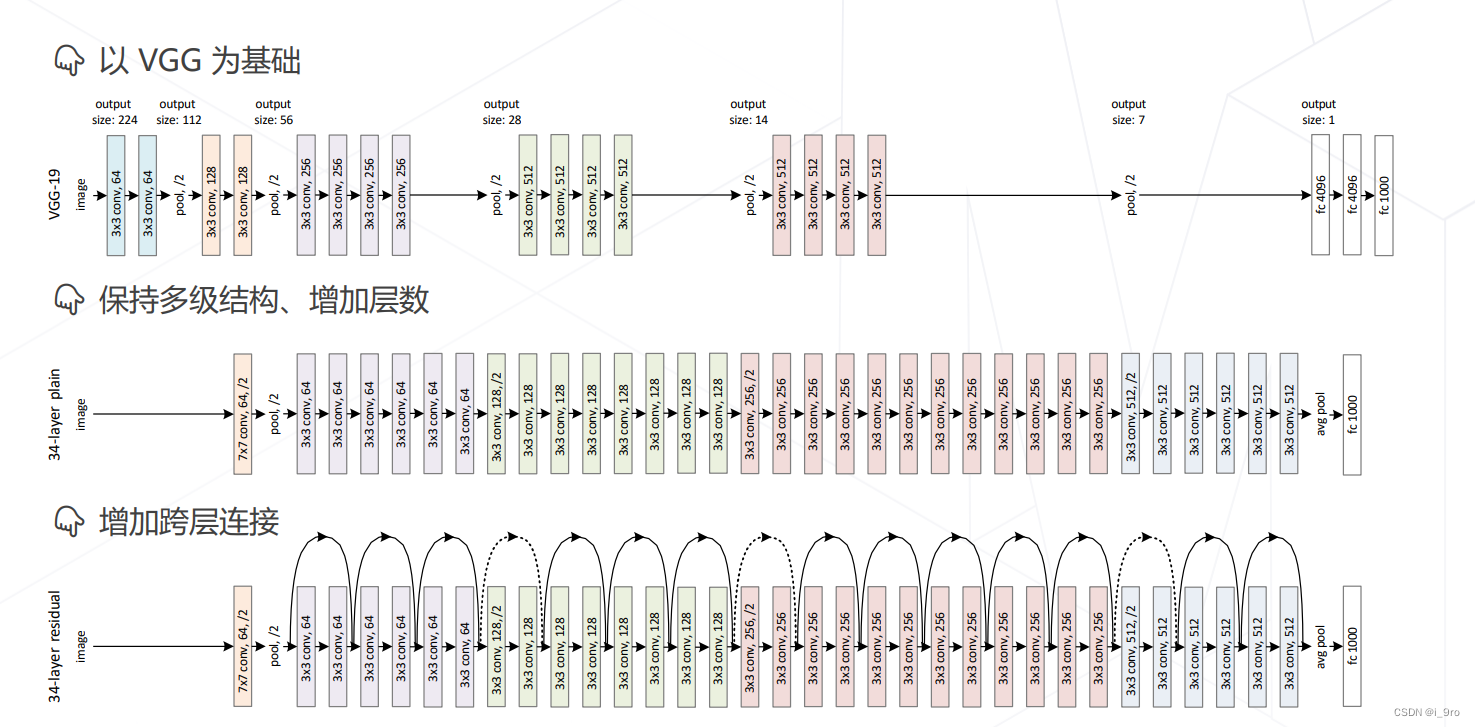
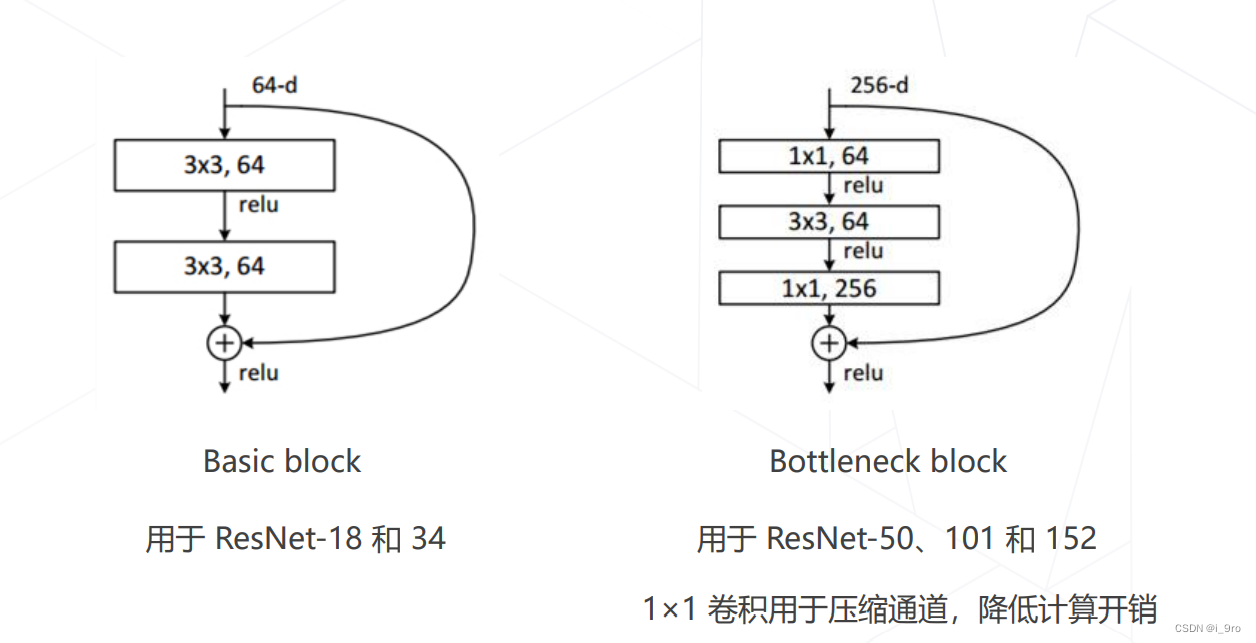
两种残差模块
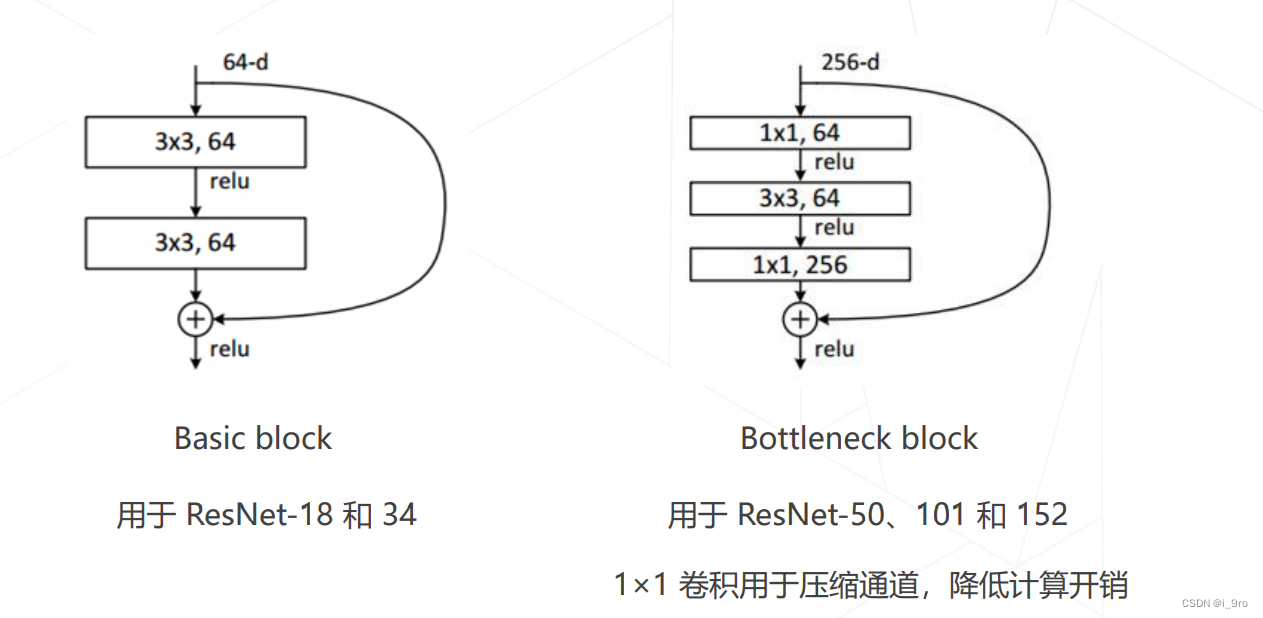
优点:
-
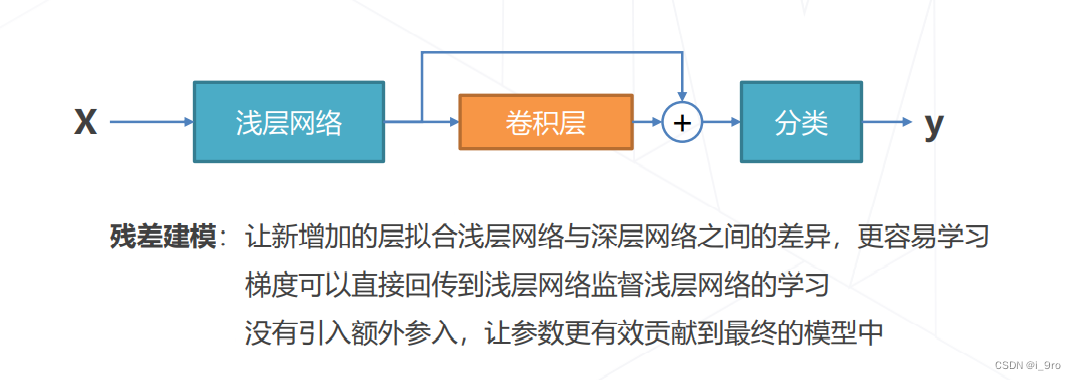
ResNet 是深浅模型的集成
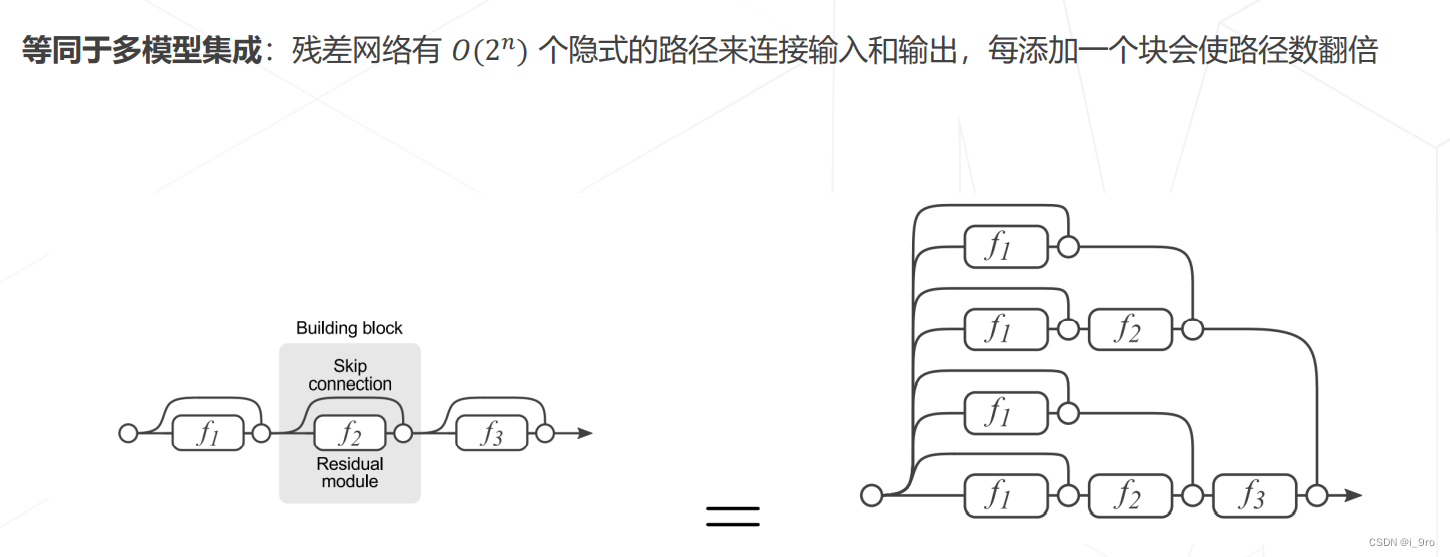
-
残差链接让损失曲面更平滑
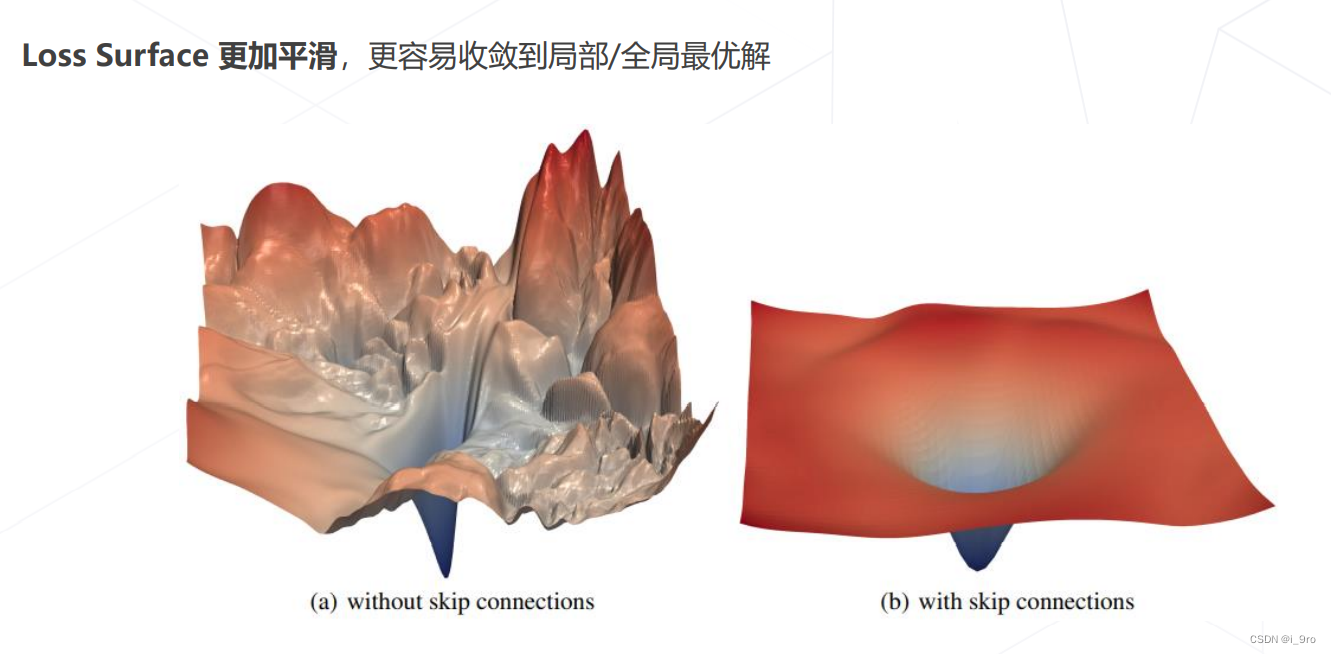
后续改进
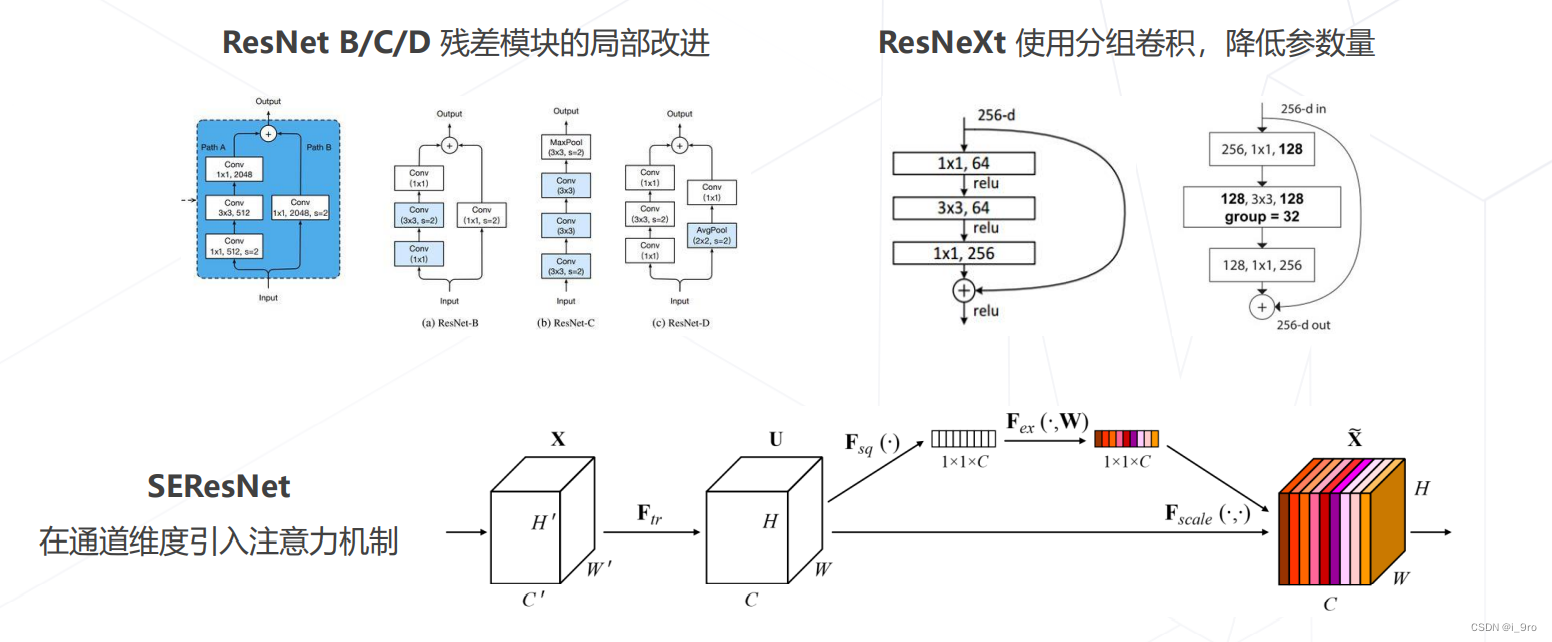
-
神经结构搜索 Neural Architecture Search (2016+)
基本思路:借助强化学习等方法搜索表现最佳的网络
