SVM系列目录:
支持向量机SVM③——通过4种核函数进行波斯顿房价回归预测
支持向量机SVM②——文本分类实战(SVM&KNN&贝叶斯&决策树)
本来想先写一篇支持向量机的原理篇,结果在白天钻研,晚上做梦都在思考的2周后,还是没有搞太明白,实在是见识到了人类智慧的博大精深和自我的渺小。因此我还是先从应用下手,先用到慢慢体会好了。本篇主要介绍sklearn库的svm的分类和回归参数,其中重点介绍四大核函数的参数。
之前在未调参的情况下将svm和决策树、贝叶斯进行了分类对比,发现训练器分数巨低,且训练过程时间是真的长,长到怀疑人生。所以想要SVM用得好,会调参真的是很重要,很重要,很重要!!!(
文末有大礼赠送
)
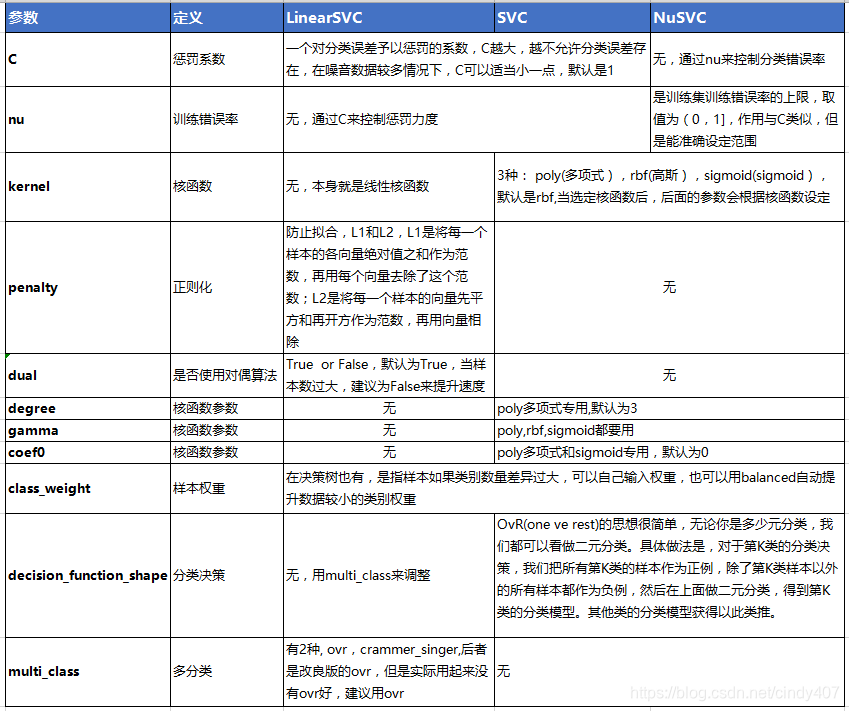
一、分类
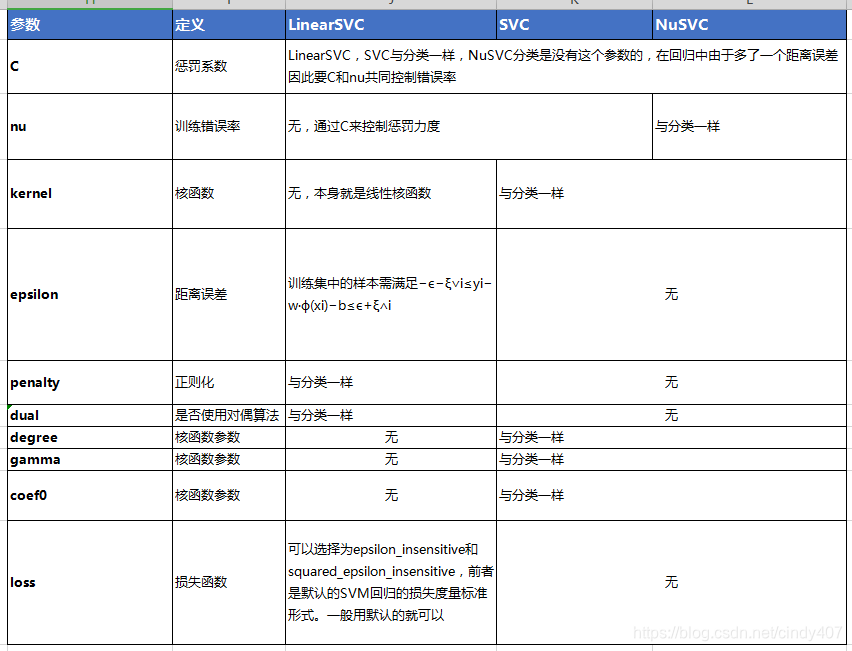
二、回归
SVM回归算法库的重要参数大部分和分类算法库类似,因此这里重点讲述和分类算法库不同的部分
三、参数注意事项
①对训练数据和测试数据最好都做归一化
②如果特征非常多,或者样本数远少于特征数时,数据更偏向线性可分,用线性核函数效果就会很好
③优先选择线性核函数,如果拟合不好同,再推荐默认的高斯(rbf),因为高斯需要通过交叉验证选择适合的惩罚系数C和gamma
④理论上高斯不会比线性核差,但是高斯需要花非常多的时间在调参上,实际业务中能用线性就用线性
四、GridSearchCV调参实例
① 用sklearn数据生成器生成特征数为2的圆环型数据
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm,datasets
from sklearn.svm import SVC
from sklearn.datasets import make_moons,make_circles,make_classification
X, y = make_circles(noise=0.2, factor=0.5, random_state=1) # make_circles是环形,noise是加一点噪音,factor是两个圆形的距离
from sklearn.preprocessing import StandardScaler
X = StandardScaler().fit_transform(X) # StandardScaler