滴滴Kafka的使用规模应该算是在国内互联网领域里数一数二的企业,Kafka承载日增2PB的日志的流转和缓存,其下游要经受住100W + Producer同时写入数据,自身集群峰值可达 2000W/s,集群流量可达 30GB/s,集群中有2W+ topic、20+ cluster、单集群 370+ Broker,上游要对接3W+Consumer,最大数据消费可达600MB/s,面对这么大规模数据流转和分发虽然也会遇到因为Kafka磁盘IO热点导致的集群生产消费雪崩;或者因为Topic资源隔离差,流量突增、回溯消费,影响集群稳定性等问题,但终归还是满足了内部数据传输和交换的需求,助力企业过去9年业务高速发展,足以可见Kafka性能之强悍。
一、Kafka设计理念和演进思路
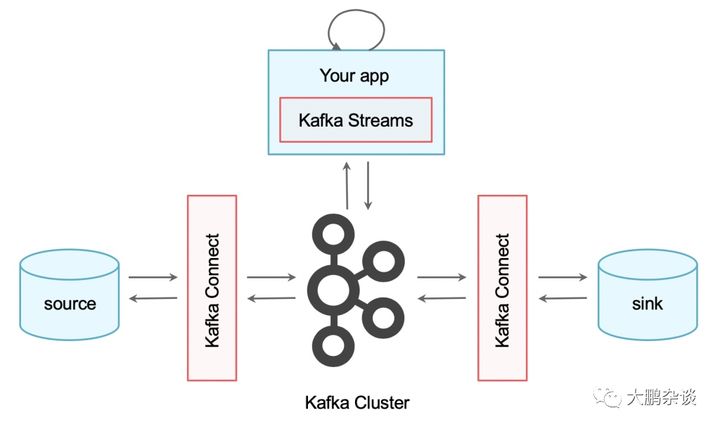
Kafka之所以在消息引擎方面性能如此出色,不得不说与其设计理念息息相关,Kafka在设计之初就旨在提供三个方面的特性:提供一套API实现生产者和消费者、降低网络传输和磁盘存储开销、实现高伸缩性架构,但Kafka并未止步于消息引擎,按照官方的说法现在Kafka即是消息引擎系统,也是一个分布式流处理平台(Apache Kafka is an open-source distributed event streaming platform)。
从2012年Kafka开源以来,短短3年间Kafka被越来越多的公司应用到他们企业内部的数据管道中,特别是在大数据工程领域,Kafka在承接上下游、串联数据流管道方面发挥了重要的作用:所有的数据几乎都要从一个系统流入Kafka然后再流入另一个系统中(Kafka Connect),这样的使用方式屡见不鲜以至于引发了Kafka社区的思考:与其把数据从一个系统传递到下一个系统中做处理,为何不自己实现一套流处理框架呢?基于这个考量,Kafka社区与0.10.0.0版本正式推出了流处理组件Kafka Streams,也正是从这个版本开始,Kafka正式“变身”为分布式的流处理平台,而不仅仅是消息引擎系统了,今天的Kafka是和Storm、Spark、Flink同等级的实时流处理平台。
二、从Kafka版本一窥未来趋势
Kafka目前总共演进了7个大版本,分别是0.7、0.8、0.9、0.10、0.11、1.0和2.0,每个大版本中又有很多小的Patch版本,像2.0大版本中,目前已经更新到2.8.0,期间历经了19个小版本。虽说有这么多版本更迭,实际上Kafka更新也是有几个大的里程碑。
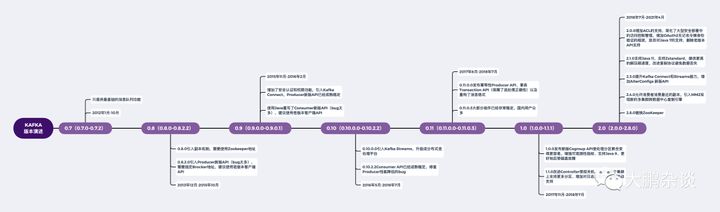
- Kafka从0.7演进到0.8之后正式引入副本机制,成为了一个真正意义上完备的分布式高可靠消息队列解决方案。有了副本备份机制,Kafka就解决了丢消息的问题。那时候生产和消费消息使用的还是老版本的客户端API,当你用它们的API开发生产者和消费者应用时,需要指定Zookeeper的地址而非broker的地址。但是由于其生产者API默认使用同步方式来发送消息,会造成吞吐量较低,所以大家通常会使用异步方式,但实际场景中可能会造成丢消息情况。坊间传闻的Kafka丢数据的出处之一;
- 2015年11月,社区正式发布了0.9.0.0版本,这个版本可以说算是Kafka非常友好的一个版本了,不仅增加了基础的安全认证和权限控制功能,同时还使用Java重写了新版本的Consumer API,另外还引入了Kafka Connect组件用于实现高性能的数据抽取,这个版本的Producer API已经非常稳定了;
- 2016年5月,社区正式发布了0.10.0.0版本,引入了Kafka Stream。从这个版本开始,Kafka从专注消息引擎正式升级为分布式流处理平台,此时的新版Consumer API已经成熟稳定,并且也修复Producer性能降低的bug,可以说此时的Kafka已经是一个非常成熟的消息引擎+无限想象空间的流处理平台;