代表工作:NASNet (2017)、MnasNet (2018)、EfficientNet (2019) 、RegNet (2020) 等
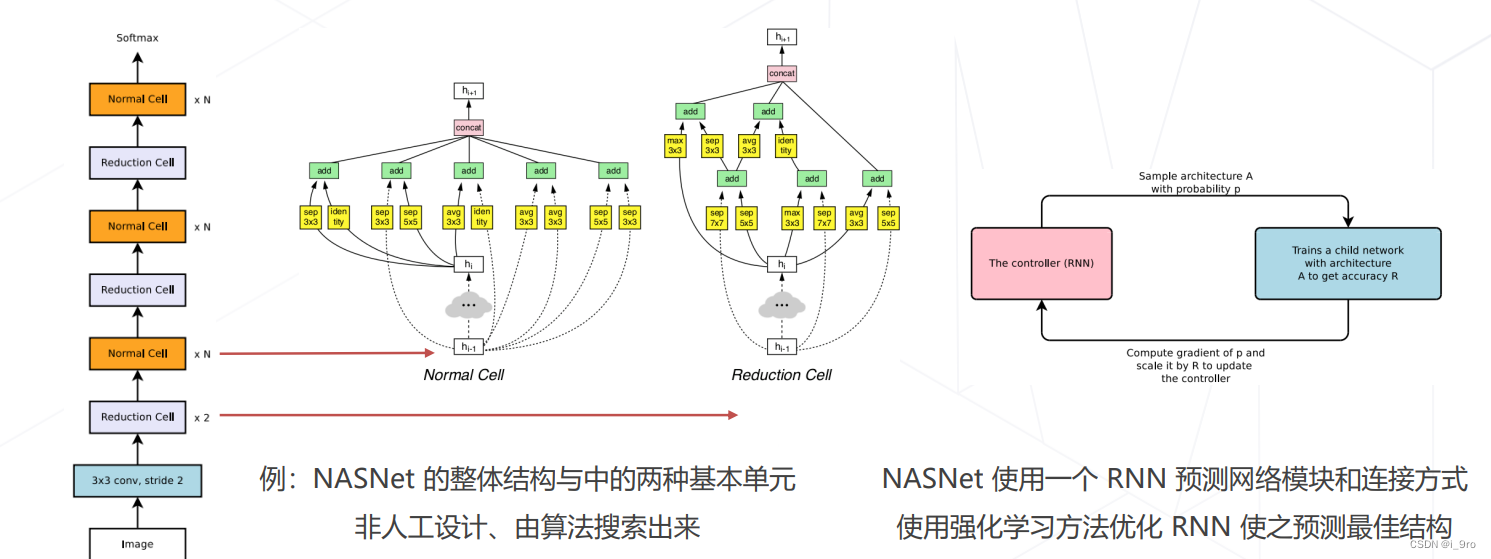
-
Vision Transformers (2020+)
使用 Transformer 替代卷积网络实现图像分类,使用更大的数据集训练,达到超越卷积网络的精度
代表工作:Vision Transformer (2020)
Dosovitskiy, Alexey, et al. “An image is worth 16×16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
Swin-Transformer (2021 ICCV 最佳论文)
