最近做人脸识别项目,想用到caffe训练自己的数据,电脑操作系统为win10+GPU,这里对caffe-windows配置、数据集制作、训练数据都做一些介绍。(无GPU配置的看
我这个博客
)。如果你用的是vs2015,那么下面介绍的caffe不适合,要用
BVLC windows分支版本的caffe
(非
微软的caffe-master
),坑有点多,安装配置可以
点这里
或
这里
,另外需要自己下载依赖库(依赖库给出下载链接,
http://pan.baidu.com/s/1cLJnkE
,密码:6vcp)。
一、GPU+windows+VS2013+caffe(微软版)配置
1、确保自己电脑有GPU,可以百度下载GPU-Z小工具查看。打开后必须支持cuda的NVIDIA显卡,做深度学习计算能力要大于3.0,我的截图如图1所示。
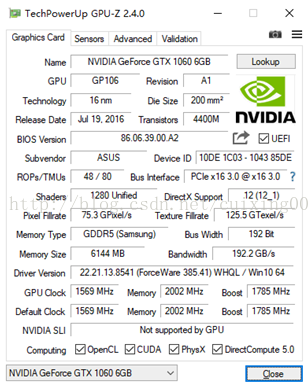
图1 GPU参数情况
2、
下载CUDA7.5或者8.0 TOOlkit 、cuDNN v4。链接分别为:
(
https://developer.nvidia.com/cuda-toolkit-archive
https://developer.nvidia.com/cudnn
),
注意我用的是VS2013版本,对应的CUDA为7.5或8.0(VS2015使用8.0),cuDNN 为v4,其中v3不支持caffe,v5部分不支持CUDA7.5,在官网需要简单注册下就可以下载。其中CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题,cuDNN是加速库。下载cuDNN如图2所示。

图2 cuDNN下载
3、从官网下载caffe版,最好是微软提供的,因为不需要自己额外再配置其他依赖库。
caffe的
微软分支
已经明确标出了支持cudnnv4.0和v5.0。这里给出下载地址:
https://github.com/Microsoft/caffe
图3 caffewindows下载
4、把下载好的库放在电脑某个文件夹下,比如我放在C:\caffe,注意解压后该文件夹下只有这1项caffe-master,其他文件后面说明。
图4 caffe目录
然后依次打开文件夹caffe-master->windows,找到“CommonSettings.props.example”复制一份到同目录下并且改后缀,删除.example即可,如下图红色框框第一个文件夹是修改后的。下一步,用记事本打开“
该文件,要修改的地方见下图5中4个红色框信息。修改后保存退出。
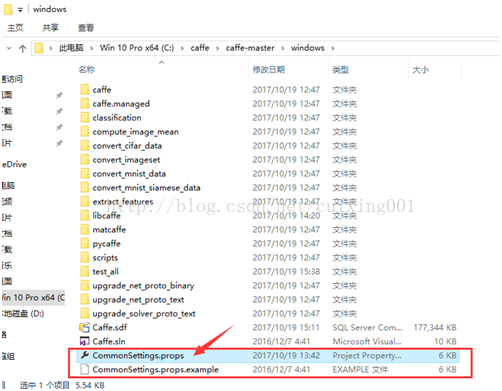
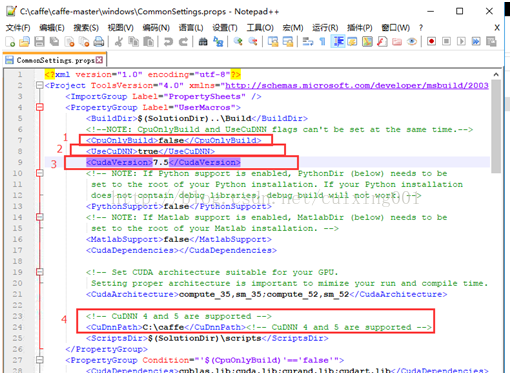
图5 CommonSettings.props修改
5
、把第2
步中下载好的cudnn-7.0-win-x64-v4.0.zip解压到C:\caffe目录下,解压后文件夹名是cuda,里面有3个文件夹,bin,include,lib.如上图4所示。
6
、编译
caffe-windows
编译用
vs2013
打开
Caffe.sln
,里面有
16
个项目,请按照图
6
核对,然后将解决方案的配置改为
X64 release
,在整个项目生成之前,
libcaffe
项目属性配置如下图
6
所示:
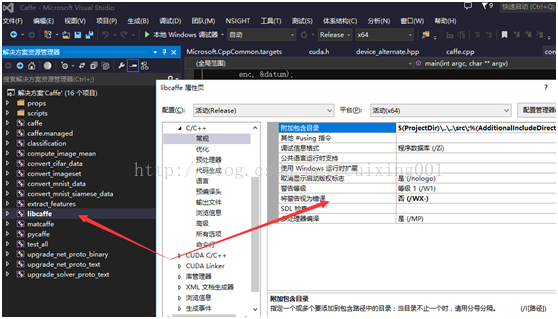
图
6 libcaffe
属性配置
先在
libcaffe
项目上右键生成,待成功后再在最上面右键点“解决方案
‘Caffe'(16
个项目
)
”
–>
生成解决方案
,会将整个项目全部生成,这个时间会比较长。
在这一步中如果遇到编译过程无法打开文件“
libcaffe.lib
”,这个问题一般是编码问题,在项目里搜索双击把
