文章目录
什么是索引
对于数据库中数据的查询,有:查找一个范围内的数据,或者查找一个具体的数据;
怎么查询呢
1、遍历数据库中的数据查询,显然查询速度很慢,用户的体验效果是不好的;
2、建立数据库的数据的 “目录” ,按照目录直接锁定数据可能存在的范围,提升了查询的效率,这个 “目录” ,就是索引;
索引的定义是什么
关于索引的定义的 MySQL 文档,国内的很多翻译翻译过来就变味了:
A database index is a data structure that improves the speed of operations in a table. Indexes can be created using one or more columns, providing the basis for both rapid random lookups and efficient ordering of access to records.
简单来说,索引就是一种提升了对于表操作效率的数据结构;
MySQL 选择什么样子的数据结构呢
在MySQL 中不同的存储引擎可以选择使用不同的数据结构,最终的目的都是为了提升查询的效率;
按照目前使用普遍的 InnoDB 存储引擎来说,底层的存储数据的数据结构就是 B+ 树;
常见的数据库中存储数据的索引
哈希索引
哈希表按照 key value 的形式对于等值数据的查找是一个非常好的查询方式,但是对于区间查找,哈希表需要进行全表的遍历,这个查询的效率是比较低下的;
于此同时,使用基于拉链法的哈希索引值在遇到大量的哈希碰撞的时候,查询数据的效率也是十分的慢的;
为什么InnoDB 选择使用 B+ 树而不是其他的各种各样的树进行数据的存储
二叉树
二叉树的定义:
A binary tree is a special type of tree in which every node or vertex has either no child node or one child node or two child nodes. A binary tree is an important class of a tree data structure in which a node can have at most two children.
Child node in a binary tree on the left is termed as 'left child node' and node in the right is termed as the 'right child node.'
w3c 给的定义中需要注意的是:
1、二叉树的子节点数量为 0 1 2 ;
2、最普通的二叉树是没有顺序的概念的,顺序的概念是在 二叉搜索树里面提到的;
图片来自 w3c
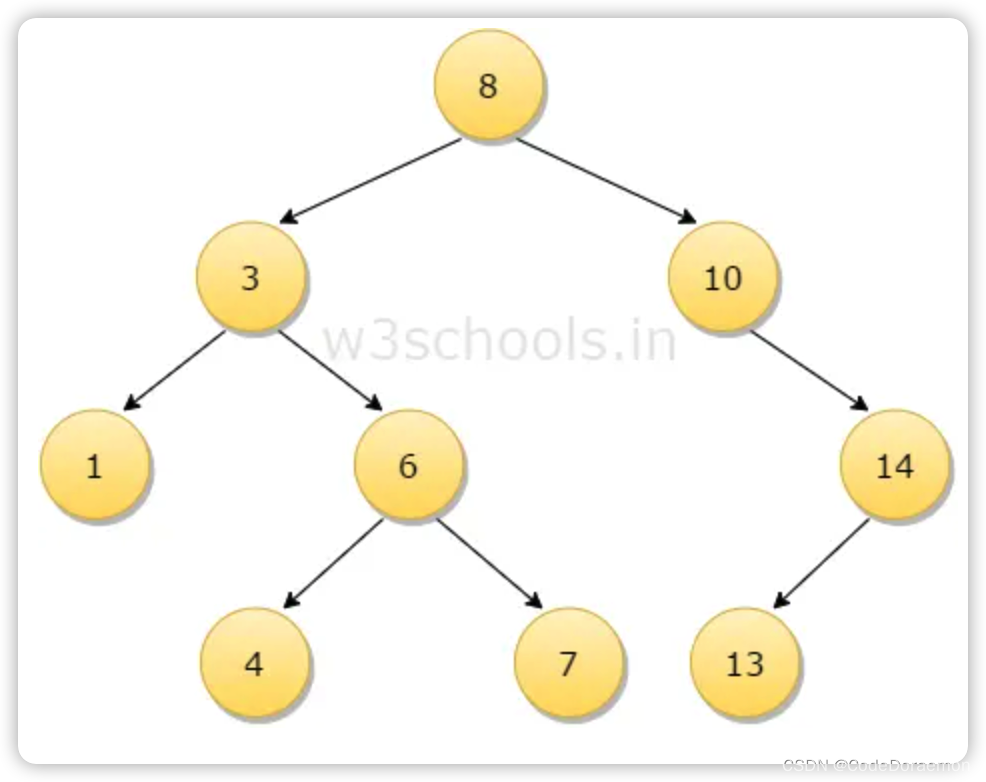
二叉树的分类
满二叉树
A full binary tree which is also called as proper binary tree or 2-tree is a tree in which all the node other than the leaves has exact two children.