Liu, Ze, et al. “Swin transformer: Hierarchical vision transformer using shifted windows.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
- ConvNeXt (2022)
Liu, Zhuang, et al. “A ConvNet for the 2020s.” arXiv preprint arXiv:2201.03545 (2022).
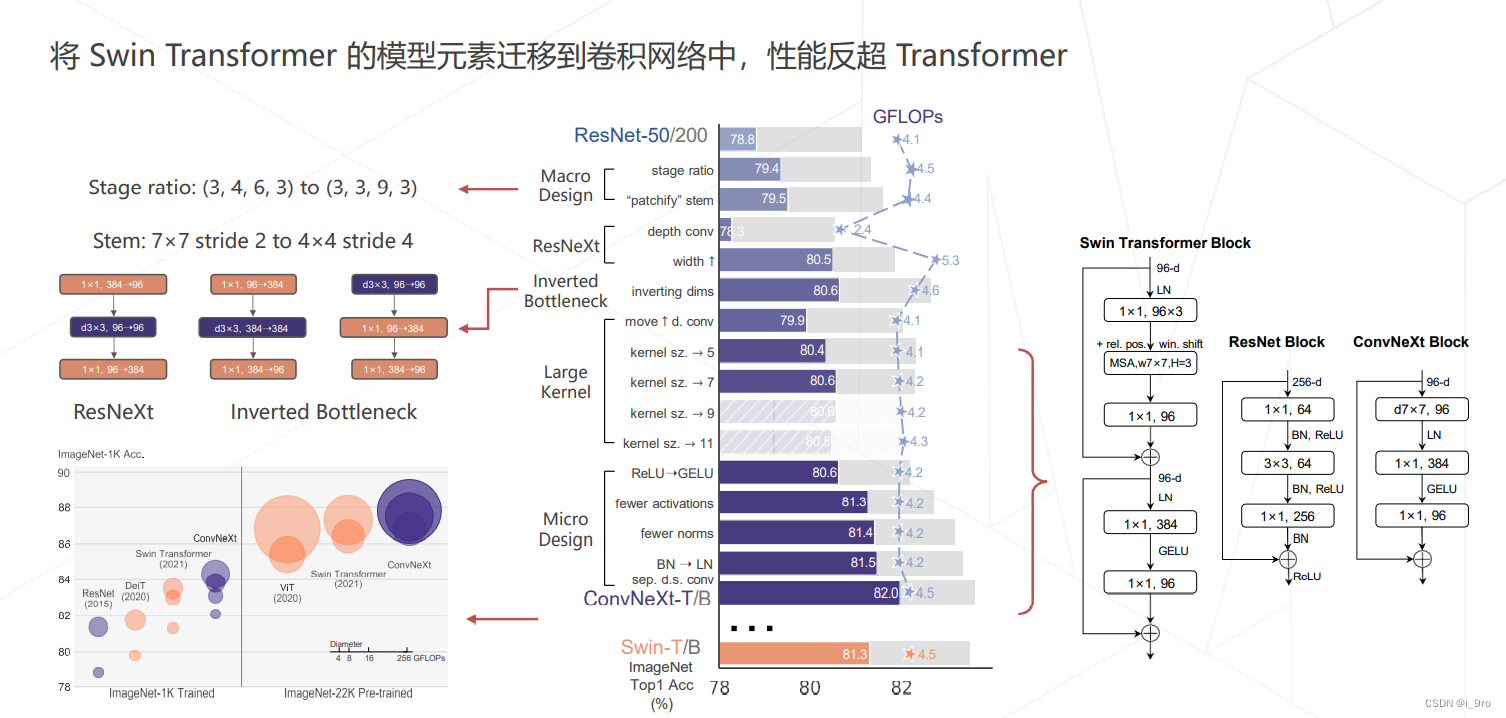
9. 总结
四、轻量化卷积神经网络
-
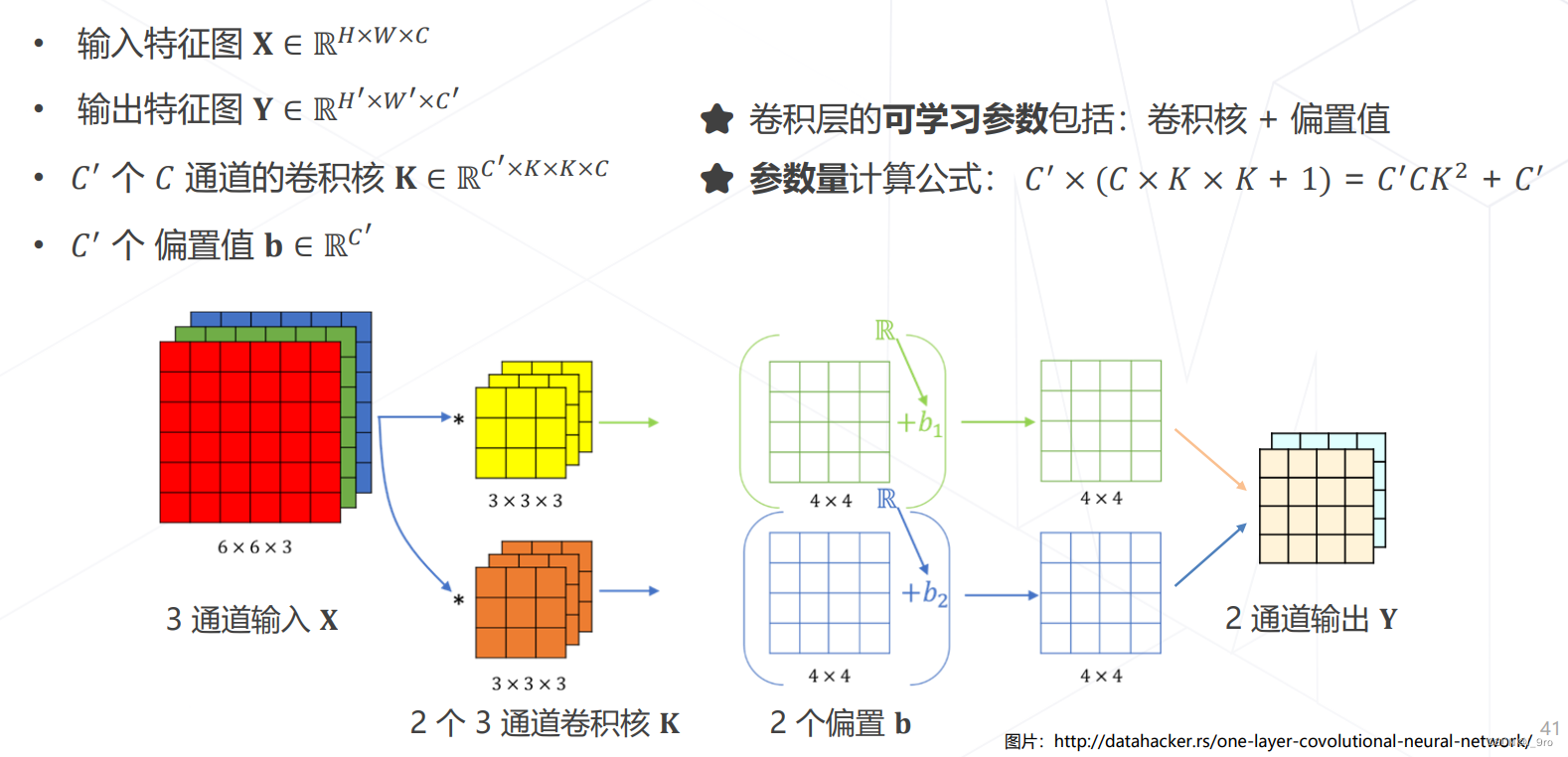
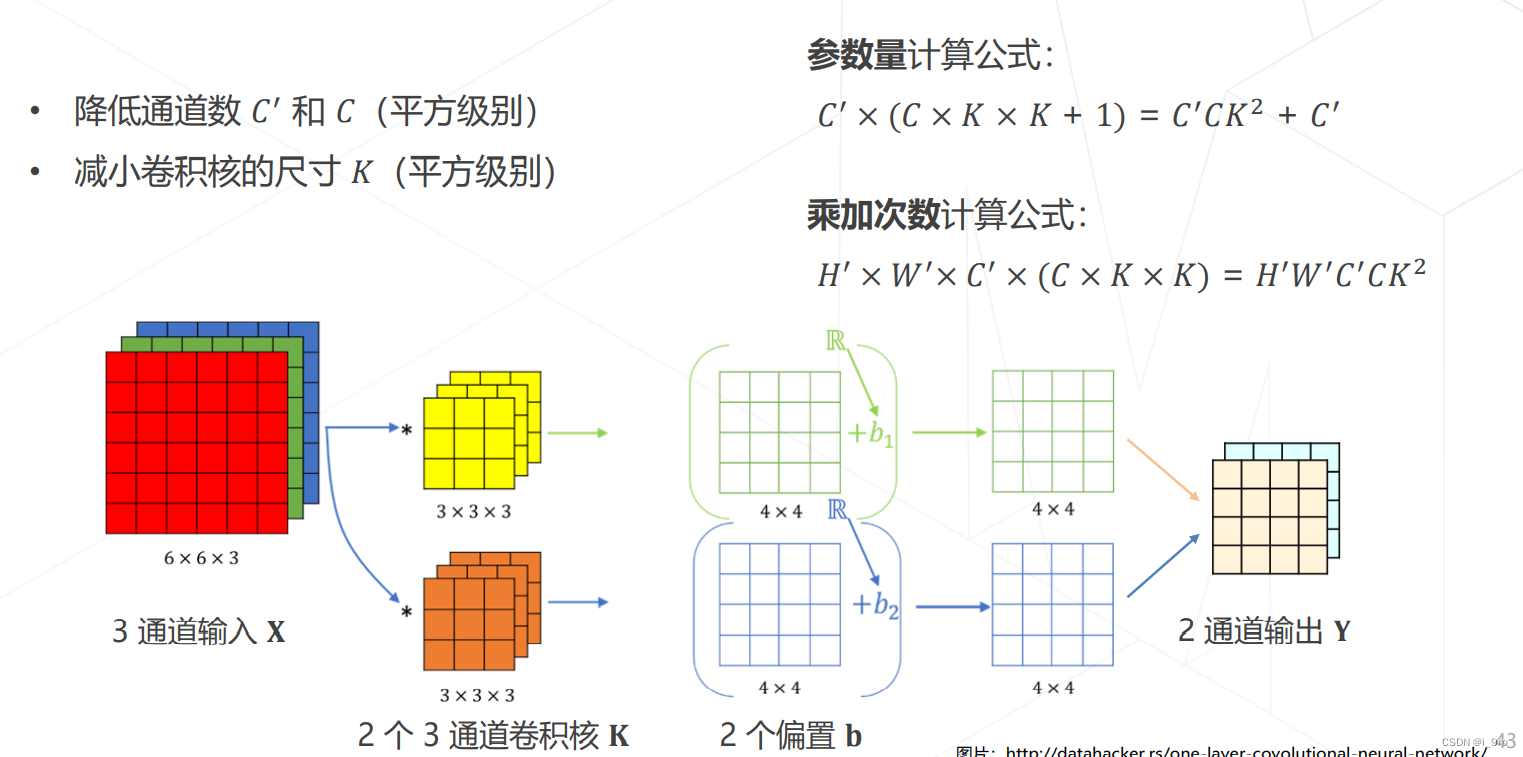
卷积的参数量
-
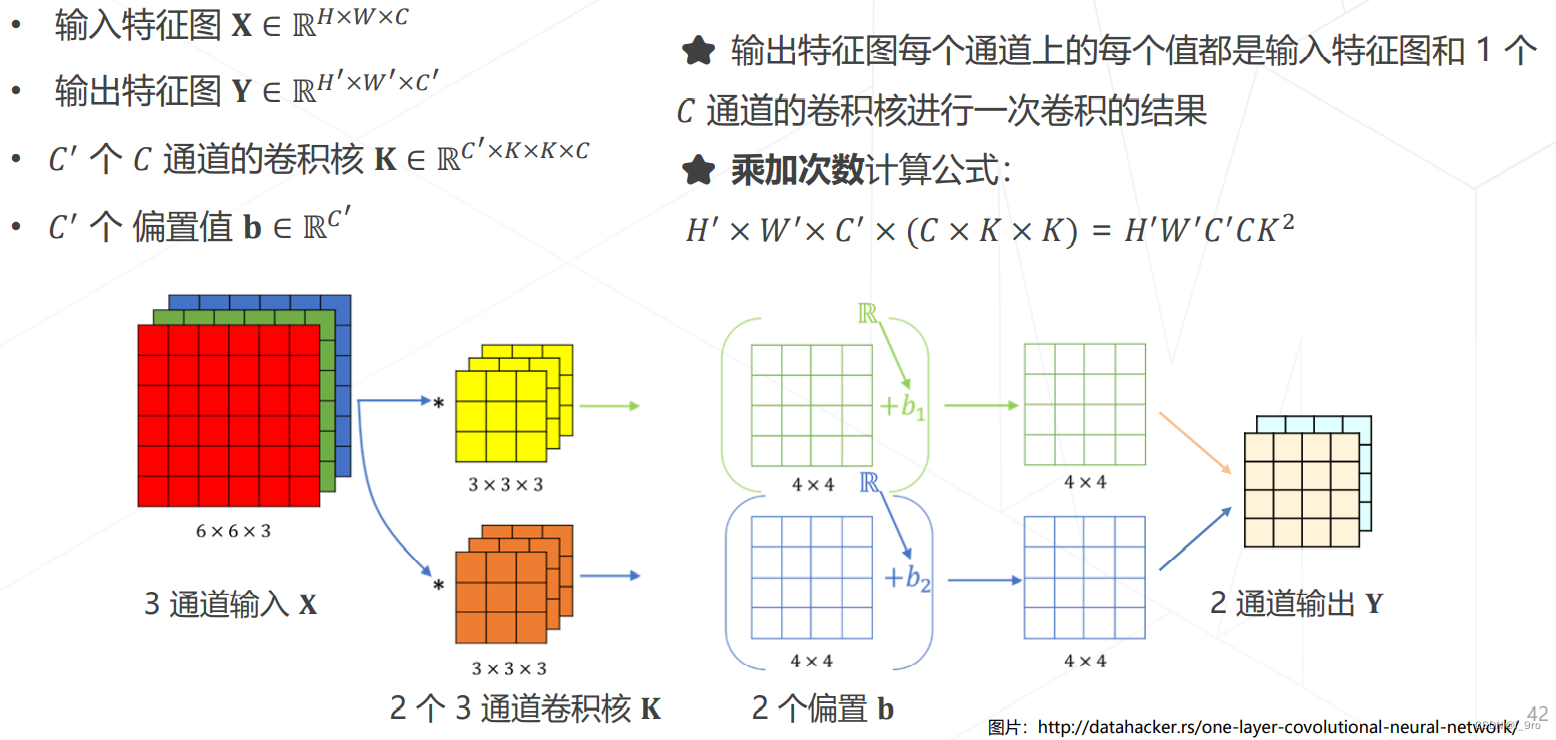
卷积的计算量(乘加次数)
-
降低模型参数量和计算量的方法