alt_sstream_impl.hpp
打开又有提示中文编码错误,点击确定后保存一下重新编译就
ok
了。多尝试几次会成功的。
编译后,会在
C:/Caffe
目录下自动生成依赖库,这就是为什么用微软版本的
caffe
。打开文件夹,请按照图
7
核对共有
16
个文件夹。

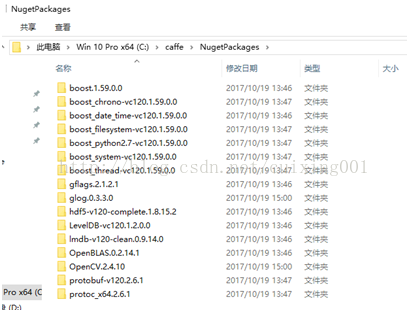
图7 依赖包库
7、在release下,直接双击打开caffe.cpp,然后ctrl+f5直接编译,出现如图8所示命令窗口说明编译成功。
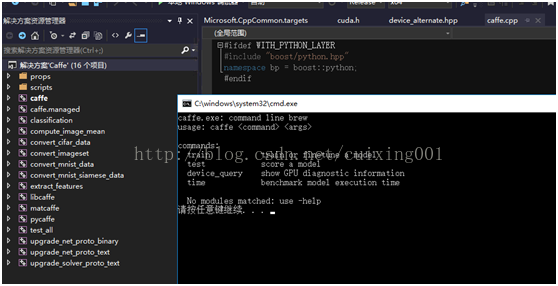
图8 编译成功画面
二、lmdb格式数据制作
function flag = createLMDBDataSets(sourcePath,outputPath)
% flag = CREATELMDBDATASETS(sourcePath,outputPath)产生caffe使用的4个文件,目的用于lmdb制作
% sourcePath:文件夹路径,包含在数据存储中的文件夹,每个文件夹是一个类别
% outputPath:输出指定的文件路径
% EXAMPLE:
% sourcePath = 'F:\imagesData\facerecognizeDataSets_label';
% outputPath = 'F:\imagesData\facerecognizeDataSets';% 产生4个文件夹,即2个txt,2个存放data图像
% createLMDBDataSets(sourcePath,outputPath)
%
if (nargin<1)||~ischar(sourcePath)
flag = false;
return;
elseif nargin == 1
outputPath = sourcePath;
end
%% 这部分修改符合自己的,每个文件夹下至少2张图
imds = imageDatastore(sourcePath,'includesubfolders',true,...
'FileExtensions',{'.png'},...
'LabelSource','foldernames');
[imdsTrain,imdsVal] = splitEachLabel(imds,0.7); % 70%用于训练,其余测试
%% random
numsTrain = length(imdsTrain.Files);
numsVal = length(imdsVal.Files);
indexTrain = randperm(numsTrain);
indexVal = randperm(numsVal);
trainCell = imdsTrain.Files(indexTrain);
valCell = imdsVal.Files(indexVal);
%% write
classesLabel = categories(imdsTrain.Labels);
nameTrain = 'train';
nameVal = 'val';
fidtrain = fopen(fullfile(outputPath,[nameTrain,'.txt']),'w');
flag2 = cellfun(@(x,path,nameflag,cllabel,fid)copyMakeFiles(x,...
outputPath,nameTrain,classesLabel,fidtrain),trainCell);
fclose(fidtrain);
fidval = fopen(fullfile(outputPath,[nameVal,'.txt']),'w');
flag1 = cellfun(@(x,path,nameflag,cllabel,fid)copyMakeFiles(x,...