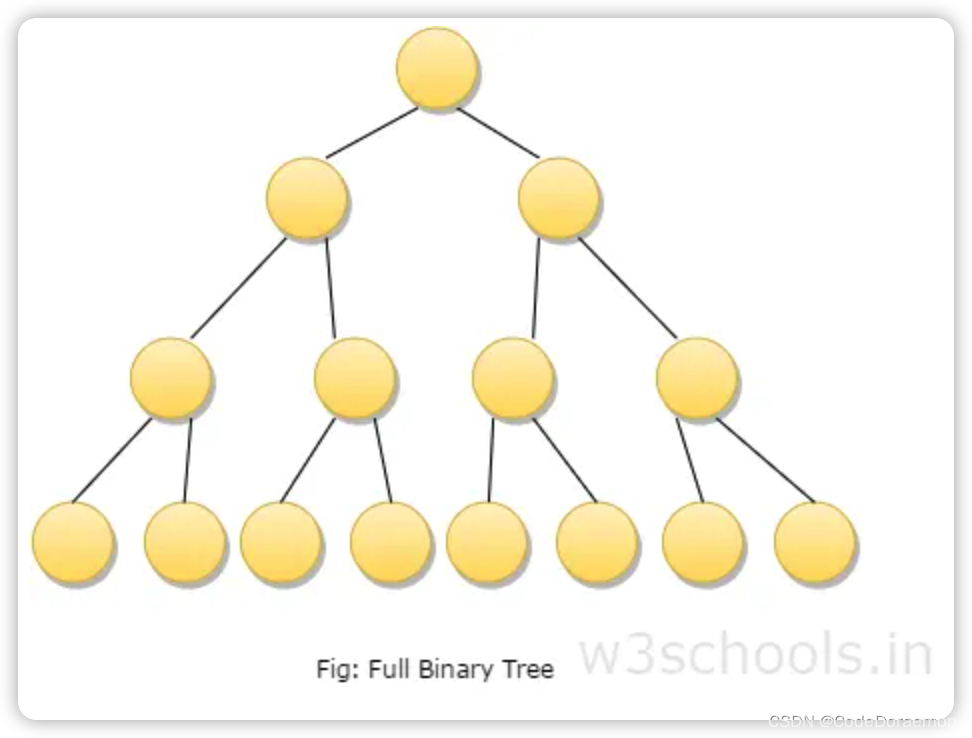
满二叉树:
除了叶子结点以外,其他的所有结点都是有用两个孩子结点的二叉树;
完全二叉树
A complete binary tree is a binary tree in which at every level, except possibly the last, has to be filled and all nodes are as far left as possible.
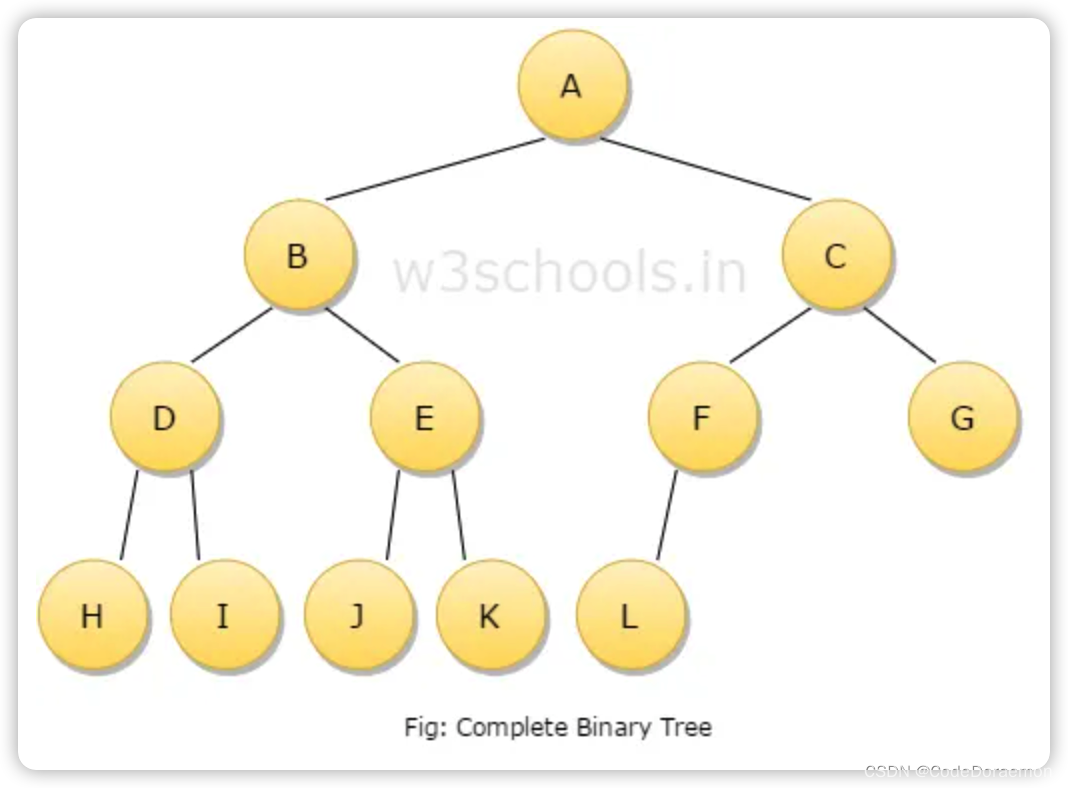
完全二叉树:
除了最后一层,其他层的每一个结点都拥有两个孩子结点,并且最后一层的结点中结点元素先要填充到左结点的位置
二叉搜索树 BST
Binary Search Tree is a node-based binary tree data structure which has the following properties:
1、The left subtree of a node contains only nodes with keys lesser than the node’s key.