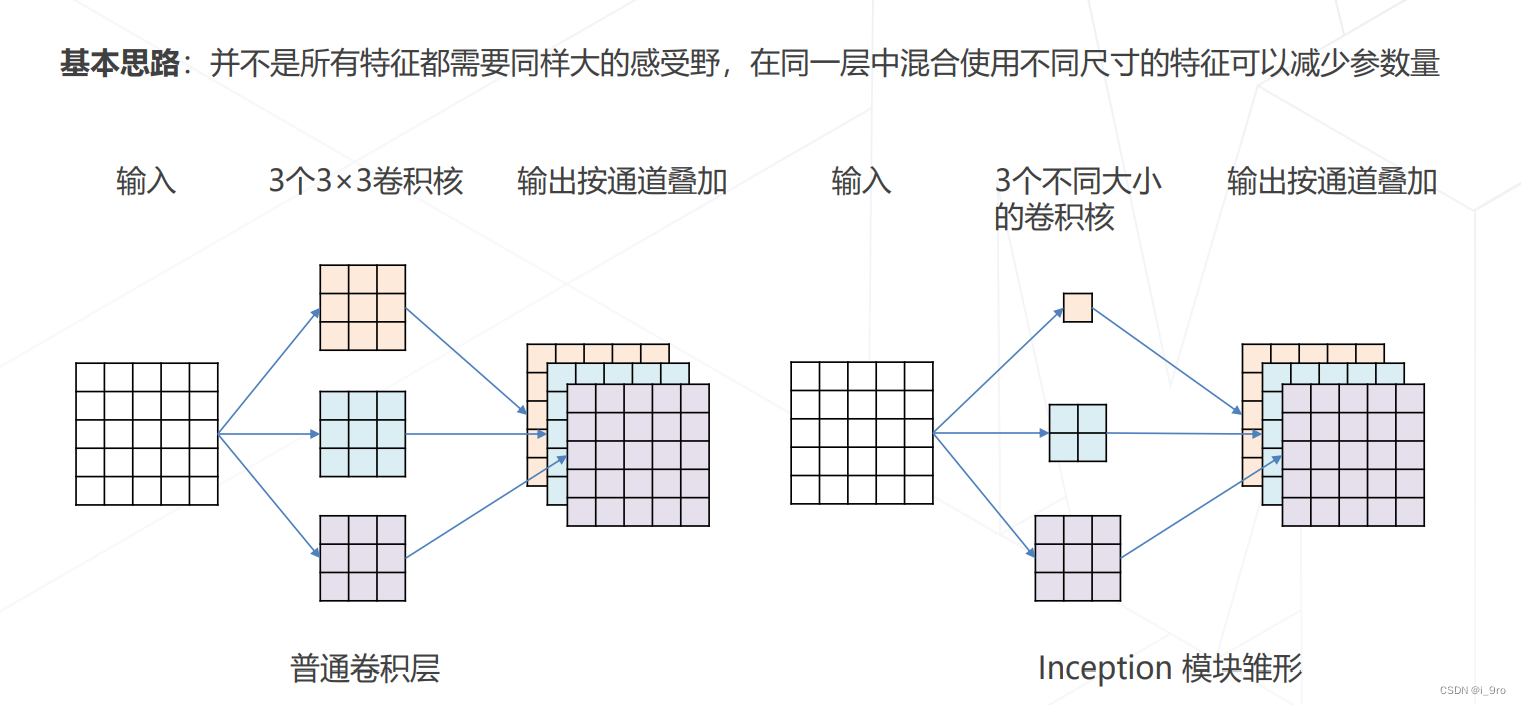
-
GoogLeNet 使用不同大小的卷积核
-
ResNet 使用1×1卷积压缩通道数
-
可分离卷积
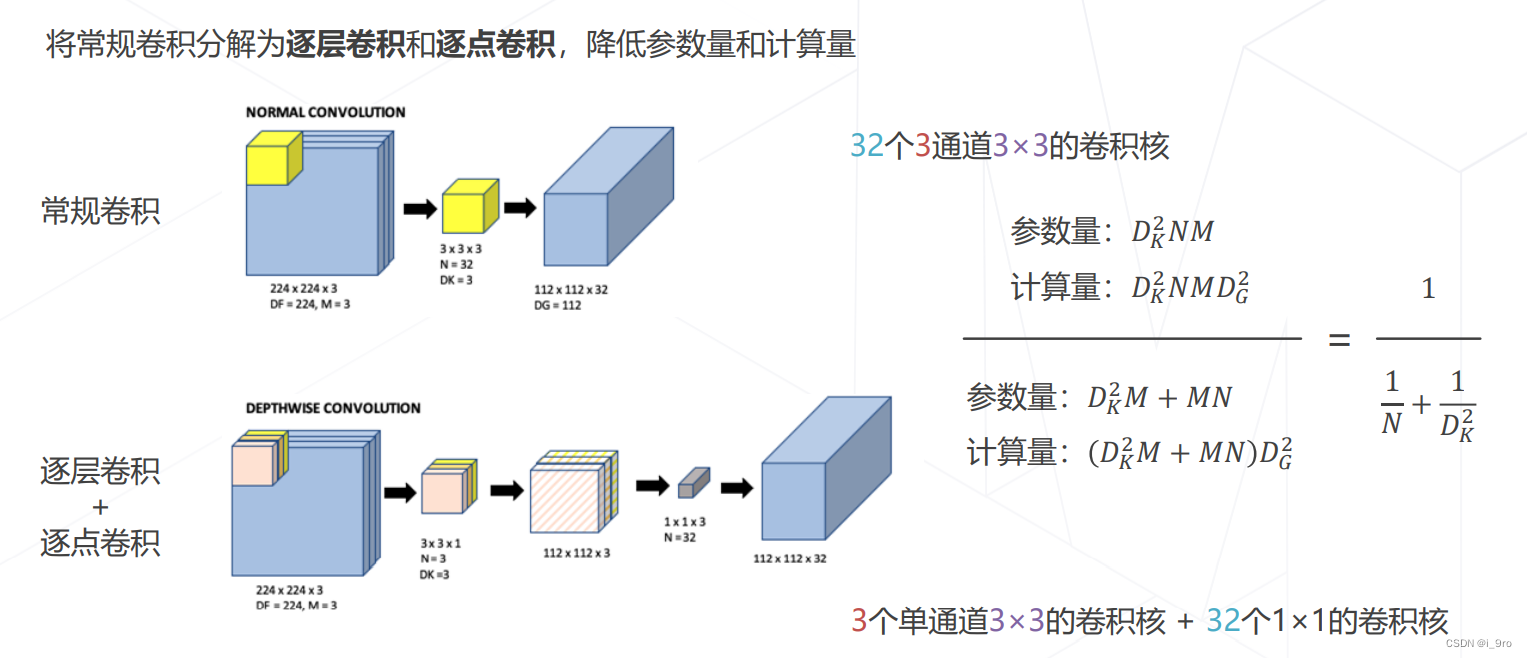
-
MobileNet V1/V2/V3 (2017~2019)
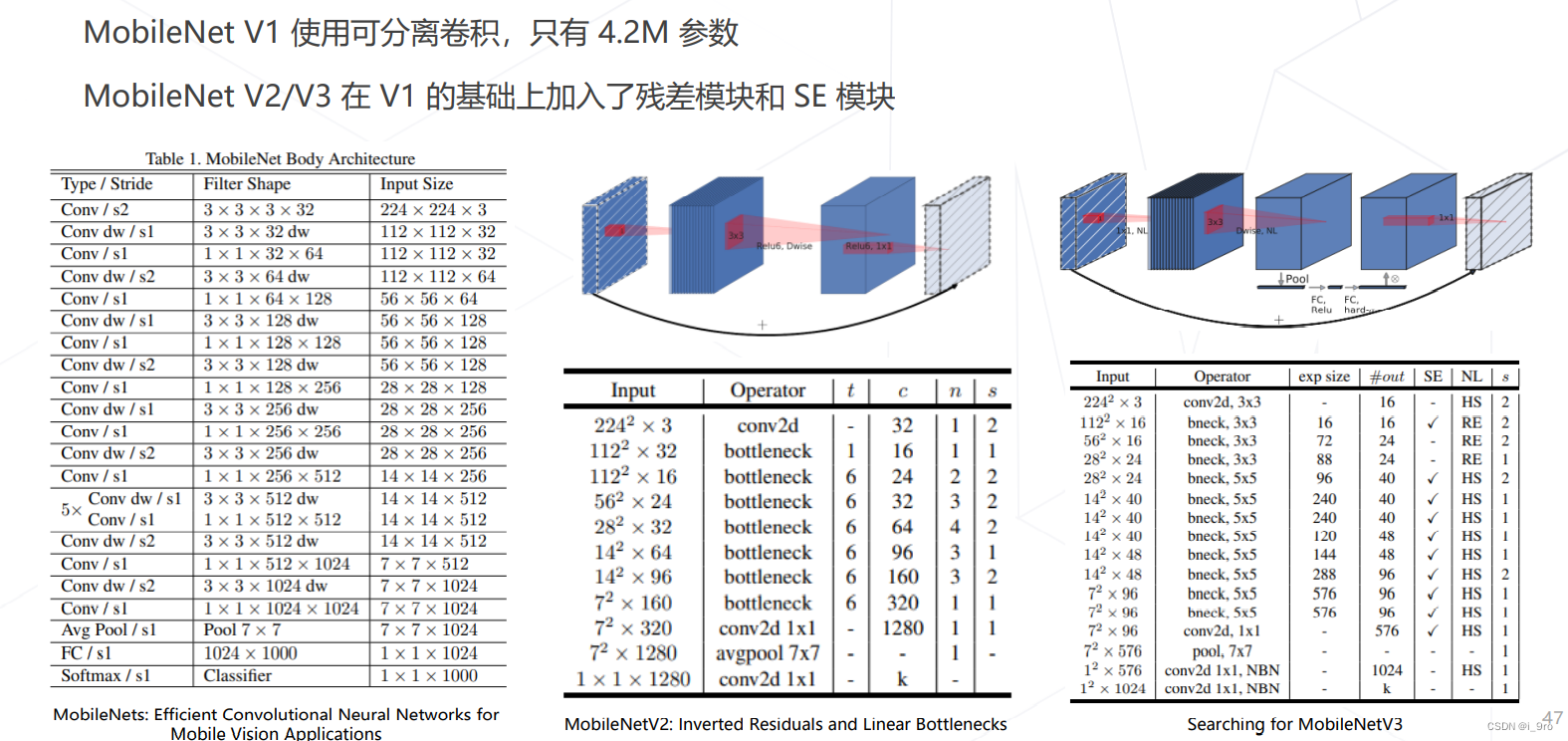
-
ResNeXt 中的分组卷积
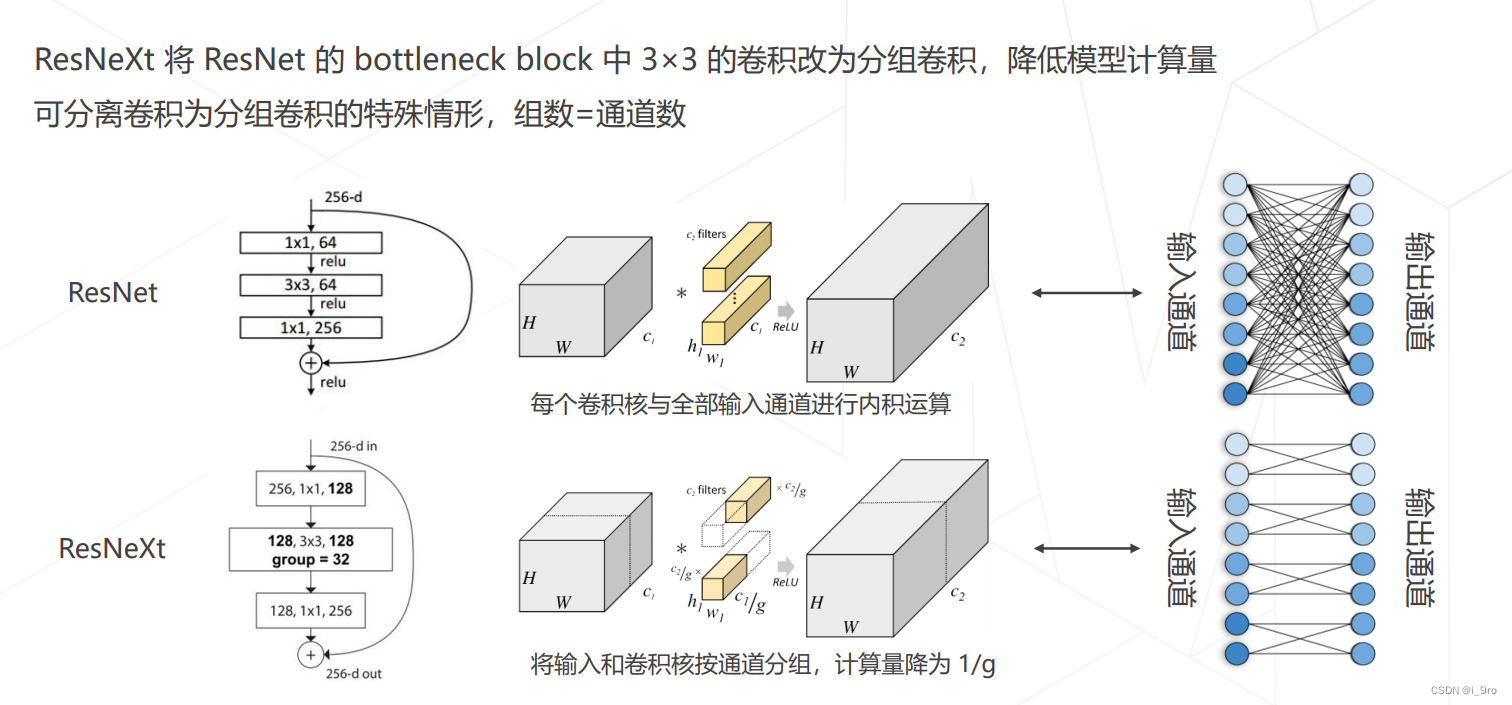
五、Vision Transformers
- 注意力机制(Attention)
Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
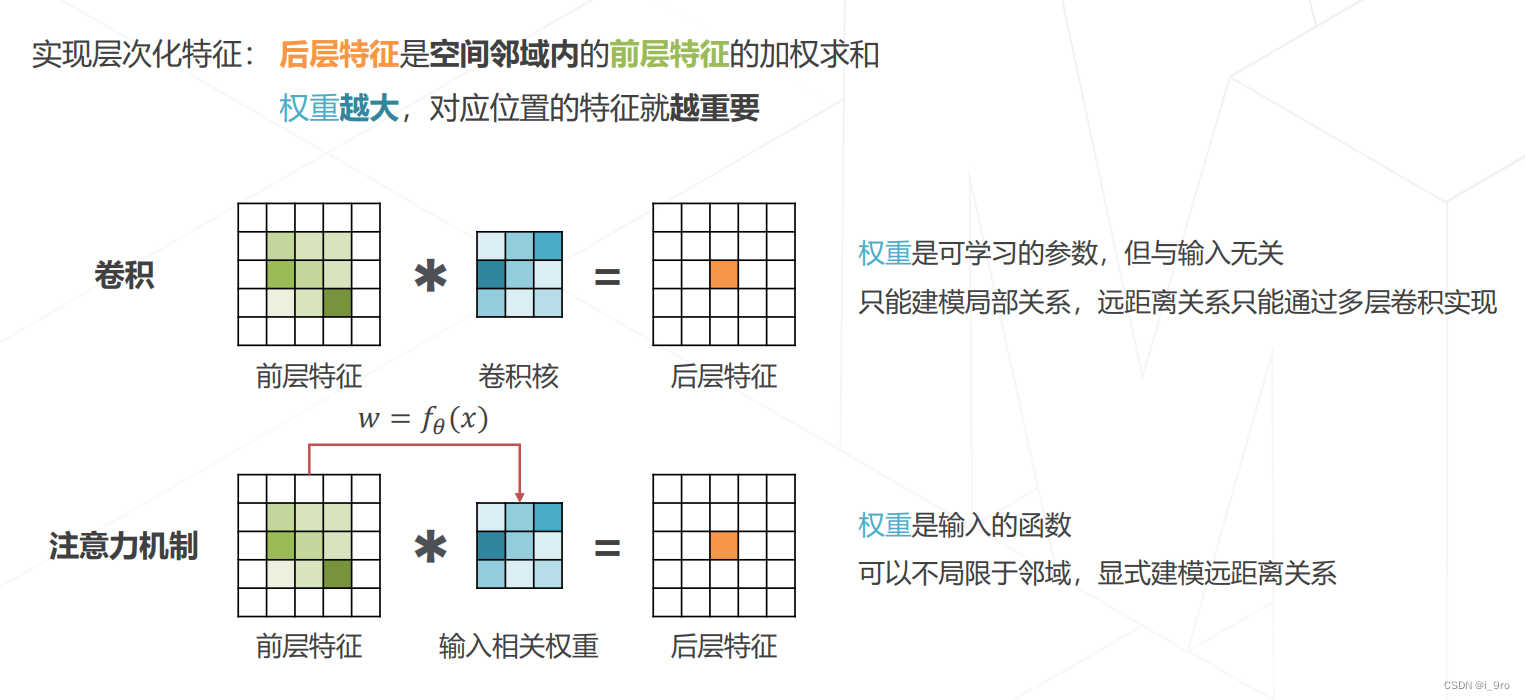
为什么使用注意力机制?