- 2017年6月,社区正式发布了0.11.0.0版本,新增了幂等性Producer API、事务Transaction API(保障了流处理正确性)以及重构了消息格式,这个版本的Kafka算是早期最成熟的版本了,很多国内大中客户时至今日还都在使用这个版本;
- 2017年11月之后的1.0、2.0版本基本上都是在增强和优化KafkaSrream/KafkaConnect/KSQL的能力,要说最具里程碑的版本恐怕是2021年4月刚发布的2.8.0版本,摆脱了过去长期对ZooKeeper的依赖,目前Kafka看起来是已开始打造以自己为核心的大数据传输和计算生态了,但遗憾的是目前国内绝大多数用户都已经习惯Kafka+Flink的标配了,希望Kafka在未来能有所突围。
看到这么多不同的版本,我相信大家肯定会问一个问题,我应该在生产环境中使用哪个版本?我们的建议是对于新用户来说,可以选择比最新版本低2-3个小版本的,比如现在社区最新发布的是2.8.0,稳妥的做法就是可以选择2.5.0,对于很多生产环境已经使用了0.11.0.0这个版本的用户来说,强烈建议升级到0.11.0.3,这个版本已经被滴滴验证过很多次,非常稳定可靠。
三、Kafka带来的商业化新机遇
通过回顾Kafka版本可以发现其实每个版本都有它恰当的使用场景和独特的优缺点,事实上如果把Kafka应用在生产环节中,大家或多或少都会踩到一些坑,比如像国内好多在使用0.10.0.1这个版本,可能开始一切正常,但是随着生产环境数据量增加,就会时常出现进程假死,发生客户数据丢失这种情况,遇到这类情况普通用户通常很难定位问题根因,通常大家的做法就是冒着风险往上升版本,最终发现直到升级0.11.0.3这个版本才可以解决线程死锁的问题。
如果使用Kafka服务的是非生产系统或集群规模较小还比较容易升级,但是如果是7*24业务交易系统且集群规模庞大使用的Kafka版本众多,那简直就是灾难,很多用户根本就升不动,一方面是引擎本身的兼容性问题,另一方面业务方与其紧耦合,每次升级迁移都会大动干戈,根本没有尽头。
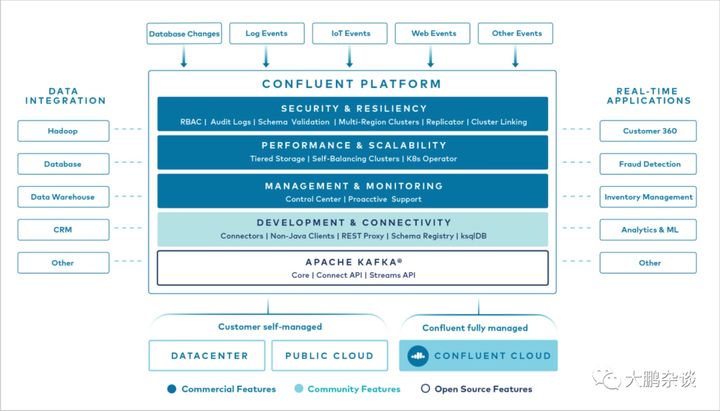
而Confluent正是看到了这个机遇,在原生Kafka的基础之上发布了自己的Confluent Kafka,提供了原生Kafka没有的一些高级特性,比如跨数据中心备份、Schema注册中心、REST proxy以及消息格式向前/向后兼容、集群监控等诸多增值功能。通过提供一站式服务完美解决Kafka版本兼容性以及隔离业务的问题。
四、国内开源新势力的崛起
不过由于Confluent暂时没有发展国内业务的计划,相关的资料和技术支持也都很欠缺,导致在国内的普及率比较低。而这也给国内的一些后起之秀提供了发展的时机和成长的土壤,像滴滴开源的
LogI-KafkaManager
(
https://
github.com/didi/kafka-m
anager
)便是其中的佼佼者,内部商业数据团队7年磨一剑,基于引擎级优化和内部最佳实践打造完全自主可控增强版Kafka,SLA承诺可达99.95%,帮助滴滴每年节省几百万IT支出。
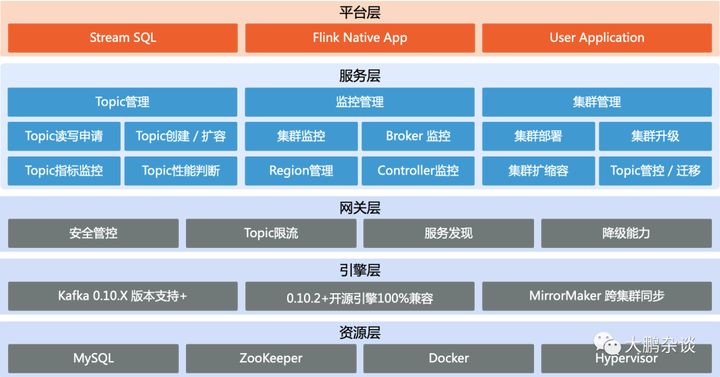
其平台基于用户、研发、运维不同视角的高频场景PaaS化,引擎基于2.5版本进行了40+特性增强,比如像磁盘过载保护,分区动态迁移,业务线程隔离等特性,全面向下兼容老版本平滑升级,GitHub上开源4个月就积累超过2400+Star,500+Fork,可见其在国内的受追捧热度有多高。