2、The right subtree of a node contains only nodes with keys greater than the node’s key.
3、The left and right subtree each must also be a binary search tree.
二叉搜索树:
是二叉树的一种形式:
满足:
1、左子树的结点的数值比父节点的数值小
2、右子树的结点的数值比父节点的数值大
3、所有的子树,都是满足上面两点的
平衡二叉树 AVL 树
平衡二叉树解决了二叉查找树的多次插入可能形成的链表问题,可能导致查询的效率变低,二叉查找树的链表问题如下图中的右边部分所示;
AVL tree is a binary search tree in which the difference of heights of left and right subtrees of any node is less than or equal to one. The technique of balancing the height of binary trees was developed by Adelson, Velskii, and Landi and hence given the short form as AVL tree or Balanced Binary Tree.
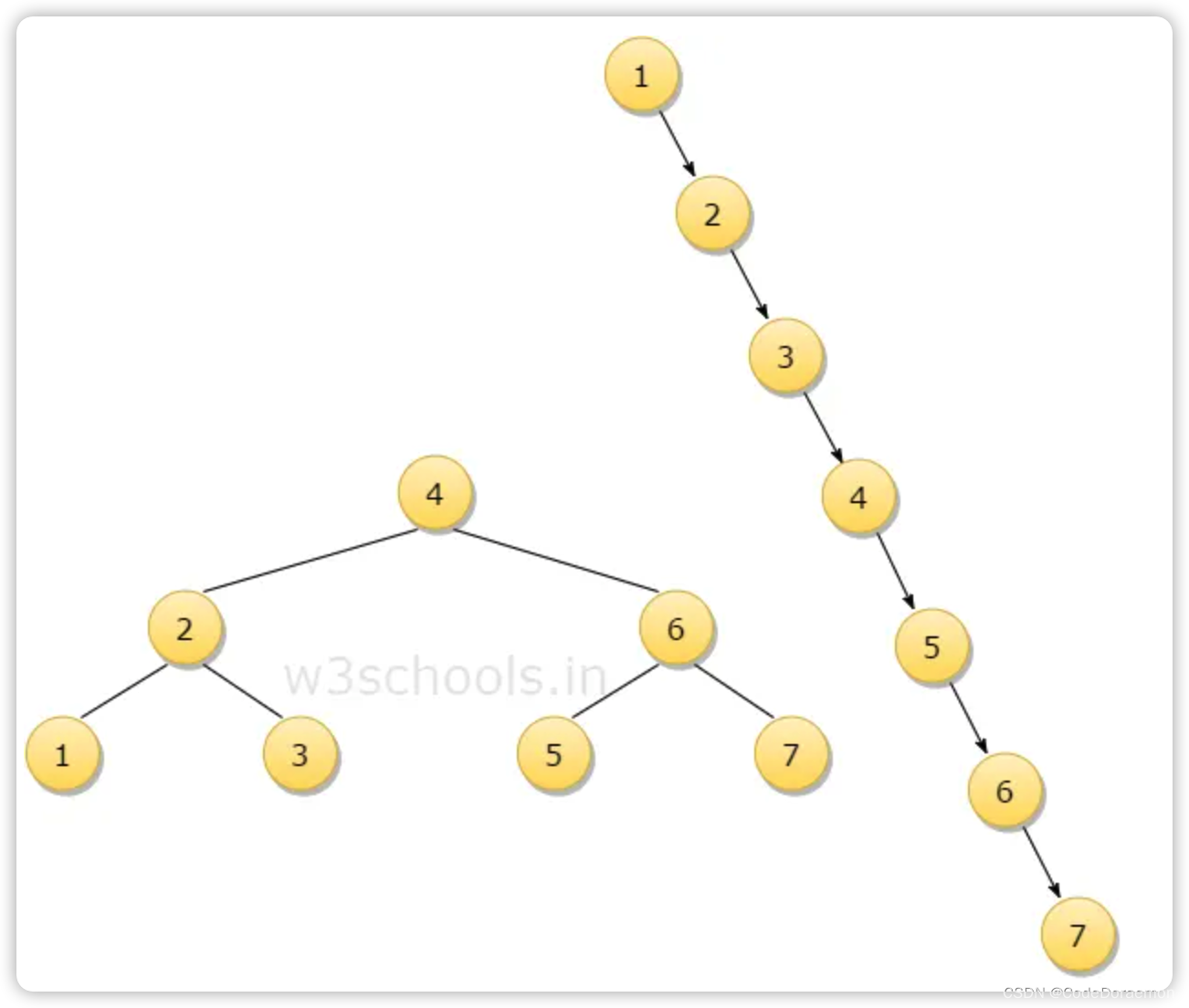
平衡二叉树的每个结点的左子树以及右子树之间的高度差不能大于等 2 ;不满足条件的话需要一个旋转的操作;
平衡二叉树也是一颗高度平衡的二叉查找树,通过旋转,保持树的平衡;
红黑树
为什么有了AVL还需要有红黑树?