注意力机制最开始在机器翻译领域表现出色,显示出其长距离建模方面能力。于是,许多计算机视觉领域研究人员试图将注意力机制引入计算机视觉。

-
实现Attention
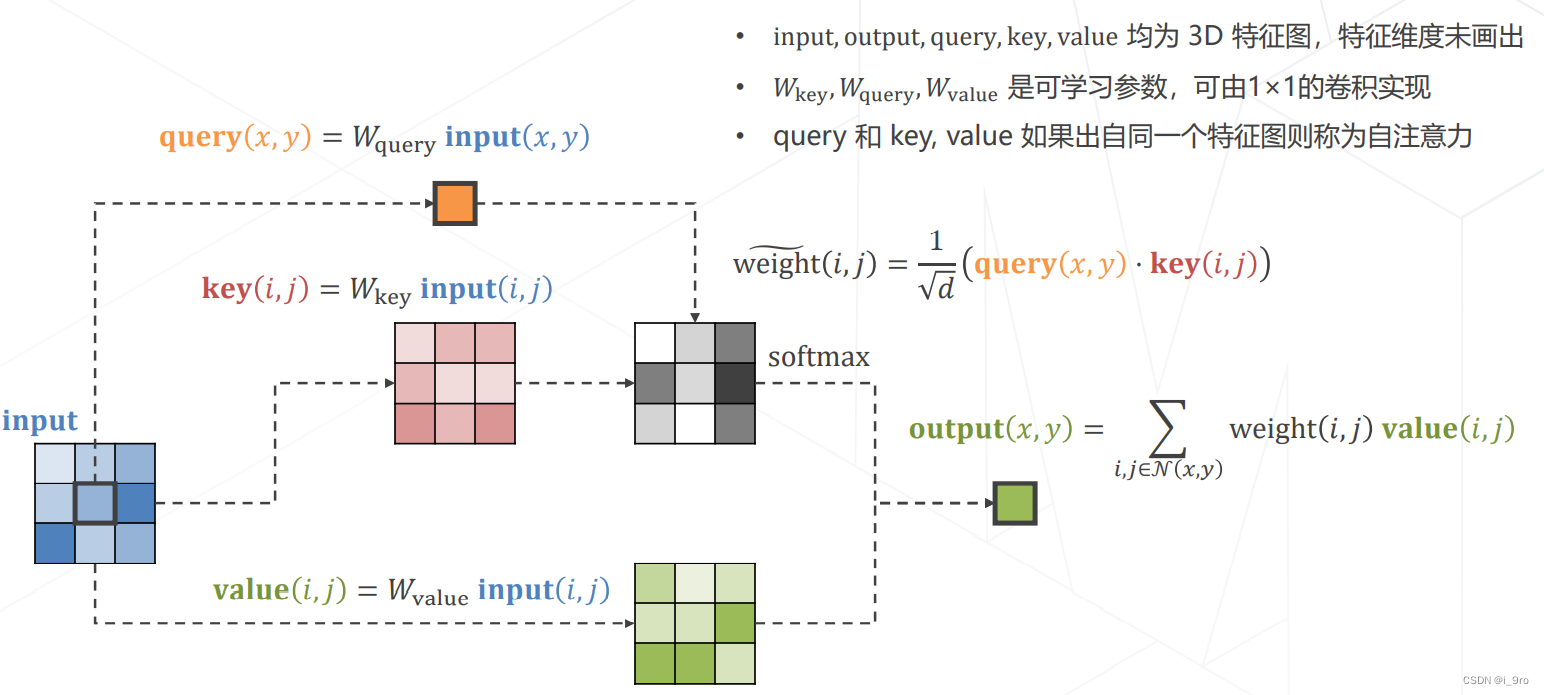
-
多头注意力 Multi-head (Self-)Attention
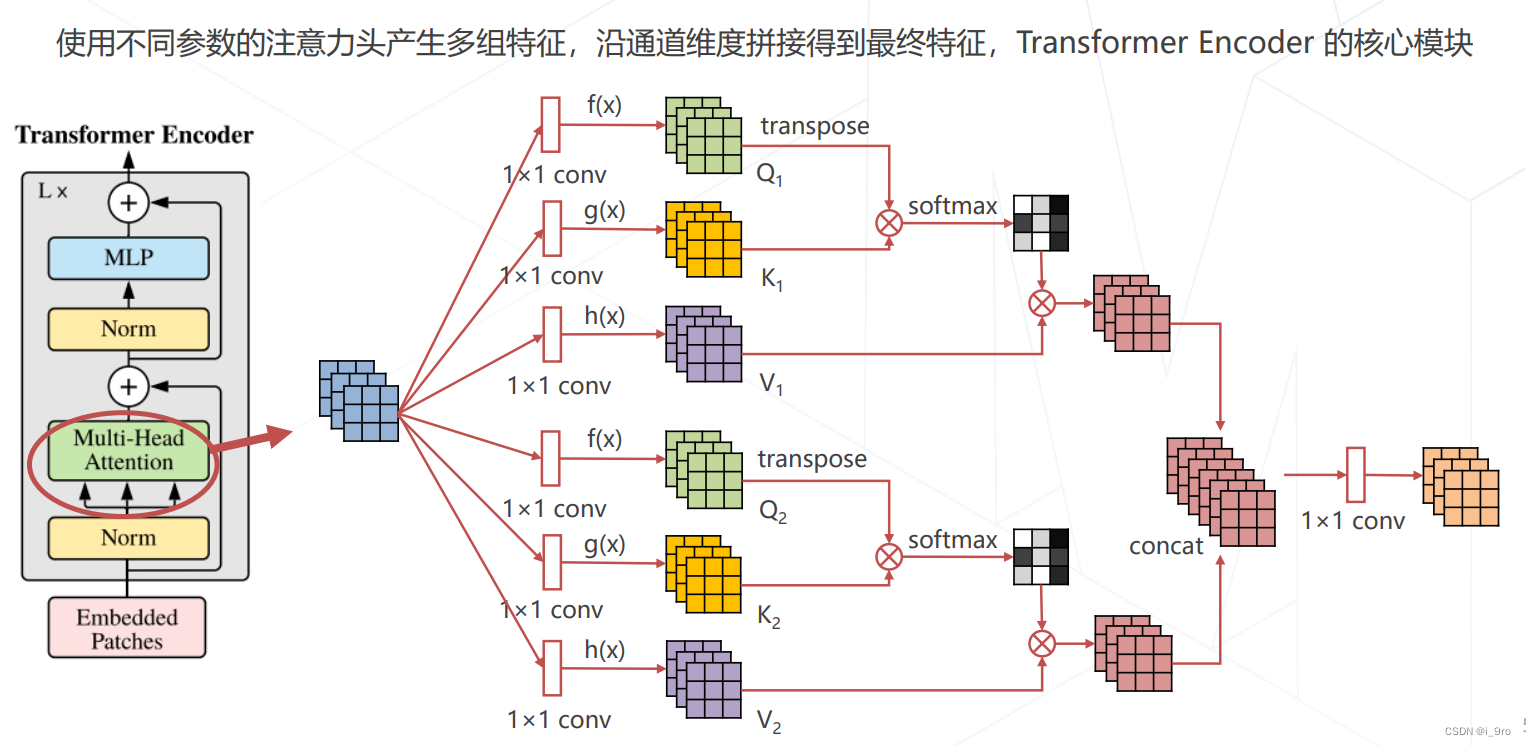
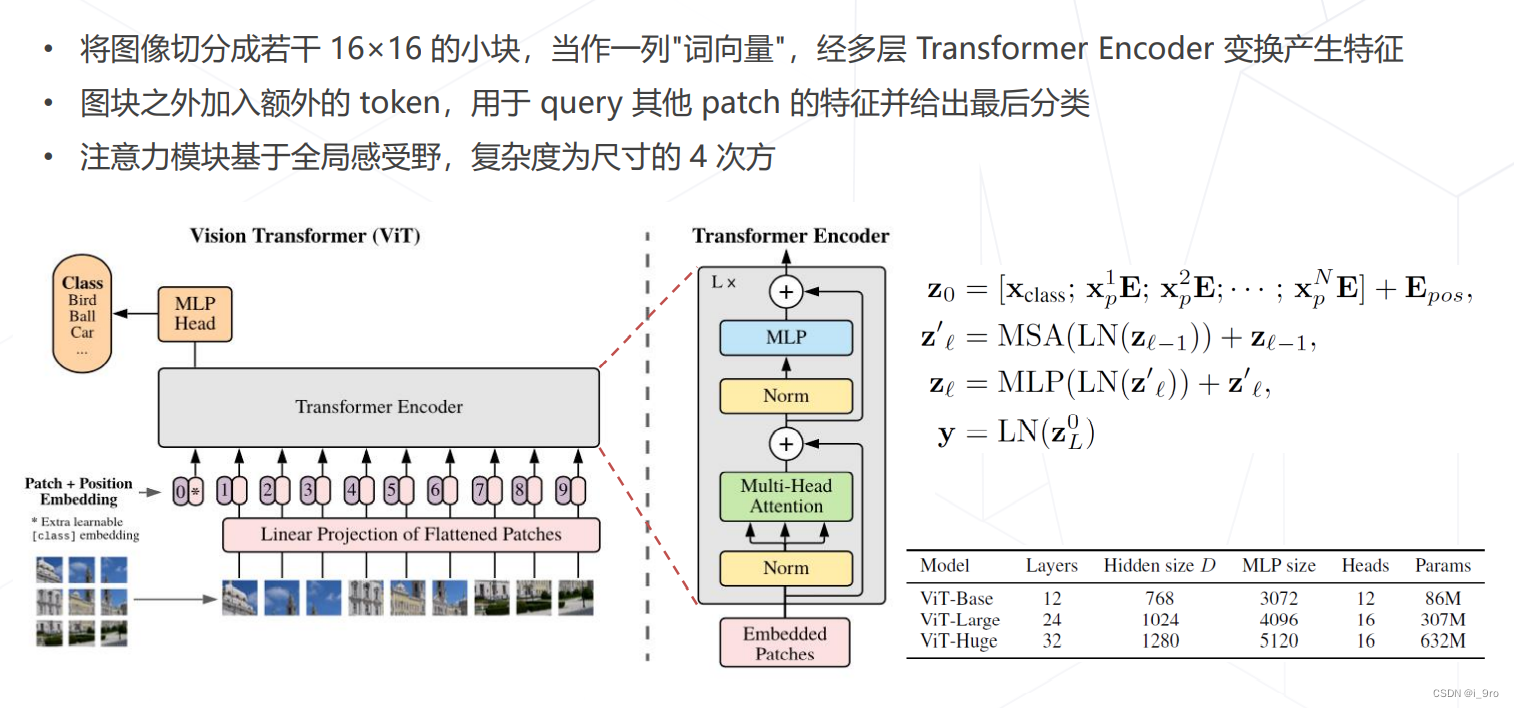
- ViT 2020
Dosovitskiy, Alexey, et al. “An image is worth 16×16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
