在机器视觉中注意力机制运用非常广泛,将较为经典的几种注意力机制进行整理。
Se-Net
SENet设计的目的是让模型可以更加关注每个通道的贡献,思路是将每一个通道的所有元素看成一个独立的权重,通过平均池化后接入多层感知机,最终输出每个通道对应的权重。Se-Net的流程图如图1所示,输出的注意力为每个通道分配[0,1]的权重,最终完成加权操作。
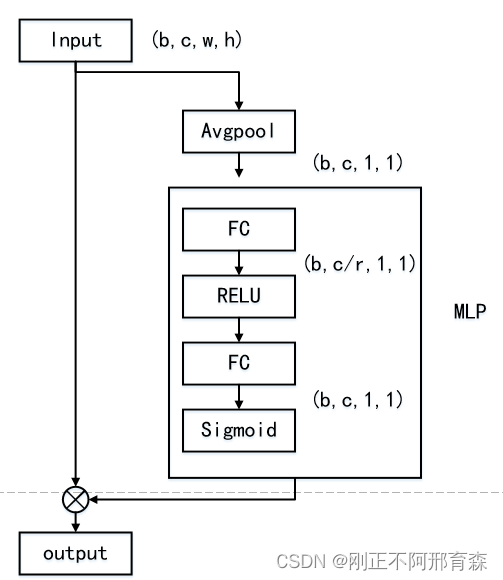
图1
CBAM
CBAM相比于Se-Net,除了在通道域进行加权在空间域也进行了加权操作,注意力可以从两个不同角度来进行指导模型。通道注意力CA和空间注意力SA以串联的形式构成最终的CBAM。CA和SA 流程图如图2所示。
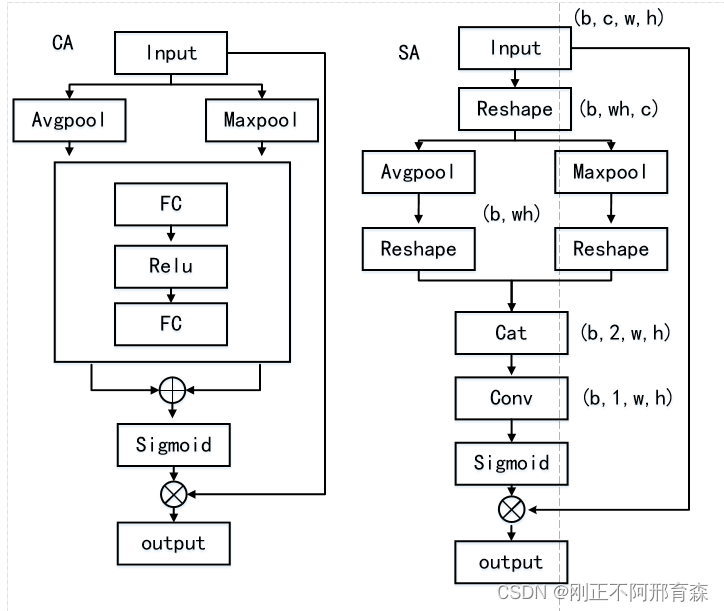
图2
Non-Local
Non-local的核心思想为特征图中的每一个点都与其它点有关联,通过构建相似度矩阵,与原图相关映射得到最终的加权矩阵,流程图如图3所示。
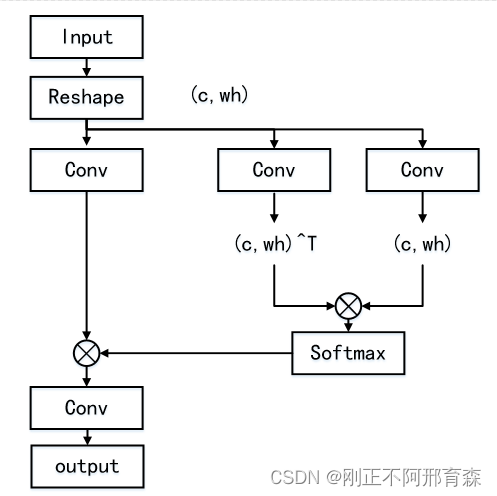
图3
CCA
CCA是一种在空域上的注意力机制,与CBAM的对通道进行最大池化和均值池化不同,CCA使用方差和均值作为自变量来生成注意力,通过对特征图中每个像素进行求解方差后与均值相加,然和输入到多层感知机中最终得到注意力,流程图如图4所示。
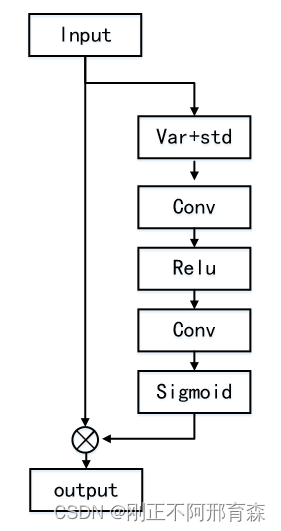
图4
EMA
ESA本质上是Non-local的优化版本,相比于传统的non-local使用了下采样加上采样的操作,来建立单个像素与其它像素更加密切的联系。流程图如图5所示。
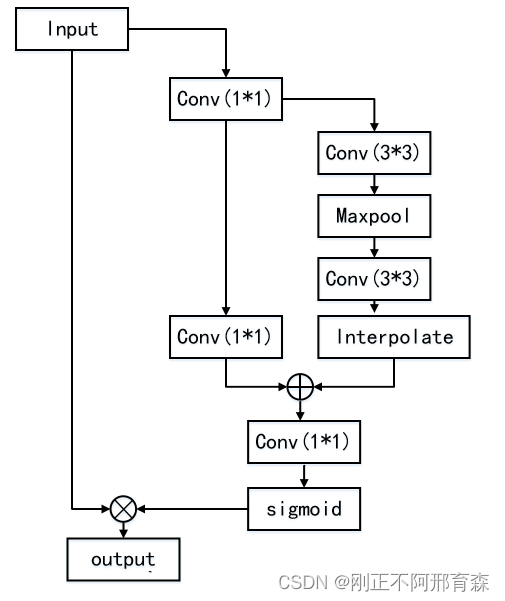
图5
版权声明:本文为crazysmoker原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。