一、实验目的
(1)通过上机实验,加深对语法制导翻译原理的理解,掌握将语法分析所识别的语法范畴变换为某种中间代码的语义翻译方法。
(2)掌握目前普遍采用的语义分析方法─语法制导翻译技术。
(3)给出 PL/0 文法规范,要求在语法分析程序中添加语义处理,对于语法正确的表达式,输出其中间代码;对于语法正确的算术表达式,输出其计算值。
二、实验内容
(1)语义分析对象重点考虑经过语法分析后已是正确的语法范畴,本实验重点是语义子程序。已给 PL/0 语言文法,在实验二或实验三的表达式语法分析程序里,添加语义处理部分,输出表达式的中间代码,用四元式序列表示。
(2) PL/0 算术表达式的语义计算:
PL/0 算术表达式,例如:2+3
5 作为输入。
输出: 17
PL/0 表达式的中间代码表示:
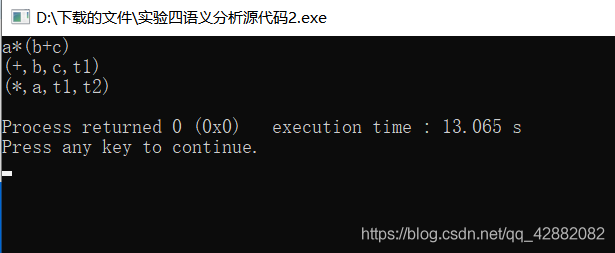
PL/0 表达式,例如: a
(b+c)。
输出: (+,b,c,t1)
(,a,t1,t2)
三、设计思想
1.原理
属性文法
:是在上下文无关文法的基础上为每个文法符号(终结符或非终结符)配备若干个相关的“值”(称为属性)。
属性
:代表与文法符号相关的信息,和变量一样,可以进行计算和传递。
综合属性
:用于“自下而上”传递信息。
在语法树中,一个结点的综合属性的值,由其子结点的属性值确定。
S—属性文法
:仅仅使用综合属性的属性文法。
语义规则
: 属性计算的过程即是语义处理的过程。对于文法的每一个产生式配备一组属性的计算规则,则称为语义规则。
(1)终结符只有综合属性,它由词法分析器提供。
(2)非终结符既可以有综合属性也可以有继承属性,文法开始符号的所有继承属性作为属性计算前的初始值。
(3)产生式右边符号的继承属性和产生式左边符号的综合属性都必须提供一个计算规则。
(4)产生式左边符号的继承属性和产生式右边符号的综合属性由其它产生式的属性规则计算。
一遍扫描的处理方法
: 与树遍历的属性计算方法不同,一遍扫描的处理方法是在语法分析的同时计算属性值,而不是语法分析构造语法树之后进行属性的计算,而且无需构造实际的语法树。
因为一遍扫描的处理方法与语法分析器的相互作用,它与下面两个因素密切相关:
(1)所采用的语法分析方法。
(2)属性的计算次序。
2.基于递归下降翻译器的设计
递归下降分析法的原理是利用函数之间的递归调用来模拟语法树自上而下的构建过程。从根节点出发,自顶向下为输入串中寻找一个最左匹配序列,建立一棵语法树。对于每个非终结符的继承属性当作形式参数,函数的返回值当作非终结符的继承属性;对于终结符要初始化所有的继承属性。再进行分析过程中,非终结符根据当前的输入符号决定使用哪个产生式候选。
递归下降分析器的设计实现思想:
1、对每个非终结符A构造一个函数过程,对A的每个继承属性设置一个形式参数,函数的返回值为A的综合属性(作为记录,或指向记录的一个指针,记录中有若干域,每个属性对应一个域)。
2、非终结符A 对应的函数过程中,根据当前的输入符号决定哪个产生式候选。
3、每个产生式对应的代码中,按照从左到右的次序,对于单词符号(终结符),非终结符和语义分析分别做以下的工作。
(1)对于带有综合属性x的终结符X,把x的值存入为X.x设置的变量中。然后产生一个匹配X的调用,并继续读入一个输入符号。
(2)对于每个非终结符号B,产生一个右边带有函数调用的赋值语句c=B(b1,b2,…,bk)
(3)对于语义动作,把动作的代码抄进分析器中,用代表属性的变量来代替对应属性的每一次引用。
算法原理
1.设计出每个非终结符的文法识别过程。
2.将输入数据进行处理,提取出单词的编码。
3.每一个非终结符对应于一个函数(子过程),非终结符所对应的右侧产生式为函数体;为每个非终结符写识别递归函数。
4.每遇到一个终结符,则需要判断所输入字符是否与之匹配,若匹配则读取下一个,若不匹配,则进行出错处理。
5.函数相互调用。
加入递归下降翻译器子程序伪码:
表达式递归下降子程序为:
function表达式:string;
string s1, s2, s3, result;
BEGIN
IF SYM=’+’ OR SYM=’-’ THEN
ADVANCE;
ELSE IF SYM =FIRST(项)
ELSE ERROR;
BEGIN
s1:=项;
END;
WHILE SYM=’+’ OR SYM=’-’ THEN
BEGIN
ADVANCE;
S2:=项;
result := newtemp();
emit(SYM,s1,s2,result);
s1:= result;
END;
Return result;
END;
项递归下降子程序为:
function 项:string;
string s1, s2, s3, result;
BEGIN
IF SYM =FIRST(因子) THEN
BEGIN
s1:=因子;
END;
ELSE ERROR;
WHILE SYM =’’OR SYM=’/’ THEN
IF SYM =FIRST(因子) THEN
BEGIN
ADVANCE;
S2:=因子;
result := newtemp();
emit(SYM,s1,s2,result);
s1:= result;
END;
Return result;
END;
因子递归下降子程序为:
function 因子:string;
string s;
BEGIN
IF SYM =’(’ THEN
ADVANCE;
s:=表达式;
ADVANCE;
IF SYM=’)’ THEN
ADVANCE;
Return s;
ELSE ERROR;
ELSE IF SYM =FIRST(因子) THEN
ADVANCE;
ELSE ERROR;
END;
四、源程序及调试运行结果
1.源程序代码
:
#include <iostream>
#include<bits/stdc++.h>//万能头文件
using namespace std;
pair<string, string> results[50]; // results保存词法分析结果,第一个sring存单词类型,第二个string存单词的值
int lexI = 0; // results的指针
void Lexical_Analysis()/*lexI为results的长度,即单词数*/