红黑树并没有像AVL追求平衡,他不像AVL要求每个节点的平衡因子绝对值必须小于等于1。这样相对于AVL来说红黑树的旋转操作会更少,例如删除,插入节点操作,AVL是要从删除,增加节点到根节点的所有节点进行平衡旋转(O(logn)),而红黑树最多只需要3次就可以实现平衡O(1)(虽然通过上文实现的红黑树并不能做到,但有实现是可以的),所以红黑树更适合增删多的场景。
所以,在增删多的场景适合红黑树,查找多的场景适合AVL。
In computer science, a red–black tree is a kind of self-balancing binary search tree. Each node stores an extra bit representing "color" ("red" or "black"), used to ensure that the tree remains balanced during insertions and deletions.
自平衡的二叉查找树,在每个结点中会存储结点的颜色,在添加以及删除元素的时候,可以保持树的平衡;因为不平衡的话,会导致查询的效率大大降低;
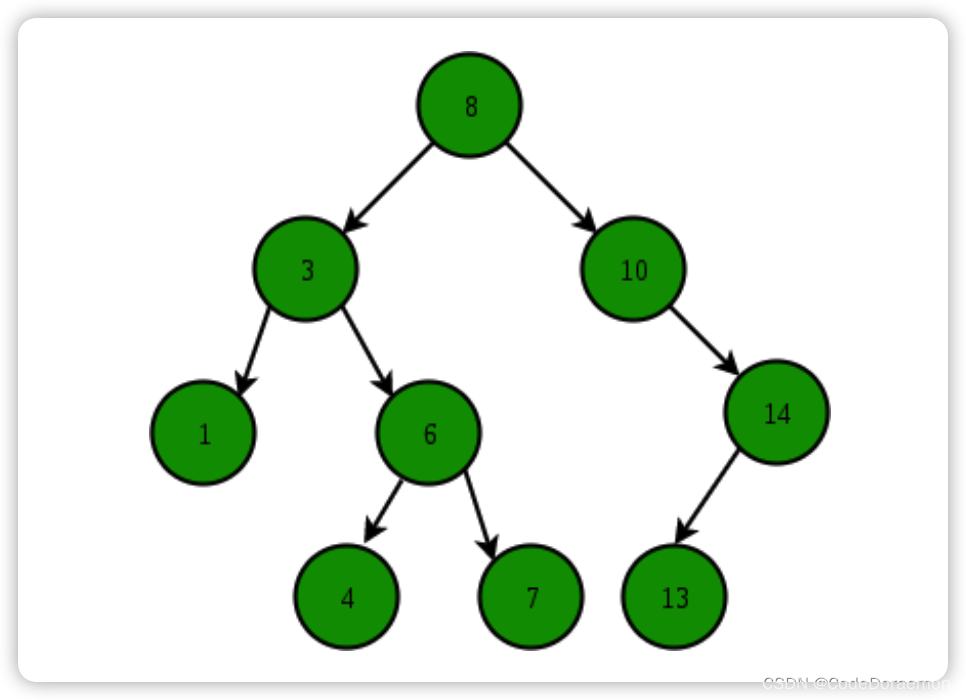
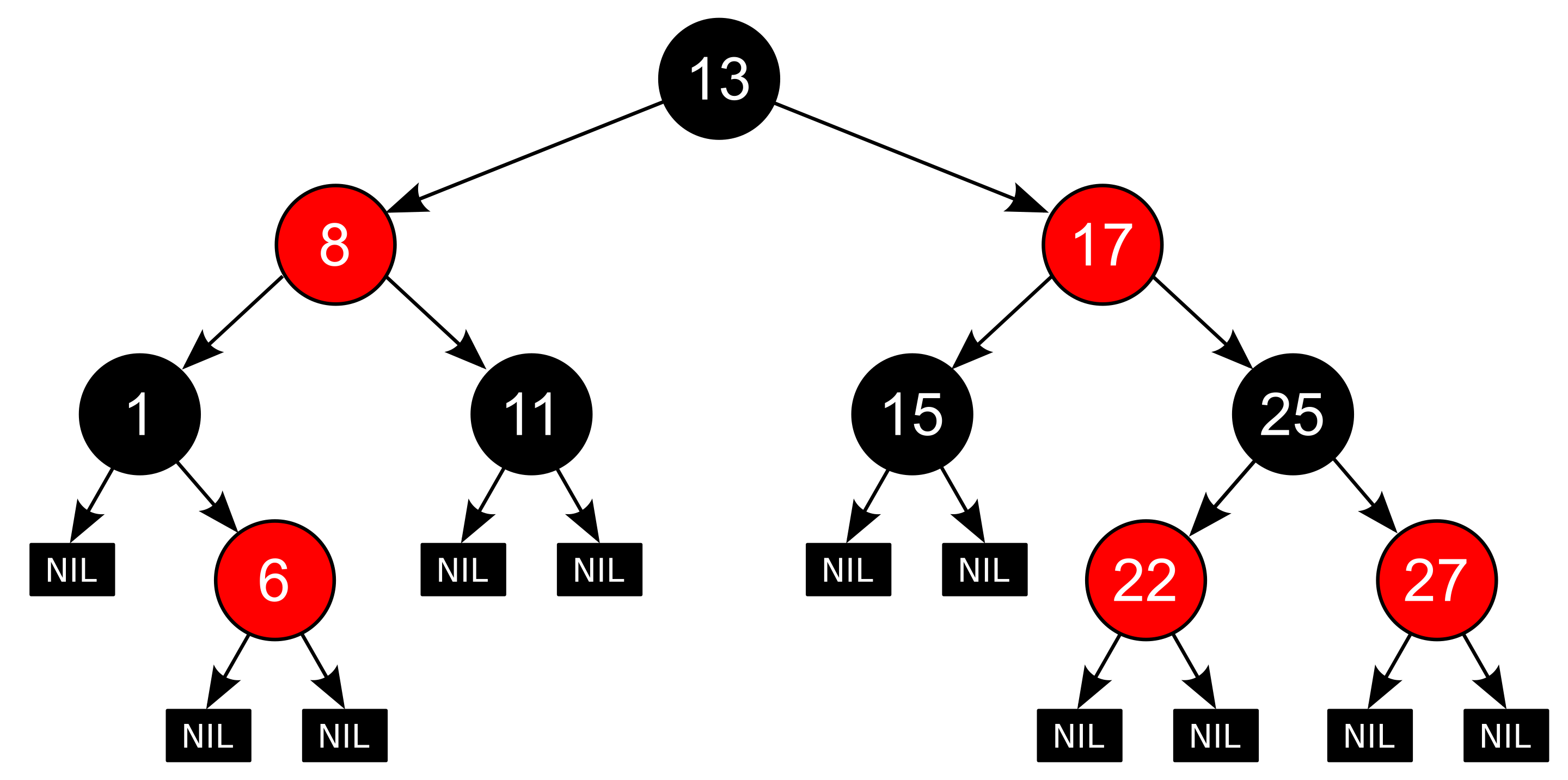
红黑树除了满足二叉搜索树的特性之外,还需要满足下面的特性:
Every node is either red or black.
All NIL
(空节点)
nodes (figure 1) are considered black.
A red node does not have a red child.
红结点的父节点一定是黑节点
Every path from a given node to any of its descendant NIL nodes goes through the same number of black nodes.