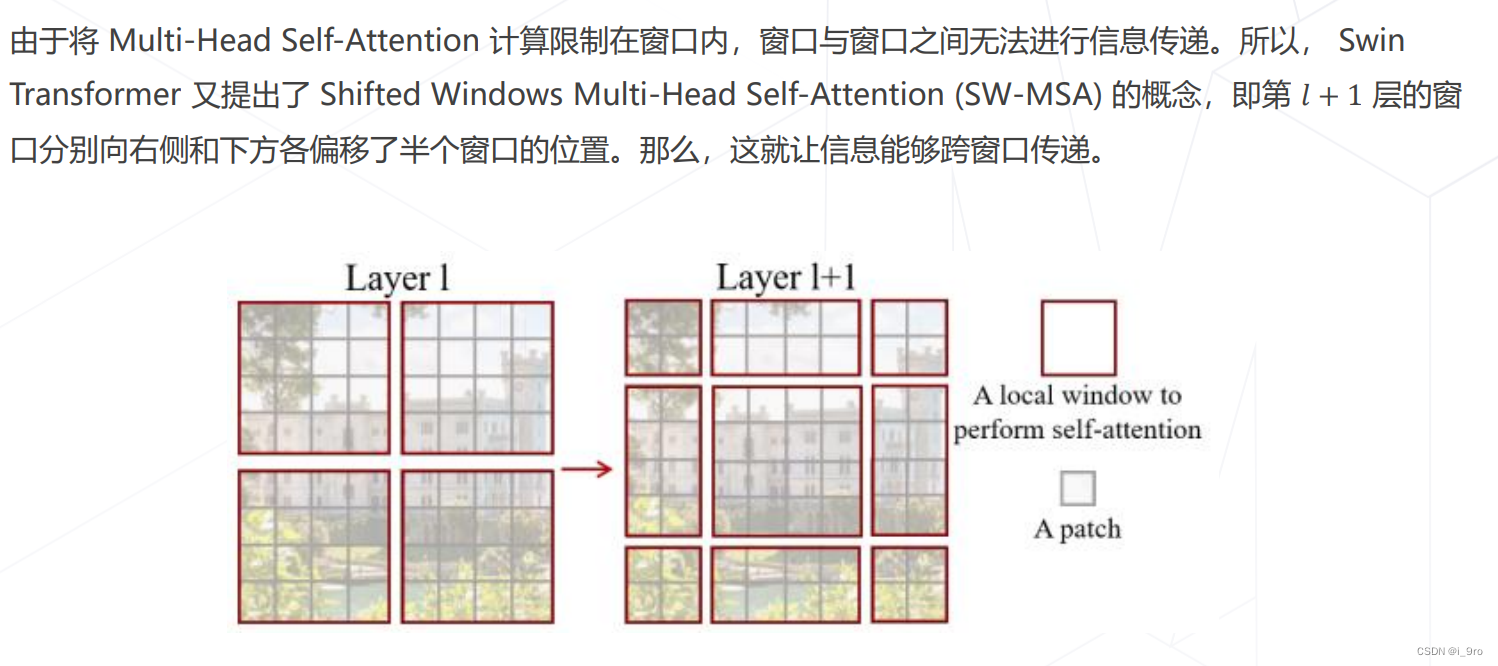
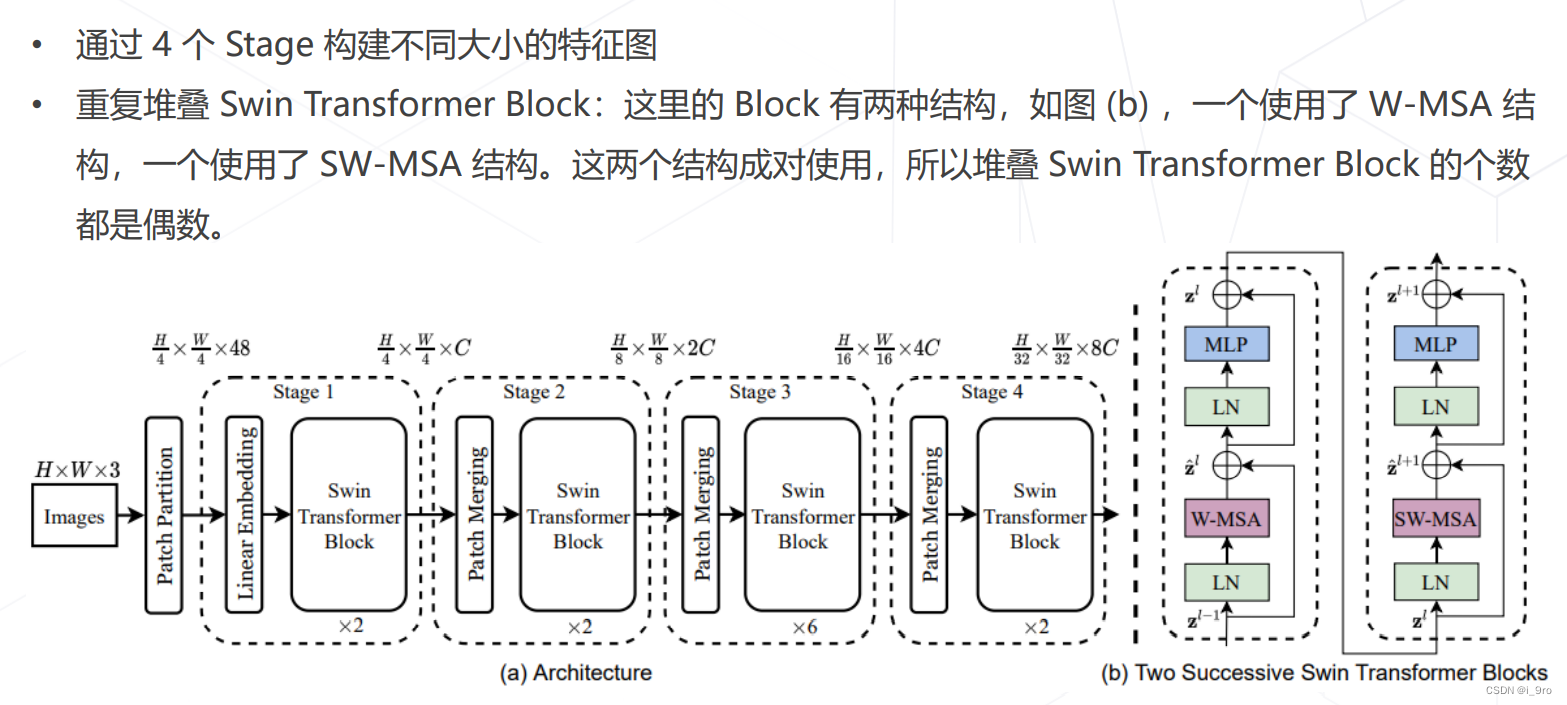
5. Swin Transformer (ICCV 2021 best paper)
Liu, Ze, et al. “Swin transformer: Hierarchical vision transformer using shifted windows.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.

六、模型学习
-
监督学习

-
非监督学习

-
训练技巧的重要性
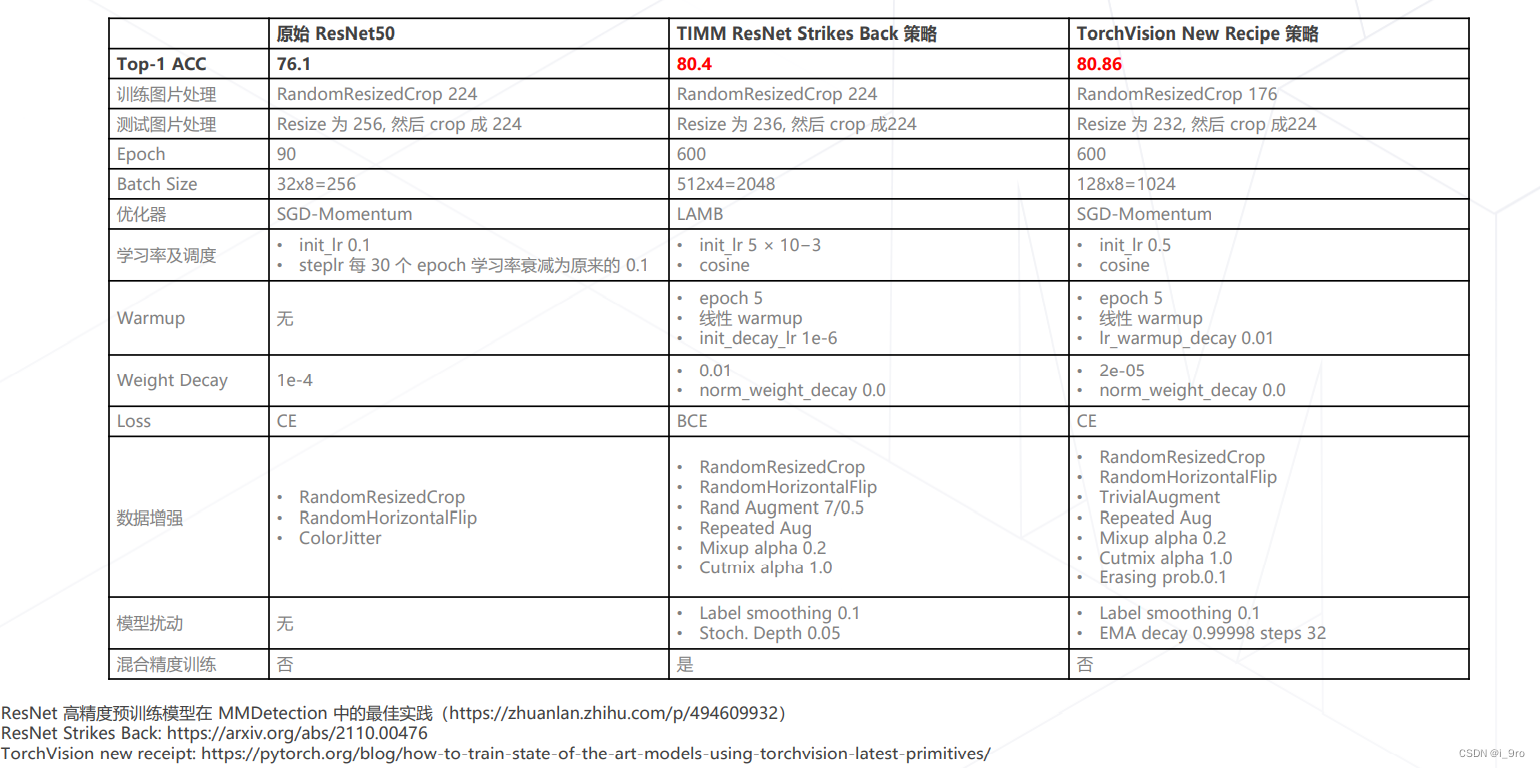
-