{
string inputs; // 输入字符串
cin >> inputs;
map<string,string> words;//应用map数据结构形成一个string->string的对应
std::map<string,string>::iterator it;//用来遍历整个对应关系的迭代器
//对应关系进行初始化,如下只包括了表达式的相关符号
words["+"]="plus";
words["-"]="minus";
words["*"]="times";
words["/"]="slash";
words["="]="eql";
words["("]="lparen";
words[")"]="rparen";
int input_size=inputs.length(); //输入字符串的长度
string word; // 字符识别
for(int i=0; i<input_size; i++)
{
while(inputs[i] == ' ' || inputs[i] == '\n')//若最开始为空格或换行符,则将指针的位置往后移
i++;
if(isalpha(inputs[i])){//对标识符和基本字进行识别,调用库函数isalpha()
word = inputs[i++];
while(isalpha(inputs[i]) || isdigit(inputs[i]))
word += inputs[i++];
it = words.find(word); // 在map中找到相应的词性,并输出
if(it != words.end())//判断是不是基本字,若为基本字则进行输出
results[lexI++] = make_pair(words[word], word);//创建新的pair对象
else
results[lexI++] = make_pair("ident", word);
i--;
}
else if(isdigit(inputs[i])){//判断是不是常数,调用库函数isdigit()
word=inputs[i++];
while(isdigit(inputs[i]))
word+=inputs[i++];
results[lexI++] = make_pair("number", word);
i--;
}
// <和<=号
else if(inputs[i]=='<'){
word=inputs[i++];
if(inputs[i]=='>'){
word+=inputs[i];
results[lexI++] = make_pair(words[word], word);
}
else if(inputs[i]=='='){
word+=inputs[i];
results[lexI++] = make_pair(words[word], word);
}
else if(inputs[i]!=' '||!isdigit(inputs[i])||!isalpha(inputs[i])){
results[lexI++] = make_pair(words[word], word);
}
else
{
cout<<"error!"<<endl;
}
i--;
}
// >和>=
else if(inputs[i]=='>'){
word=inputs[i++];
if(inputs[i]=='='){
word+=inputs[i];
results[lexI++] = make_pair(words[word], word);
}
else if(inputs[i]!=' '||!isdigit(inputs[i])||!isalpha(inputs[i])){
results[lexI++] = make_pair(words[word], word);
}
else{
cout<<"error!"<<endl;
}
i--;
}
//:=
else if(inputs[i]==':'){
word=inputs[i++];
if(inputs[i]=='='){
word+=inputs[i];
results[lexI++] = make_pair(words[word], word);
}else{
cout<<"error!"<<endl;
}
}
else{//其他的基本字
word=inputs[i];
it=words.find(word);
if(it!=words.end()){
results[lexI++] = make_pair(words[word], word);
}else{
cout<<"error!"<<endl;
}
}
}
}
struct quad{/**四元式的结构体**/
string result;
string arg1;
string arg2;
string op;
};
struct quad quad[50]; // 四元式数组
int quaI = 0; // 指向四元式的指针
void emit(string op, string arg1, string arg2, string result)//生成一行四元式
{
quad[quaI].op = op;
quad[quaI].arg1 = arg1;
quad[quaI].arg2 = arg2;
quad[quaI].result = result;
quaI++;
}
int i = 1; // 记录当前是t1/t2...t几了
string newT() //产生新变量名t1,t2等
{
stringstream ss;
ss << i;
string ti = "t" + ss.str();
i++;
return ti;
}
/**非算数表达式的递归下降分析及四元式生成**/
int sym=0; // 指示读入的符号
void advance() //用来读入下一个符号
{
++sym;
if(sym > lexI){
cout << "sym指针越界!";
exit(0);
}
}
string E1();
string F1()/*因子分析*/
{
string arg;
if(results[sym].first == "ident"){ //results的第一个string