从给定节点到其子树的任意 NIL 节点的路径上面的黑色节点个数是相同的;
比如: 红色8 到 红色 6 下面的 NIL 经过的黑色结点数量是 1;红色 8 到 黑色1 下面的 NIL 结点经过的黑色节点的数量也是 1 ;
红黑树的示例:
多叉树
上面的二叉树在查询方面的效率已经非常高的,但是存在缺点,并且可以进一步的优化处理:
在二叉树中的每一个节点中只能存储一个元素,每个结点只能存放两个子节点,在数据量比较大的时候,查找一个数据在二叉树的各种结构中,需要查询的二叉树的层数是比较多的,这样层数越多,对于查询来讲,效率就会越低,使用 B 树,B+ 树,可以有效的降低树的高度,提升查询的效率;
键 与 索引 MySQL
在 MySQL 中键以及索引表示的都是一种快速操作表的数据结构(键就是索引,把所有的主键放置到B+树这种数据结构中形成的快速操作数据库表的数据结构叫做索引),这里的键可以理解为就是数据库表中的主键,通过主键建立了索引,主键的数据在底层使用 B+ 树这种数据结构进行存储,可以通过主键访问到具体的数据;
B 树
B树 是一种自平衡的多叉树,在进行插入和删除操作时也需要对结点进行旋转等操作。
B 树中的结点不仅存在键,而且存在键对应的数据,还存在子节点的引用;
注意:
键(K):可以理解为数据库表中的主键,也就是类似于 id 一类的主键;
键所对应的数据(V)(也是 Data Pointer):数据库表中的一行数据,也叫一行记录;在这个B树的结点中表现的是指向数据的指针
Tree Pointer :指向子节点的指针;
B 树的图示如下:
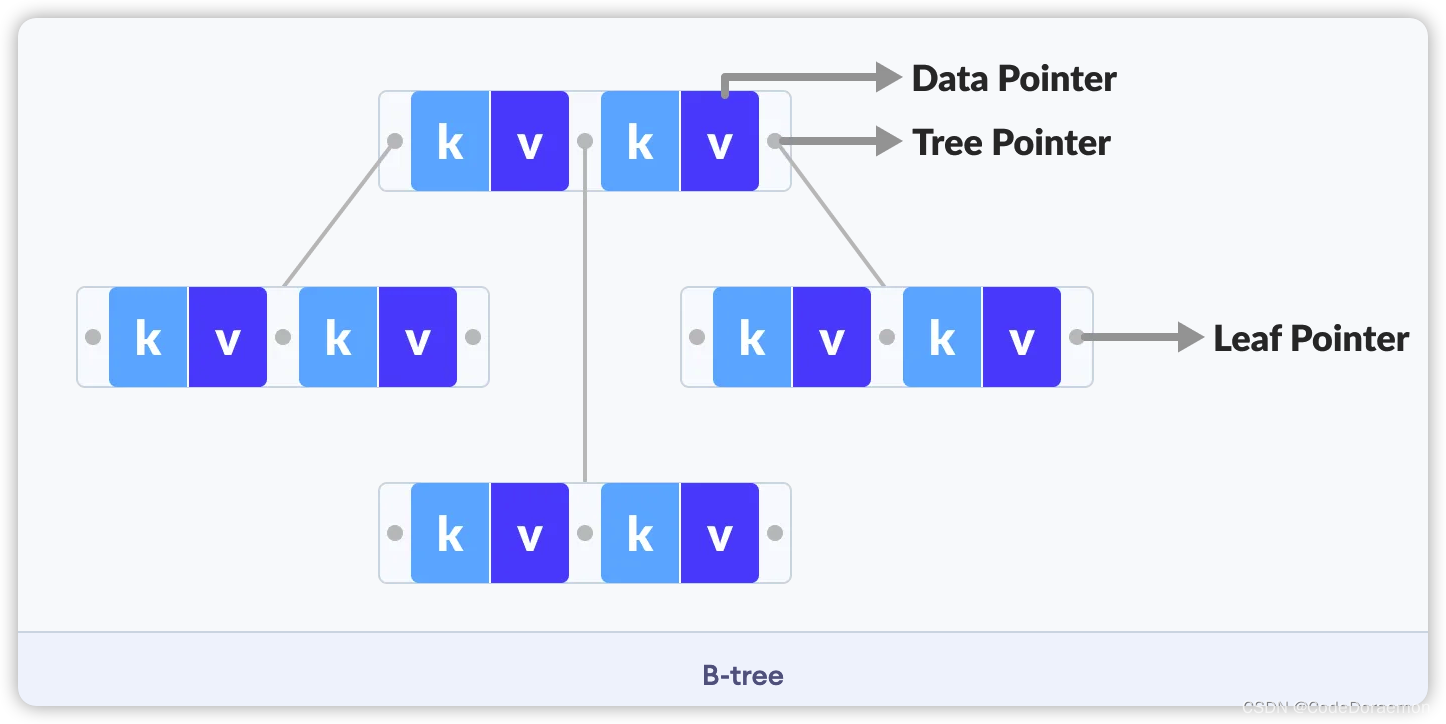
Data Pointer:B 树里面存储的数据指针
Tree Pointer : 父节点或者子节点的指针
B 树 与AVL树和红黑树相比每个节点包含的
关键字增多(每个结点包含的数据可以存在多个)