学习率与优化器策略
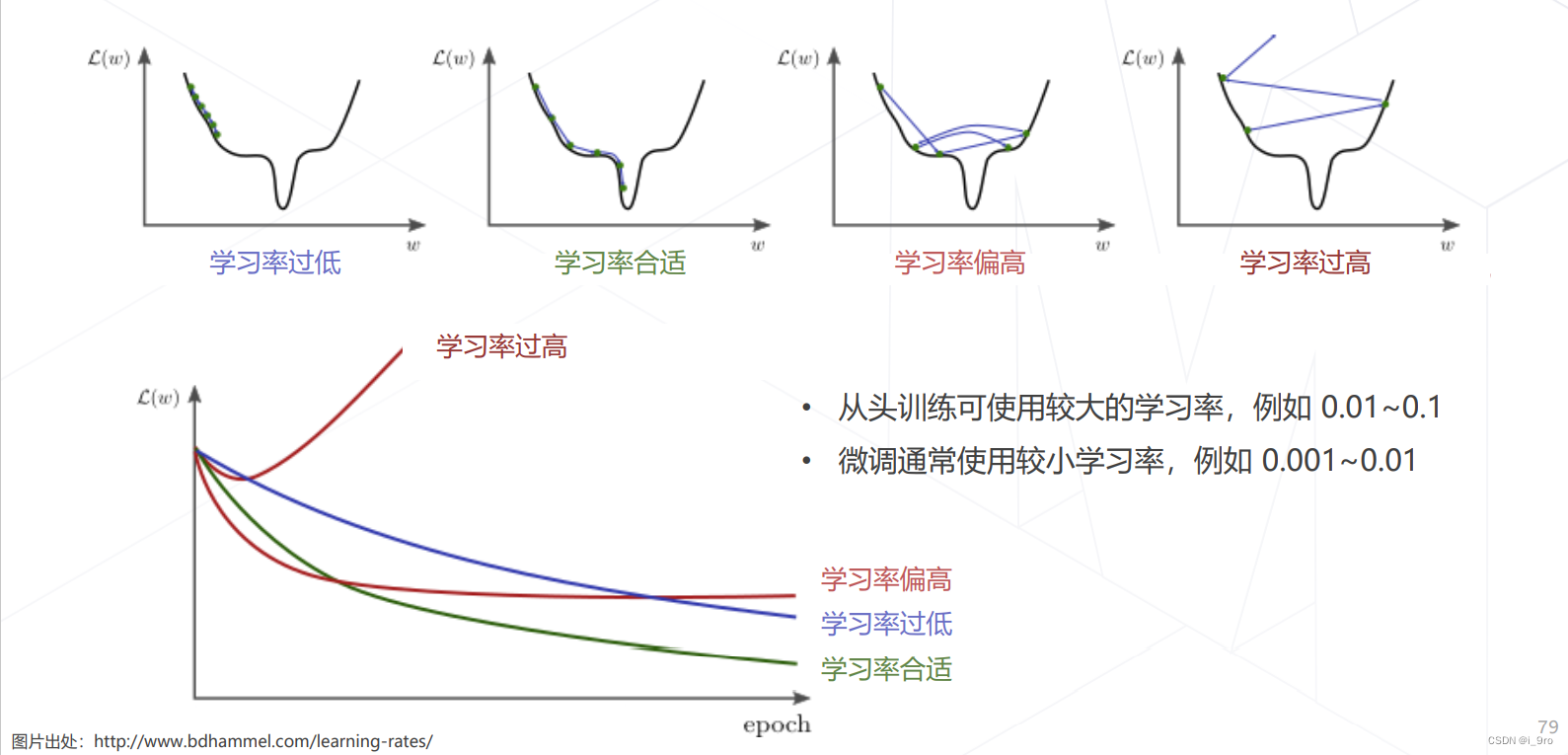
-
学习率退火 Annealing
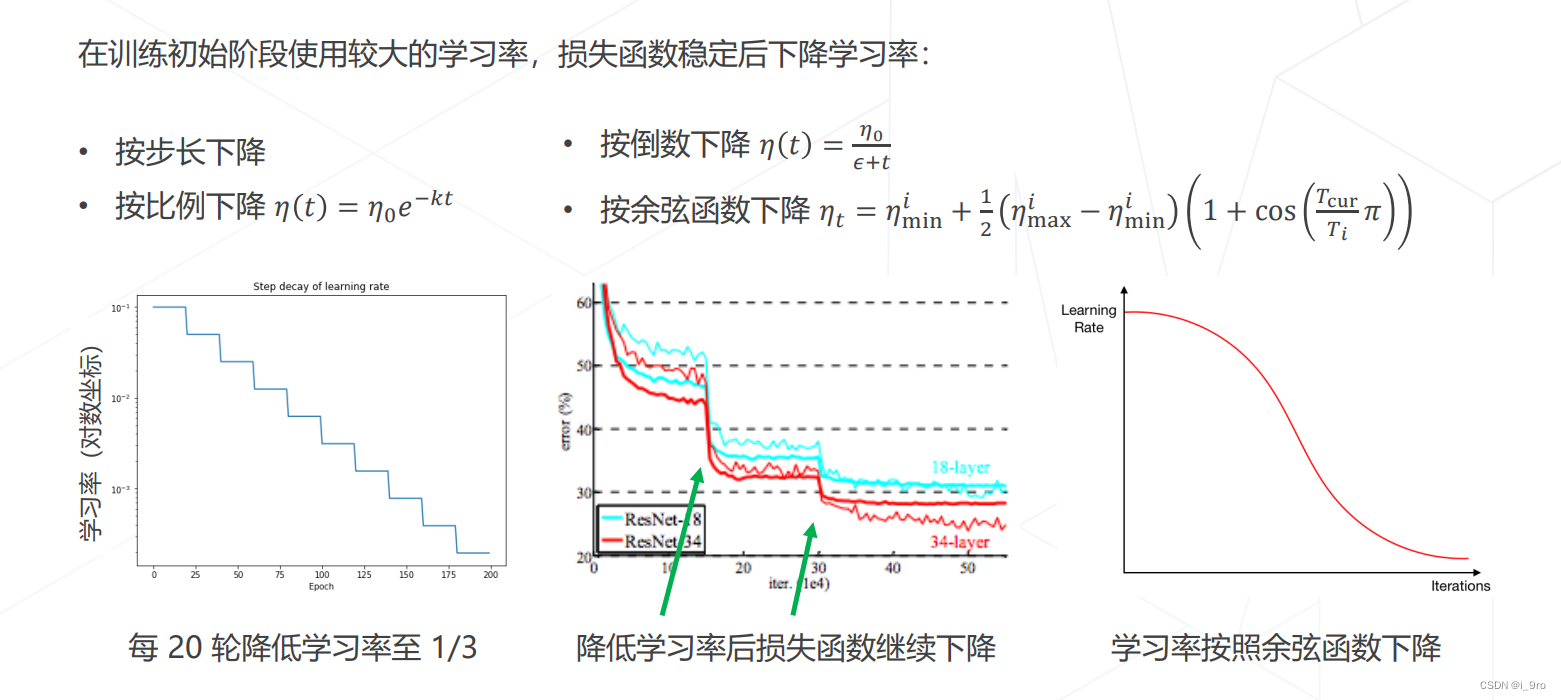
-
学习率升温 Warmup
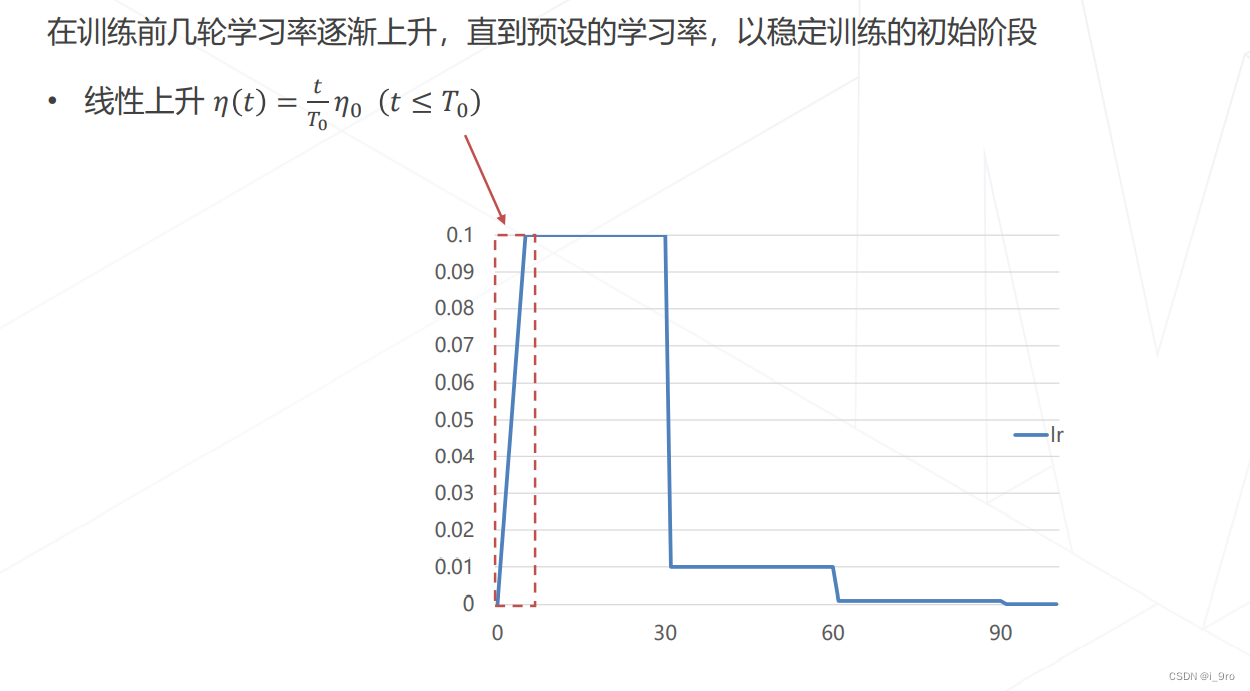
-
Linear Scaling Rule

-
自适应梯度算法
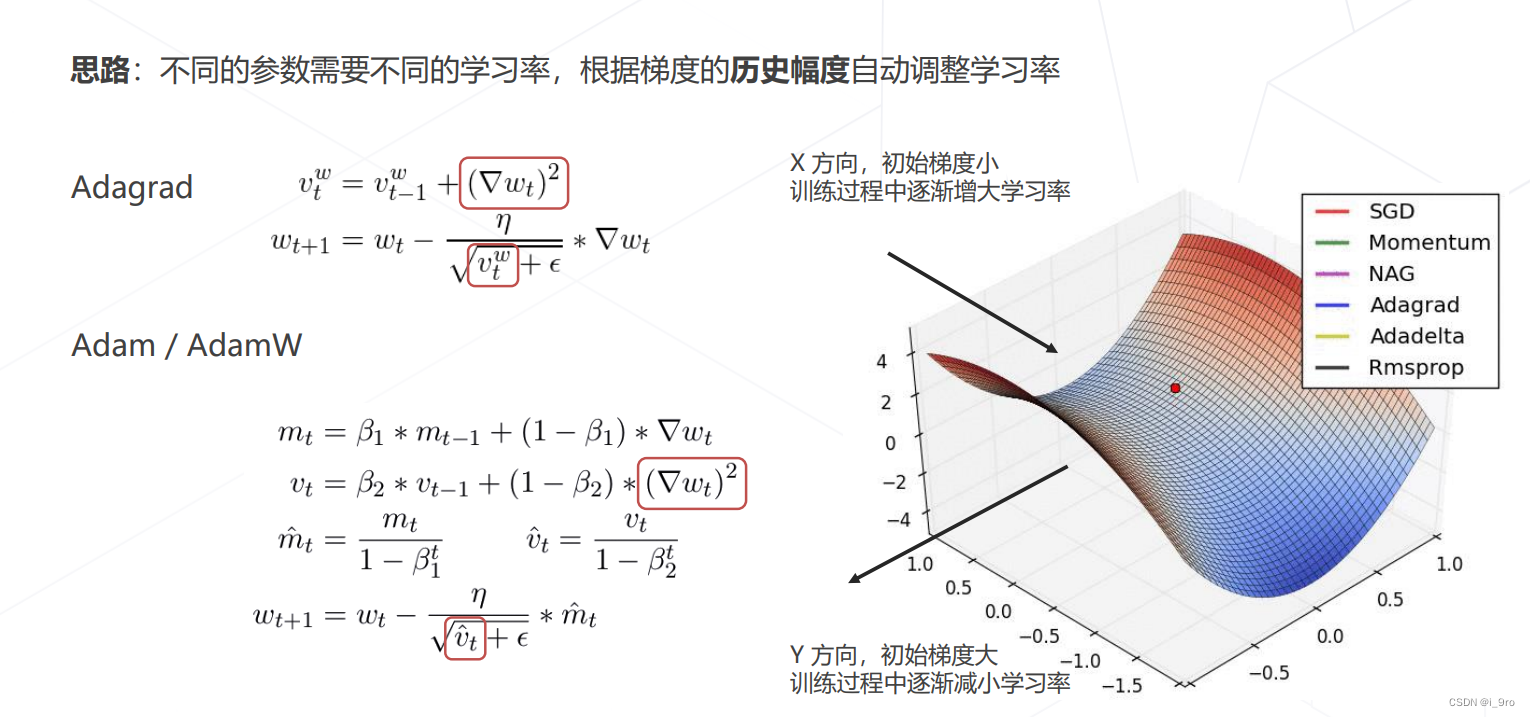
-
早停 Early Stopping
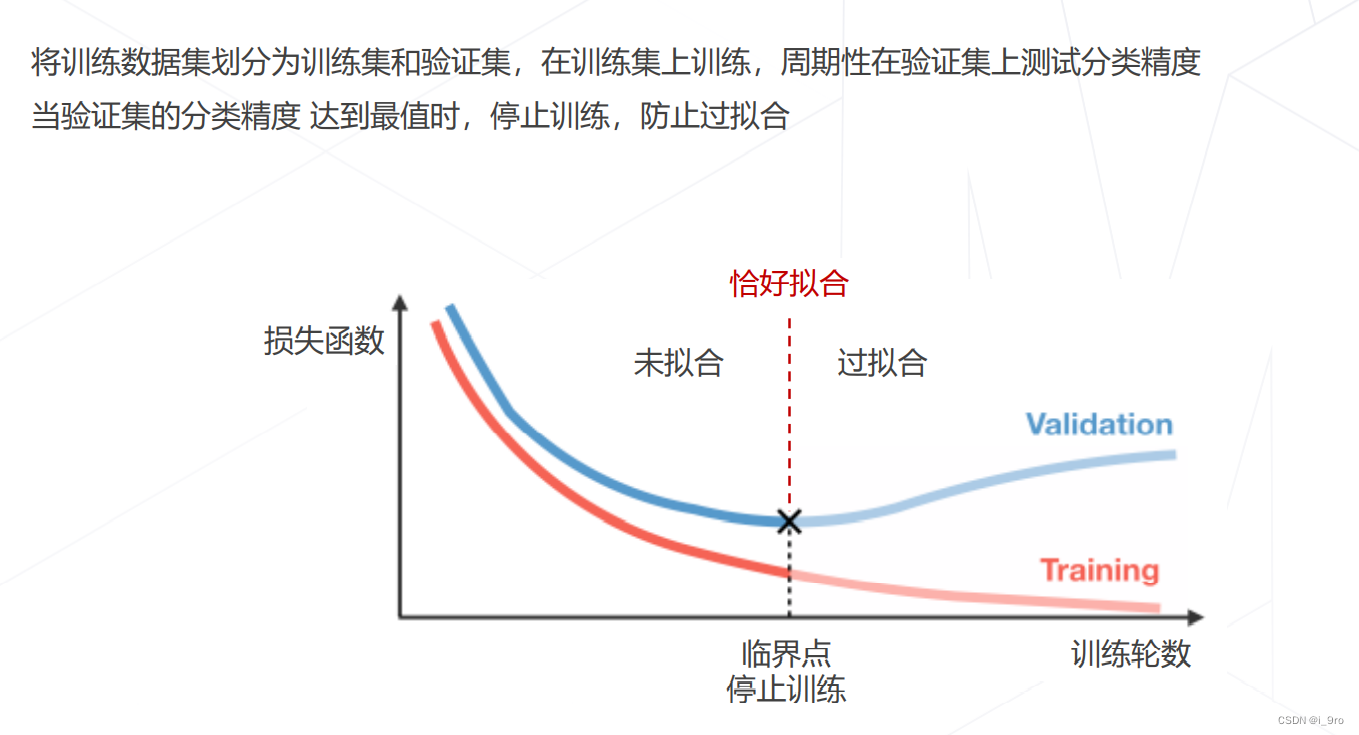
-
数据增强
训练泛化性好的模型,需要大量多样化的数据,而数据的采集标注是有成本的。