Kafka经过这么长时间不断的迭代,在消息引擎的地位早已坚若磐石,虽然说在流处理能力上从官方纰漏出来的数据显示已经不逊于Storm、Spark、Flink,但比较遗憾的是比起这些响当当的名字,国内鲜有大厂将Kafka用于流处理,毕竟Kafka是从消息引擎半路出家转型成为流处理平台的,它在流处理方面的表现还需要经过时间的检验。
如果把视角从流处理平台扩展到流处理生态圈,Kafka恐怕还有很长的路要走,而且最近在跟同事畅聊Kafka的未来发展方向时,普遍认为KSQL/KafkaStreaing 这套玩法会在K8S之上才会大放异彩,让我们拭目以待。
滴滴云Obsuite
混合云可观测性中台,包含滴滴夜莺(Nightingale) 、滴滴Logi,有开源、企业版,利用指标、日志分析手段,提供覆盖资源、应用、业务的多层次监控和分析服务,为业务稳定性建设和运营方向决策提供强力支持。
Obsuite从metrics、log、trace三个方向着手,由
滴滴夜莺
和
滴滴Logi
两个产品组成。
滴滴Logi
滴滴Logi日志服务套件在滴滴内部经过7年多的沉淀打磨,针对日志采集、日志存储、日志计算、日志检索、日志分析各个环节,在组件能力上PAAS化建设、在引擎稳定性与扩展性上进行了针对性的优化。
目前该套件已经开源了滴滴Logi-KafkaManager,后期还会陆续开源Logi-Agent、Logi-LogX、Logi-ElasticSearchManager各PAAS套件。
1、滴滴Logi-KafkaManager Github:
https://
z.didi.cn/4newP
2、快速体验地址:
http://
117.51.150.133:8080/kaf
ka
账号密码 admin/admin
3、日常FAQ:
https://
github.com/didi/Logi-Ka
fkaManager/blob/master/docs/user_guide/faq.md
4、升级手册:
https://
github.com/didi/Logi-Ka
fkaManager/tree/master/docs/dev_guide/upgrade_manual
5、滴滴Logi-KafkaManager云平台建设总结:
https://
mp.weixin.qq.com/s/9qSZ
IkqCnU6u9nLMvOOjIQ
6、系列视频教程:
https://
mp.weixin.qq.com/s/9X7g
H0tptHPtfjPPSdGO8g
滴滴夜莺
滴滴夜莺是一套
分布式高可用
的运维监控系统,最大的特点是混合云支持,既可以支持传统物理机虚拟机的场景,也可以支持K8S容器的场景。同时,滴滴夜莺也不只是监控,还有一部分CMDB的能力、自动化运维的能力,很多公司都基于夜莺开发自己公司的运维平台。
Github:
https://
z.didi.cn/4WurZ
官方文档:
https://
n9e.didiyun.com
提问必读:
https://
gocn.vip/topics/10811
语音答疑:
https://
m.ximalaya.com/keji/450
95827/
视频教程:
https://
m.bilibili.com/space/44
2531657
二次开发:
https://
xie.infoq.cn/article/30
d37e98fbe52ff2a79fc04b4
如果大家在使用滴滴Logi-KafkaManager和夜莺的过程中出现问题,或者有疑问需要与开发者交流的,都可以扫描下方二维码进入滴滴Logi及夜莺的开源用户群,在群中提问。
群内有滴滴Logi-KafkaManager和夜莺项目负责人:滴滴高级专家工程师—张亮、秦晓辉等技术大咖,在线为大家解答问题
,欢迎大家长按二维码加小助手进群。(需备注Kafka或夜莺)