了,从而减小了树的深度,可以相对减少磁盘IO的次数。
特别是在B树应用到数据库中的时候,数据库充分利用了磁盘块的原理
(磁盘数据存储是采用块的形式存储的,每个块的大小为4K,每次IO进行数据读取时,同一个磁盘块的数据可以一次性读取出来,磁盘的物理设计,利用物理设计与数据结构相互结合)
把节点大小限制和充分使用在磁盘快大小范围;把树的节点关键字增多后树的层级比原来的二叉树少了,减少数据查找的次数和复杂度,因此B树被广泛用于文件系统及数据库中
B树的弊端:
1、B树的查找不稳定,最好的情况就是在根节点查到了,最坏的情况就是在叶子结点查到。
2、B树在遍历方面比较麻烦,由于需要进行中序遍历,所以也会进行一定数量的磁盘IO。
3、除非完全重建数据库,否则无法改变键值的最大长度。这使得许多数据库系统将人名截断到70字符之内。
为了解决这些问题,出现了B+树。
B树相对于B+树的优点是,如果经常访问的数据离根节点很近,而B树的非叶子节点本身存有关键字其数据的地址,所以这种数据检索的时候会要比B+树快。
B+ 树
注意:
键(K):可以理解为数据库表中的主键,也就是类似于 id 一类的主键;
键所对应的数据(V)(也是 Data Pointer):数据库表中的一行数据,也叫一行记录;在这个B树的结点中表现的是指向数据的指针
Tree Pointer :指向子节点的指针;
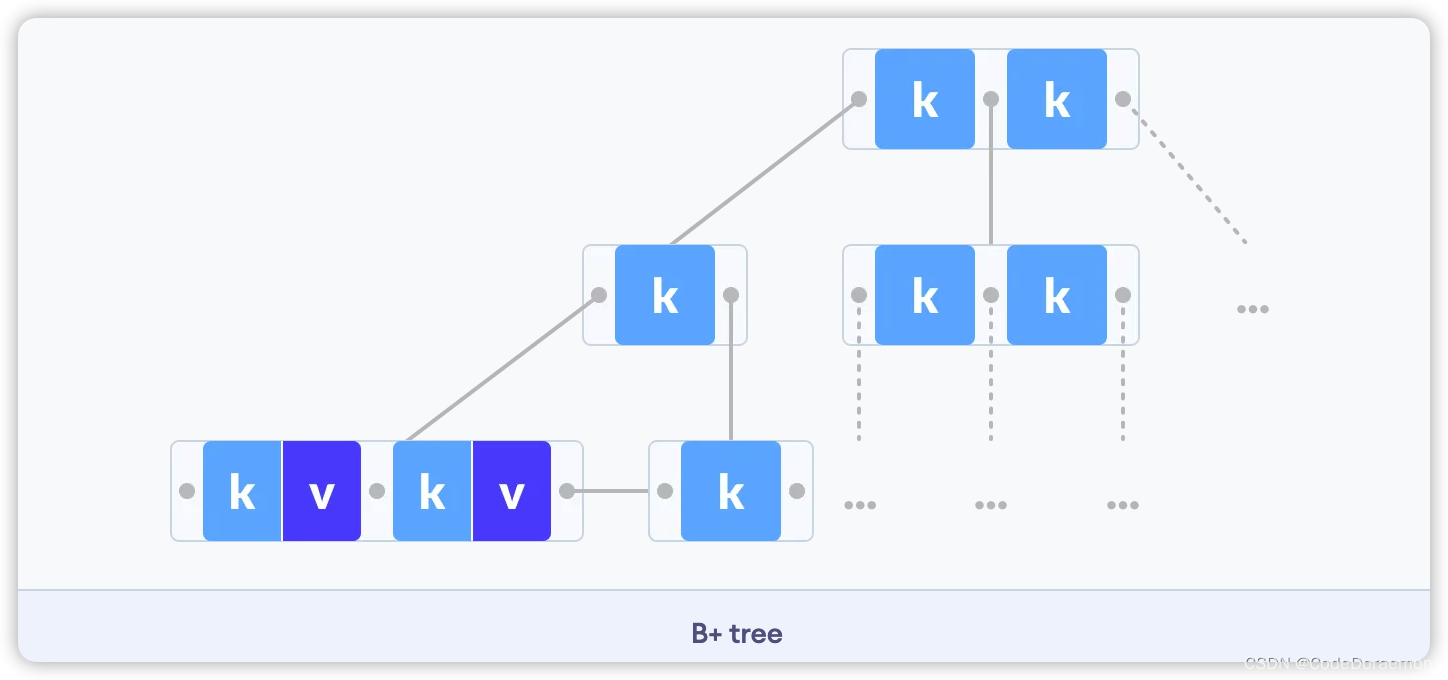
将上面的树展开有:
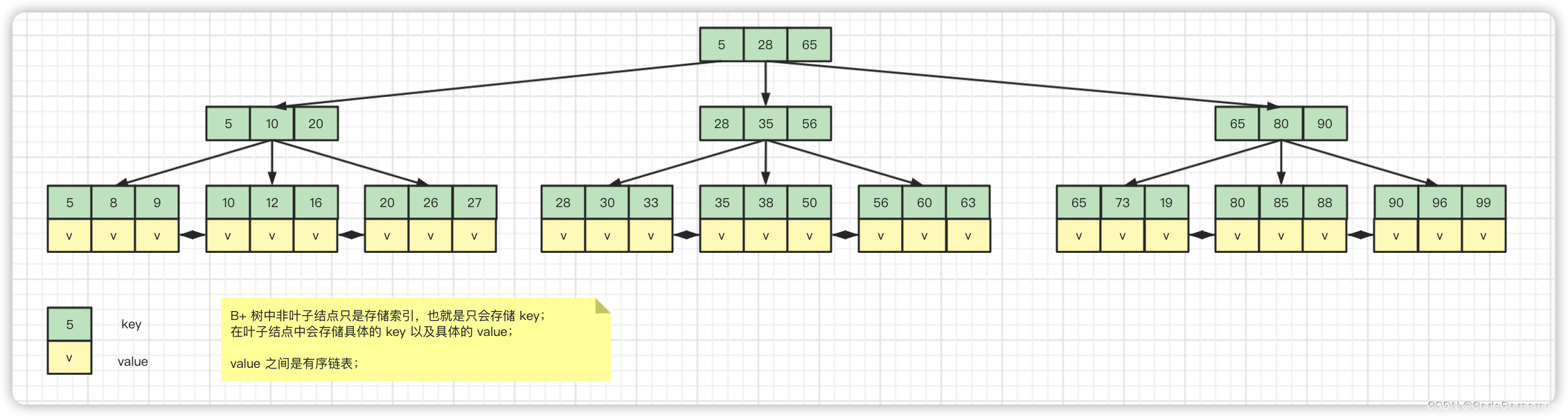
注意:InnoDB 底层的数据存储维护的是一个双向链表,方便进行区间查询
B+ 树的定义:
1、B+ 树内存分为叶子结点以及非叶子结点:
非叶子结点只是存储索引,叶子结点存储相关的数据
2、底层的叶子结点之间形成了一个有序链表,方便了区间查询
3、 m 阶 B+ 树非根节点的子节点的数量是:取整(m/2)<= x <= m
B+树的优点:
1、B+树的层级更少:非叶子结点中存放的元素不存放数据,所以每一层可以容纳更多元素,比B-树更加“矮胖”,也就是磁盘中的每一页可以存放更多元素。这样在查找时,磁盘IO的次数也会减少
2、B+树查询速度更稳定:每次查找都必须匹配到叶子节点,因此每一次查找都是稳定的。B-树由于中间节点也携带数据,因此只需要匹配到要查找的元素即可,最好的情况是在根节点就结束查找,最坏的情况是在叶子节点结束查找,查找性能不稳定
3、B+树天然具备排序功能:B+树所有的叶子节点数据构成了一个有序链表,在范围查询数据时候更方便,数据紧密性很高,缓存的命中率也会比B-树高。
4、B+树全节点遍历更快:B+树遍历整棵树只需要遍历所有的叶子节点即可,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描
5、因为在 B+ 树的底层维护了一个链表,所以进行区间查询的效率也是比较高的; B 树在进行区间查询的时候,需要使用中序遍历,效率是比 B+ 树要低一点的;
B 树与 B+ 树直接的区别
The data pointers are present only at the leaf nodes on a B+ tree whereas the data pointers are present in the internal, leaf or root nodes on a B-tree.
The leaves are not connected with each other on a B-tree whereas they are connected on a B+ tree.
Operations on a B+ tree are faster than on a B-tree.
简单来说:
1、B 树可以在非叶子结点中存储数据的指针,但是 B+ 在非叶子结点中存储的只有索引的指针,也就是键的指针
2、只有 B+ 树在底层的叶子结点之间存在双向链表
3、B+ 树的运行效率优于 B 树