图像可以通过简单的变换产生一系列”副本”,扩充训练数据集。
数据增强操作可以组合,生成变化更复杂的图像
-
AutoAugmeng, RandAugment

-
Mixup, CutMix

-
标签平滑 Label Smoothing
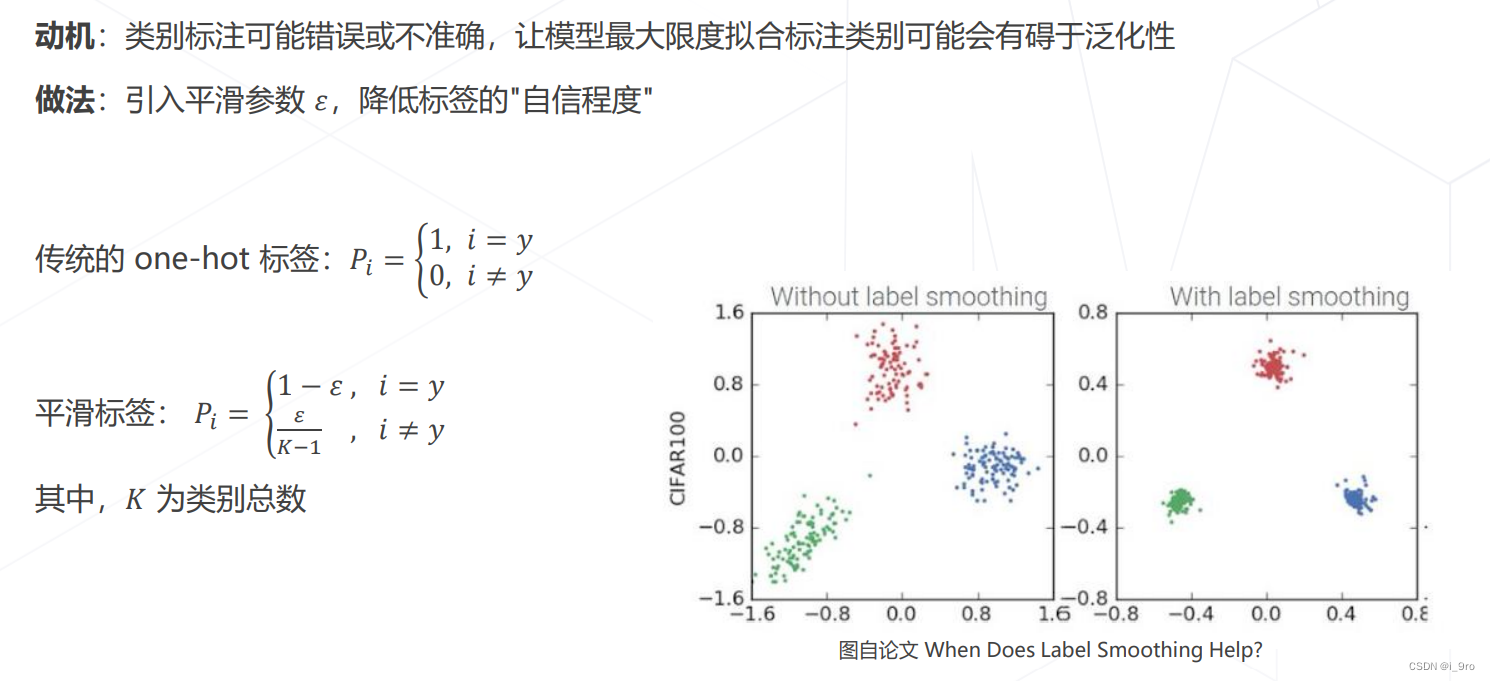
七、模型相关策略
-
Dropout
在这里插入图片描述 -
随机深度 Stochastic Depth
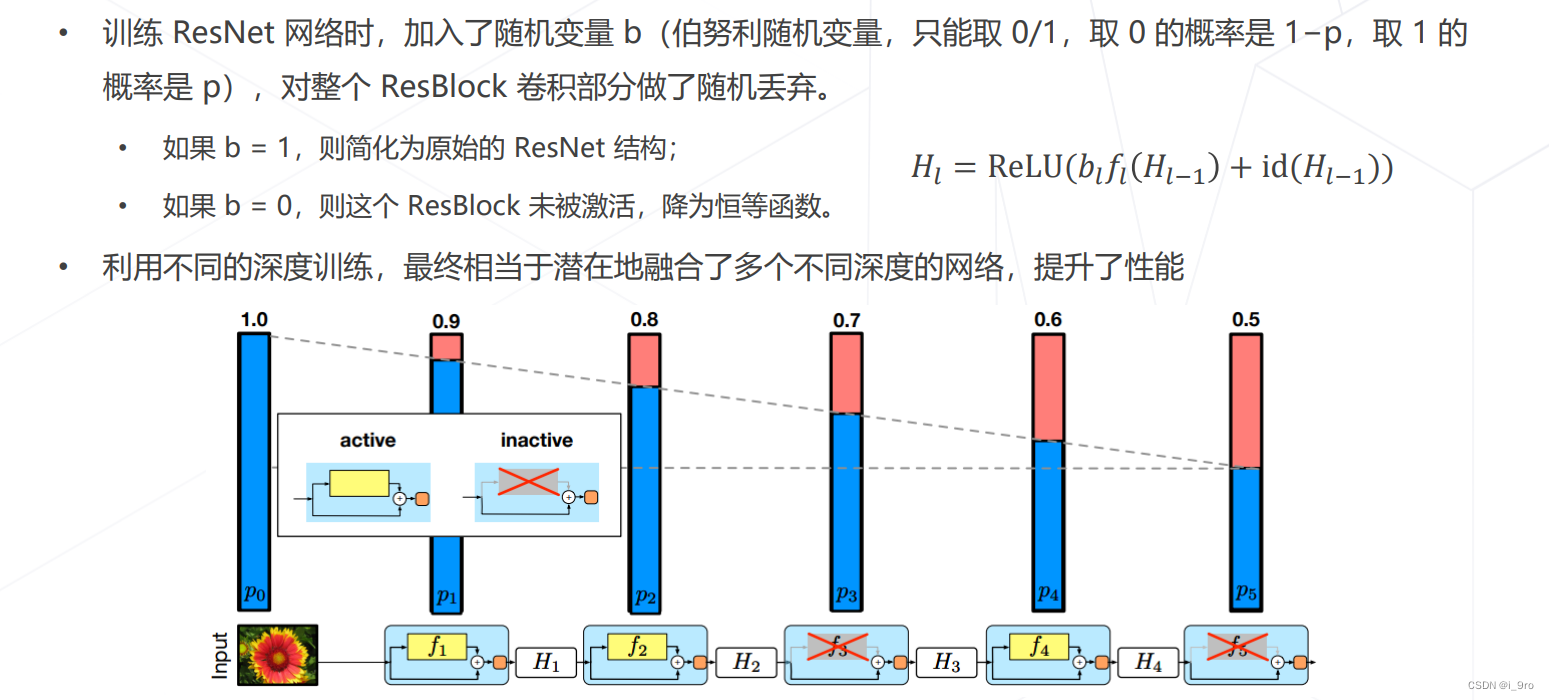
-
自监督学习
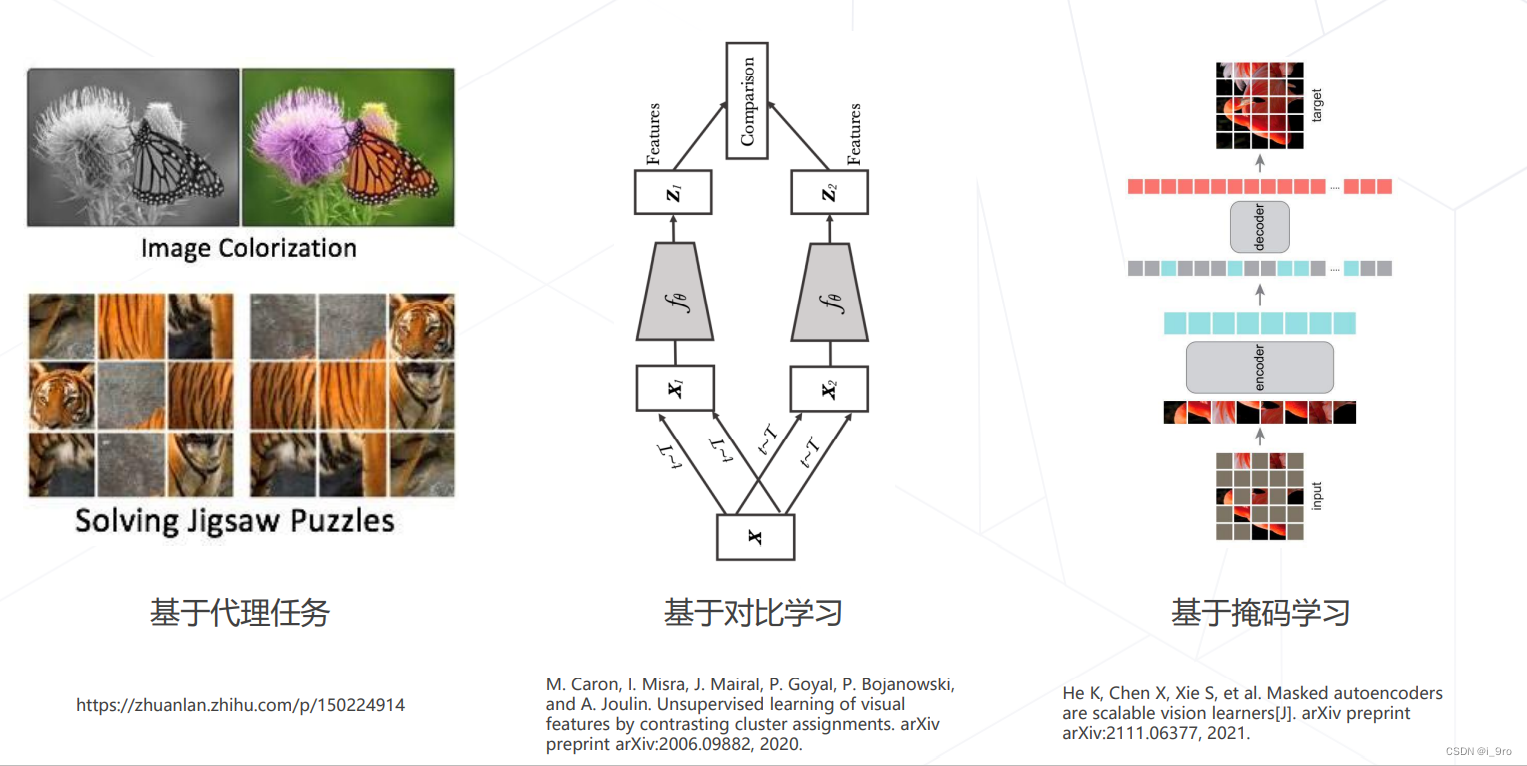
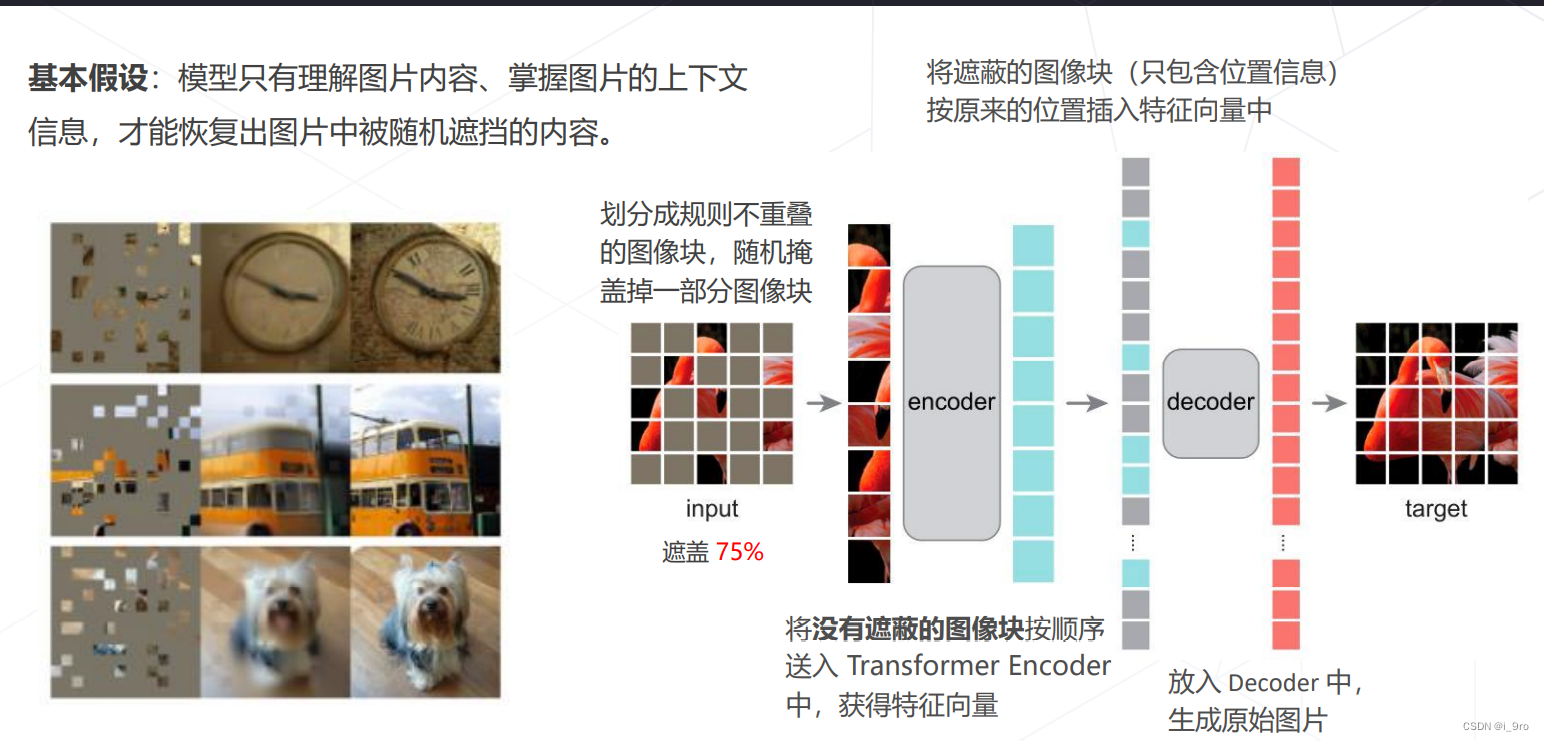
基于掩码学习
七、MMClassification