arg = results[sym].second; //保存到results的第二个string里
advance();
}
else if(results[sym].first == "number"){//如果是无符号整数,最终返回相应的整数
arg = results[sym].second;
advance();
}
//如果是左括号,则要进行右括号匹配,并判断中间是不是表达式,并得出表达式的值进行返回
else if(results[sym].first == "lparen"){
advance();
arg = E1();
if(results[sym].first == "rparen"){
advance();
}
else{
cout << "未能匹配右括号!\n";
exit(0);
}
}
return arg;
}
string T1()/*项分析*/
{
string op, arg1, arg2, result;
arg1 = F1();//通过因子分析得到第一个参数的值
while(results[sym].first == "times" || results[sym].first == "slash")
{
op = results[sym].second;
advance();
arg2 = F1();//通过因子分析得到第二个参数的值
result = newT();//产生中间变量名,相当于对结果进行存储
emit(op, arg1, arg2, result);//产生四元式,相当于进行乘法或除法运算,得出结果
arg1 = result;//保存得到的结果
}
return arg1;//返回项最终得到的值
}
string E1()/*表达式分析*/
{
string op, arg1, arg2, result;
if(results[sym].first == "plus" || results[sym].first == "minus"){
advance();
}
arg1 = T1();//通过项分析得到第一个参数的值
while(results[sym].first == "plus" || results[sym].first == "minus"){
op = results[sym].second;
advance();
arg2 = T1();
result = newT();
emit(op, arg1, arg2, result);
arg1 = result;
}
return arg1;
}
/**算数表达式的递归下降分析及四元式生成**/
int E2();
int F2()
{
int arg=0;
if(results[sym].first == "ident"){
cout << "算数表达式含字母,无法计算!\n";
exit(0);
}
else if(results[sym].first == "number"){//如果 是数字,则返回相应的值
arg = atoi(results[sym].second.c_str());
advance();
}
//如果是左括号,则要进行右括号匹配,并判断中间是不是表达式,并得出表达式的值进行返回
else if(results[sym].first == "lparen"){
advance();
arg = E2();
if(results[sym].first == "rparen"){
advance();
}
else{
cout << "未能匹配右括号!\n";
exit(0);
}
}
return arg;
}
int T2()/*项分析*/
{
string op;
int arg1, arg2, result;
arg1 = F2();
while(results[sym].first == "times" || results[sym].first == "slash"){
op = results[sym].second;
advance();
arg2 = F2();
if(op == "*"){
result = arg1 * arg2;
arg1 = result;
}
else{
if(arg2 != 0){
result = arg1 / arg2;
arg1 = result;
}
else {
cout << "除数不能为0!\n";
exit(0);
}
}
}
return arg1;//返回该项所代表的值
}
int E2()/*表达式分析*/
{
string op;
int arg1, arg2, result;
if(results[sym].first == "plus" || results[sym].first == "minus"){
advance();
}
arg1 = T2();//通过项分析得到第一个参数的值
while(results[sym].first == "plus" || results[sym].first == "minus"){
op = results[sym].second;
advance();
arg2 = T2();//通过项分析得到第二个参数的值
if(op == "+"){
result = arg1 + arg2;
arg1 = result;
}
else{
result = arg1 - arg2;
arg1 = result;
}
}
return arg1;//返回该表达式所代表的值
}
int main()
{
Lexical_Analysis(); //词法分析
if(results[0].first == "number"){ //算术表达式
cout << E2();
}
else{
E1();
for(int i=0; i<quaI; i++){ //表达式 cout<<'('<<quad[i].op<<','<<quad[i].arg1<<','<<quad[i].arg2<<','<<quad[i].result<<')'<<endl;
}
}
return 0;
}
2.程序运行结果截图
测试数据一
:
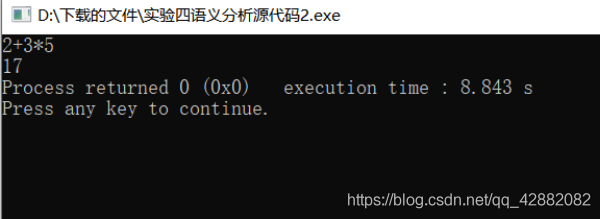
测试数据二
: