一.引言
首先,我们需要知道什么是SLAM(simultaneous localization and mapping, 详见
SlamCN
),SLAM,即时定位与制图,包含3个关键词:实时、定位、制图,就是实时完成定位和制图的任务,这就是SLAM要解决的基本任务。按照使用的传感器分为激光SLAM(LOAM、V-LOAM、cartographer)与视觉SLAM,其中视觉SLAM又可分为单目SLAM(MonoSLAM、PTAM、DTAM、LSD-SLAM、ORB-SLAM(单目为主)、SVO)、双目SLAM(
LIBVISO2
、S-PTAM等)、RGBD SLAM(KinectFusion、ElasticFusion、Kintinous、RGBD SLAM2、RTAB SLAM);视觉SLAM由前端(视觉里程计)、后端(位姿优化)、闭环检测、制图4个部分组成,按照前端方法分为特征点法(稀疏法)、光流法、稀疏直接法、半稠密法、稠密法(详见高翔《视觉slam十四讲》第xx章);按照后端方法分为基于滤波(详见
SLAM中的EKF,UKF,PF原理简介
)与基于图优化(详见
深入理解图优化与g2o:图优化篇
与
深入理解图优化与g2o:g2o篇
)的方法。
视觉SLAM框架:
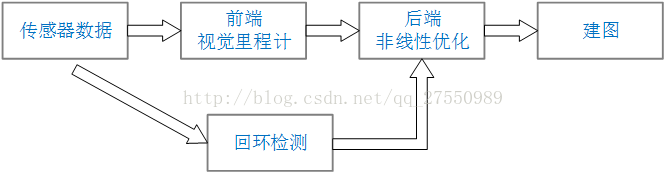
本文主要讲RGBD SLAM,RGBD SLAM属于视觉SLAM中的一种,使用的RGBD传感器包括zed(双目立体,适用于室外)、Kinect(结构光,仅限室内)、Kinect v2(TOF,主要用于室内)等(详见
深度相机简介
)。RGBD SLAM是SLAM中难度最小的,当然其具体实现也很复杂,对于不同的深度相机以及不同的应用场景,其实现也需要作出相应调整。RGBD SLAM可以应用在以下领域:室内三维建模、AR/VR、机器人室内定位导航、高精地图、自动驾驶、无人机避障与测图等;在定位与导航应用方面,SLAM朝着轻量化方向发展,而在室内三维重建方面,SLAM则越来越复杂(如BundleFusion)。
视觉SLAM应用:

二.RGBD SLAM的研究现状
1)现有的RGBD SLAM方法
(1)前端
前端就是我们所熟知的视觉里程计(VO),现有的前端方法包括特征点法、光流法、直接法、特征线面法等,简而言之,前端就是根据
几何和光度一致性
约束估计像机的运动。大多数的RGBD SLAM都是使用特征点、光流法或者直接法,较少使用特征线面等约束,原因是一般场景都能提供丰富的特征点,能适用于各种场景,而特征线面则只适用于人工场景,对于特征的使用场景,我们可以考虑使用线面提供约束条件。
ICP
:对于RGBD SLAM来说,我们可以直接使用ICP算法估计相机运动,但是几何特征缺失时,ICP法会失败;
特征点法
:优点是一般场景都能提供丰富的特征点,场景适应性较好,能够利用特征点进行重定位。缺点是特征点计算法耗时;特征点利用到的信息太少,丢失了图像中的大部分信息;对于弱纹理区域,特征点法将失去效用;特征点匹配容易产生误匹配,对结果产生很大影响。
光流法
:优点是不需要计算特征描述子,耗时短,不会产生误匹配的情况,比较稳健。缺点是它所基于的灰度不变假设是强假设,在实际环境中不成立,得到的结果不一定可靠;要求像机运动速度不能太快,不能自动曝光。
直接法
:优点是不需要计算特征点和描述子,可以得到稠密或半稠密的地图;在特征缺失时也可正常使用。缺点是与光流法一样,灰度不变假设在实际环境中不成立,得到的结果不一定可靠;要求像机运动速度不能太快,不能自动曝光。
特征线面
:优点是特征层次比点要高,不容易产生误匹配的情况。缺点是线面这样高层次的特征在场景中的数量较少。
前端需要考虑的问题:匹配策略(两两帧匹配、多帧联合匹配、当前帧与局部特征地图匹配)、缺少深度信息的特征点如何处理(2D-2D/2D-3D/3D-2D/3D-3D混合使用)、如何加速特征匹配(FLANN等)、如何让特征分布均匀、如何剔除误匹配、考虑RGBD像机的噪声特性(依据噪声进行加权)、关键帧的选择等等(lz后面会详细介绍前端的各种细节)。
(2)后端
后端就是将前端的结果进行优化,分为基于
滤波
和
图优化
(非线性优化)两种方法,现在绝大部分SLAM系统都采用图优化。基于滤波的方法包括EKF、UKF、PF等,其优点是计算量相对较小,缺点是对非线性问题进行线性化近似之后,得到的往往是次优解;基于图优化的方法包括BA、位姿图、因子图等,常用的后端优化库有g2o、ceres、gtsam。相对于前端来说,后端的方法较为成熟稳定,没有什么变化的地方(lz后面会详细介绍后端的理论知识与实践)。
(3)闭环检测
为什么要进行闭环检测呢?原因是前端得到像机轨迹会随着时间不断漂移(drift),而且累积的误差会越来越大,这样,过不了多久,我们得到的像机运动轨迹就完全不可靠。当像机走到之前来过的位置时,我们可以得到一个强有力的约束,将像机轨迹拉回到正确的地方,这就是为什么我们要大费周章的寻找闭环。从数据关联的角度讲,VO只考虑短时间的数据关联,保证局部位姿的准确性,闭环检测则考虑长时间的数据关联,保证全局位姿的准确性。常用的闭环检测的方法包括
BOW
(词袋模型)、fabmap,现在深度学习也已经应用在闭环检测。此外,我们还可以结合其他数据进行闭环检测,比如OSM。
闭环检测前后:

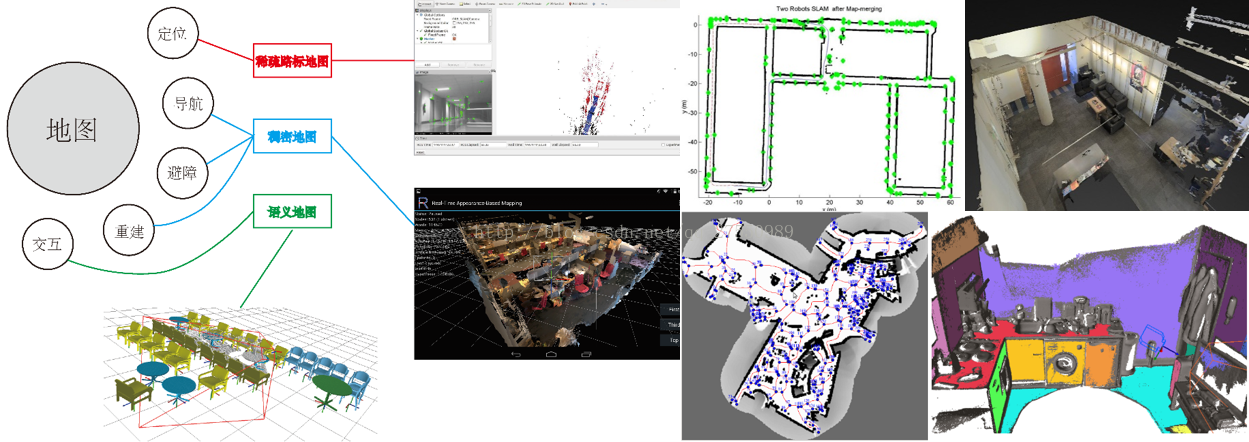
(4)制图
根据应用(定位/导航/避障/重建/交互)的不同,地图的表达类型也不同,常见的地图类型包括稀疏地图、稠密地图、语义地图、拓扑地图。
地图类型:
2)优秀RGBD SLAM介绍
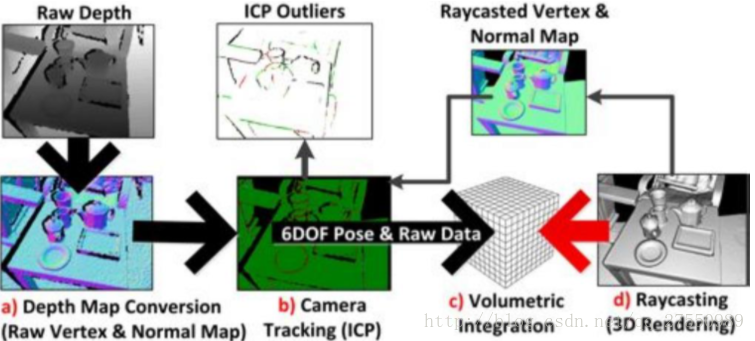
(1)KinectFusion
KinectFusion
是首个基于RGBD相机的实时三维重建系统,用深度图像生成的点云通过ICP估计相机位姿,再依据相机位姿拼接多帧点云采,并用
TSDF模型
表达重建结果。KinectFusion虽然能实时构建三维模型,但它也存在很明显的
缺点
:RGBD相机的RGB信息完全没有得到利用;为保证实时性,需要用到GPU加速,增加实现的成本;当环境主要由平行平面构成时,ICP会失败;它在对同一个环境重复建模时误差不会无限累积,但对新环境进行建模时,误差仍会累积;使用固定体积的网格模型表示重建的三维场景,因而只能重建固定大小的场景;没有使用闭环检测进行优化。
KinectFusion:
(2)ElasticFusion
ElasticFusion(见
Thomas Whelan个人主页
和
ElasticFusion解析
)充分利用RGBD相机的信息,利用RGB的颜色一致性估计相机位姿,以及利用深度图像生成点云进行ICP来估计相机位姿,通过不断优化重建的map来提高相机位姿的估计精度,最后用
surfel模型
进行地图表达。ElasticFusion的优点是充分利用颜色与深度信息,缺点是由于代码没有进行优化,它只适合对房间大小的场景进行重建。
(3)Kintinuous
Kintinuous(见
Kintinuous解析
)是对KinectFusion的改进,位姿估计通过ICP和直接法使用GPU实现,有闭环检测,并首次使用
deformation graph
对三维刚体重建做非刚体变换,使得闭环中两次重建的结果能够重合。
(4)RGBD SLAM2
RGBD SLAM2(见
rgbdslam-ROS Wiki
和
视觉SLAM实战
)是一个非常全面优秀的系统,将SLAM领域的图像特征、优化、闭环检测、点云、octomap等技术融为一体,非常适合RGBD SLAM初学者,也可以在其基础上继续开发。RGBD SLAM2的缺点是其算法实时性不好,相机必须慢速运动,此外,用点云表达三维地图很耗费内存。
(5)RTAB Map(RTAB SLAM)
RTAB Map(见
RTAB-Map’s homepage
和
RTAB-Map中文详解