为什么不用AVL或红黑树?
我们假设B+树一个节点可以有100个关键字,那么3层的B树可以容纳大概1000000多个关键字
(100+101*100+101*101*100)
。而红黑树要存储这么多至少要20层。所以使用B树相对于红黑树和AVL可以减少IO操作
为什么不用数组或链表?
链表查询速度慢。数组要开辟连续空间不可能。
为什么不用哈希表?
Innodb能够进行范围查询,哈希表无法实现。例如模糊查询很难用哈希表实现;
为什么不用B树?
在 InnoDB 中最小的读写单位默认是 16 k(可以设置),也就是一个 B+ 树的结点或者 B 树结点的大小是 16 k, 如果这个结点是 B 树,里面的 value 占据了一定的空间,使得索引的空间就变少了,使得 B 树变高了,使得 IO 操作变多了,效率就下降了;
为什么InnoDB,默认的最小读写单位是 16 k?
这个和硬件方面的磁盘知识有关,一般的系统的 IO 操作的最小单元是 8 个扇区,也就是 4KB ,设置太小进行的 IO 操作太多,会降低效率;16K 是一个权衡的结果;
1、B+树只有叶子节点存放数据,而其他节点只存放索引,而B树每个节点都有Data域。所以相同大小的节点 B+ 树包含的索引比 B 树的索引更多(因为B树每个节点还有Data域),这样子使得 B+ 树比 B 树更低,换句话说, B+ 树可以使用更少的 IO 操作完成一 次数据的查询效率就提高了;
2、B+树的叶子节点是通过链表连接的,所以找到下限后能很快进行区间查询,比B树中序遍历快;
终极结论
因为 B+ 树的高度目前来讲实现是最低的,造成的 IO 数量是最少的,所以对于数据库这种需要大量的 IO 操作的情况下,效率是比较好的;
小结
本文从什么是索引,MySQL InnoDB 为什么使用 B+ 树出发,介绍了索引的相关官方概念,介绍了不同的树结构的定义以及相关树的特点,阐述了为了不使用其他数据结构作为 InnoDB 底层保存的实现方式;
参考