outputPath,nameVal,classesLabel,fidval),valCell);
fclose(fidval);
%%
if (all(flag1) && all(flag2))
flag = true;
else
flag = false;
end
end
function flag = copyMakeFiles(x,outputPath,nameflag,classesLabel,fid)
% cellfun调用的函数
% 输入x为cell Array的一个,其余参数为传进来的
%
[temp1,name,ext] = fileparts(char(x));
[~,thisLabel,~] = fileparts(temp1);
thisFolder = fullfile(outputPath,nameflag,char(thisLabel));
if ~exist(thisFolder,'dir')
mkdir(thisFolder);
end
copyfile(x,thisFolder);
index = find(string(thisLabel) == string(classesLabel));
fprintf(fid,'%s %d\r\n',fullfile(char(thisLabel),[name,ext]),index-1);
flag = 1;
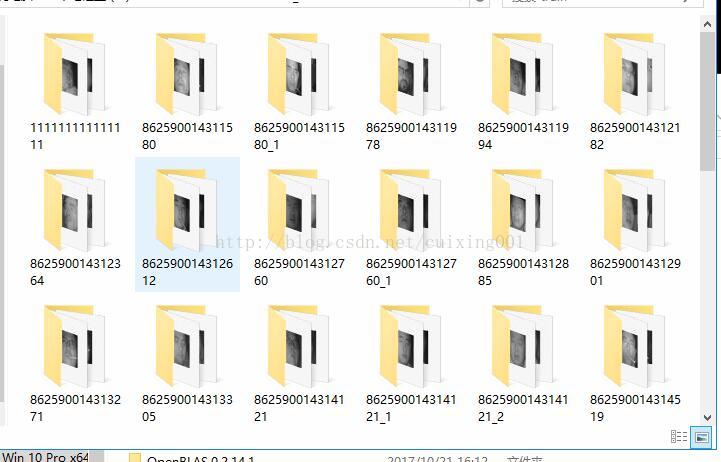
end上面代码能把图9的代码转为如图10所示的格式。
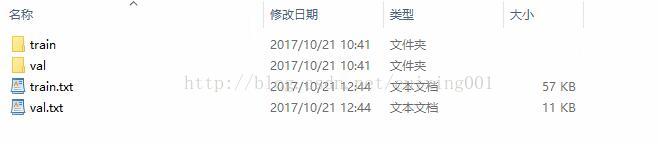
当前文件夹下
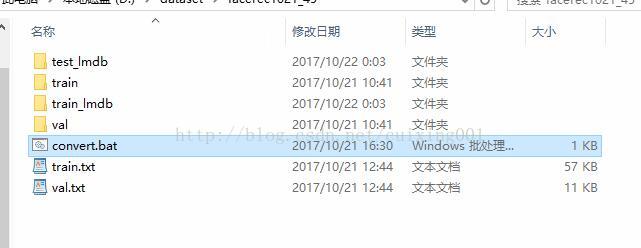
新建一个txt文档,然后改后缀为bat,名字可以是“convert”,里面实际是调用caffe的convert_imageset.exe把4个文件转换为lmdb类型。里面写入内容为“C:\caffe\caffe-master\Build\x64\Release\convert_imageset.exe –gray –resize_width=144 –resize_height=144 ./train/ train.txt train_lmdb -backend=lmdb