)是当前最优秀的RGBD SLAM,它通过STM/WM/LTM的内存管理机制,减少图优化和闭环检测中需要用到的结点数,保证实时性以及闭环检测的准确性,能够在超大场景中运行。著名的Google Tango(见
如何评价Google 的 Project Tango
和
Google Project Tango 有哪些黑科技
)就是使用RTAB Map做SLAM,当然Tango中的RTAB Map还融合IMU等传感器数据(据说使用的是MSCKF,而且做了硬件同步)。今天还体验了一下Tango,不得不说Google的东西就是屌,无论在室内还是室外都能运行,当然室内效果更好,只要手机运动不是太快,基本上都能稳健运行,并构建mesh地图。
RTAB Map结果:

3)RGBD SLAM难点(见
知乎:视觉SLAM难点以及可能的解决思路
)
(1)相机运动太快
相机运动过快的影响:其一,相机运动过快时,帧间的重叠区变小,对于特征点法来说,同名特征点变少,对于光流法和直接法来说,灰度不变假设不成立,这将导致位姿估计不准或者没法估计(可使用广角、鱼眼、全景相机,或者多放几个相机解决);其二,相机运动过快时,rolling shutter相机会产生运动模糊,严重影响特征点的提取与匹配,以及使用直接法进行位姿估计的准确性(可使用global shutter相机解决)。
(2)视场角不够
视场角不够,帧间的重叠区自然就小(zed视场角较大,而Kinect太小),可使用视场角大的相机解决,或者多用几个RGBD相机。
(3)深度测量范围小、精度低
zed深度测量虽然可达20m,但是精度不高,而且弱纹理环境下深度很不准;Kinect深测量范围为0.5~4m,精度可达2~4mm。
(4)实时难度大
当前的许多RGBD SLAM都需要计算特征(点线面),产生巨大的计算开销,为了保证SLAM系统实时运行,我们可以通过选择计算量小的特征、并行计算、利用指令集、放到硬件上计算等手段进行加速,当然还可以减少特征点数。实时性与SLAM结果的精度存在天然的矛盾,需要在两者间进行权衡。
(5)遮挡
相机运动到墙角时,许多信息会被遮挡;相机可能会被操作人员无意遮挡。
(6)特征缺失
许多应用场景包含大面积的弱纹理区域,导致位姿估计精度低或者失败。除了增加视场范围,使用IMU,好像没有太好的办法。
(7)动态光源
变化的光源会导致特征提取与匹配的不准,也让直接法的灰度不变假设不成立;此外,强光对Kinect会产生巨大干扰。
(8)运动物体的干扰
所有的SLAM都假设环境是静止的,但是运动物体会破坏这一假设。解决办法就是检测出运动物体,减小它们的影响。
(9)时间同步
现在许多SLAM系统都使用多个传感器,这就涉及到传感器间的时间同步问题,时间同步分为软同步和硬同步。软同步当然赶不上硬同步,但是硬件时间同步只能由硬件开发商解决,对于RGBD传感器来说,这是一个相当棘手但却十分重要的问题,但是绝大多数论文都避而不谈(即使我们无法解决)。
上述问题在视觉SLAM中普遍存在,自然也在RGBD SLAM中存在,6、7、8这几个问题还在研究阶段,远达不到应用的要求,前面的几个问题倒是可以在一定程度上解决。比如使用广角相机,或者增加RGBD相机个数(时间同步问题无法解决),再或者使用IMU进行辅助(IMU优点是能测量快速运动,在视觉里程计失败时提供短时间的位姿估计)。
4)RGBD-inertial SLAM
为了解决相机运动过快、特征缺失带来的问题,以及减小运动物体的干扰,我们常常需要使用IMU辅助RGBD SLAM。相机与IMU数据融合方式(VIO概述)有多种,根据Davide Scaramuzza的分类,可以分为filter-based和optimization-based两类,这种分类与SLAM后端的分类一样;按照是否将图像特征添加到状态向量中,可以分为紧耦合与松耦合。基于滤波的松耦合的经典方法有SSF(single sensor fusion)和MSF(multi-sensor fusion)(见ETHZ的Stephen weiss的博士论文),紧耦合的经典方法有MSCKF。