C:\caffe\caffe-master\Build\x64\Release\convert_imageset.exe –gray –resize_width=144 –resize_height=144 ./val/ val.txt test_lmdb -backend=lmdb
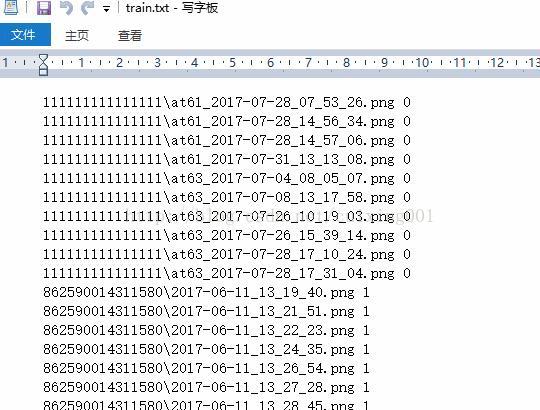
Pause ”,注意里面的路径,第一个参数是你自己的convert_imageset.exe 所在路径;第二个是转灰度;第三个,四个参数为resize的大小;第5个参数是“./train/”,表示是存放训练的文件夹(图10的train文件夹) ;第6个参数“train.txt”,表示是关联train文件夹的图片路径及类别标签,见图11所示;第7个参数是”train_lmdb”,表示的是存放的lmdb格式文件夹名字;第8个参数是”-backend=lmdb”,表示的是转换为lmdb格式。
注意每个参数之间有个空格!下面那行val参数类似。
三、训练
http://www.cnblogs.com/TensorSense/p/6744075.html
)或者
Mnist和Cifar-10(
http://blog.csdn.net/u011995719/article/details/53998331
),注意路径,我的配置文件分布如图13所示,三个run_facerec.bat、facerec1021_solver.protxt、facerec1021_lenet_train_test.protxt里面参数修改如图14所示。
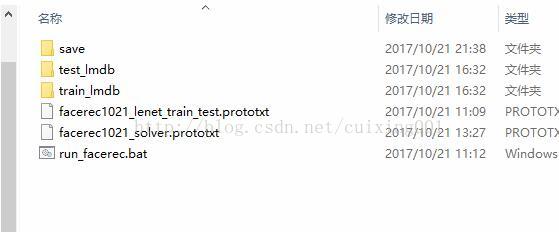
图13 文件类型分布

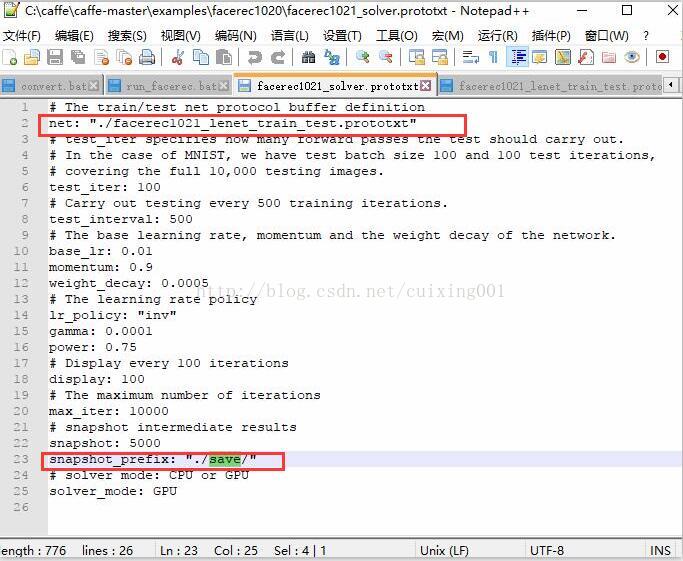
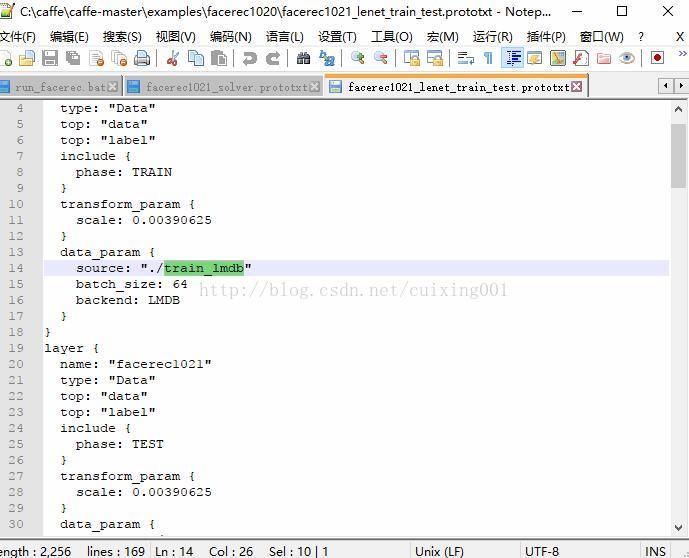
图14 三个文件的参数修改
3、上部修改后保存,然后可以运行~\(≧▽≦)/~啦,双击“
run_facerec.bat
”就可以训练,训练模型保存在save文件夹。
训练过程如图15所示。
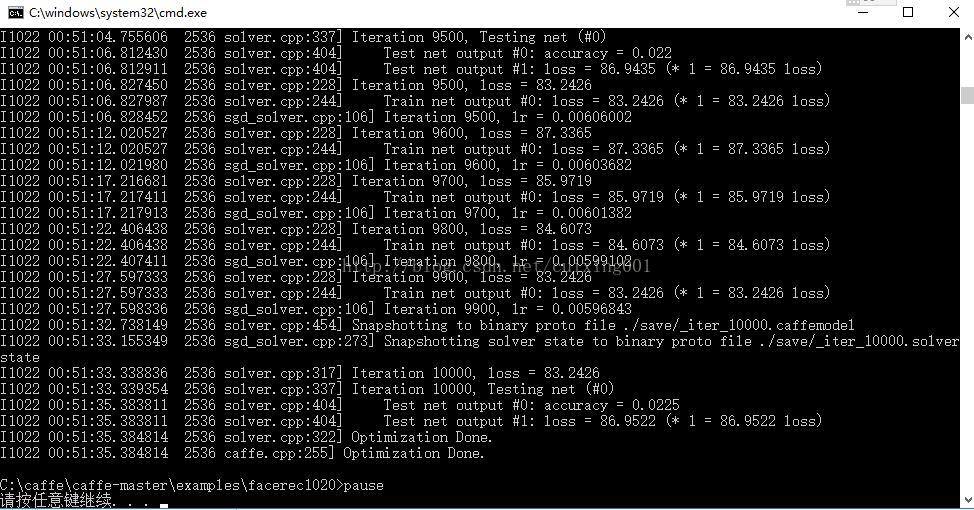
图15 训练
到此,整个流程~结束